http://open-source-security-software.net/organization/Facebook/releases.atomRecent releases for Facebook2024-05-16T15:51:03.517393+00:00python-feedgenzstd zstd-0.4.2zstd zstd-0.4.22015-12-02T14:33:40+00:00Generic minor improvements for small blocks
Fixed : big-endian compatibility, by @peterh (#85)
2015-12-02T14:33:40+00:00zstd v0.4.3zstd v0.4.32015-12-07T10:13:04+00:00- External dictionary mode (API only)
- zstd-frugal : small-size binary
2015-12-07T10:13:04+00:00zstd v0.4.4zstd v0.4.42015-12-14T12:49:10+00:00Fixed : high compression modes for Windows 32 bits
new : external dictionary API : direct and buffered mode, accessible through command line (`-D`)
new : Visual DLL project, thanks to @KrzysFR
2015-12-14T12:49:10+00:00zstd v0.4.5zstd v0.4.52015-12-18T03:00:18+00:00Added : Command line : `-m` : compress / decompress multiple files. wildcard `*` support.
2015-12-18T03:00:18+00:00zstd v0.4.6zstd v0.4.62016-01-12T23:48:50+00:00fix : fast compression mode on Windows
New : cmake configuration file, thanks to @mailagentrus
Improved : high compression mode on repetitive data
New : block-level API
New : Duplicate context for faster dictionary compression
Changed : ZSTD_decompress() uses heap memory by default (can be changed back to stack with #define)
2016-01-12T23:48:50+00:00zstd v0.4.7zstd v0.4.72016-01-22T12:15:48+00:00Improved : small compression speed improvement in HC mode
Changed : `zstd_decompress.c` starts with ZSTD_LEGACY_SUPPORT set to 0 by default
2016-01-22T12:15:48+00:00zstd v0.5.0zstd v0.5.02016-02-05T15:35:04+00:00New : Dictionary builder tool
Changed : Advanced API for streaming and dictionary compression
Improved : better compression of small data
2016-02-05T15:35:04+00:00zstd v0.5.1zstd v0.5.12016-02-18T11:08:04+00:00- New : Optimal parsing => Very high compression modes, thanks to @inikep
- Changed : Dictionary builder integrated into libzstd and zstd cli
- Changed (!) : zstd cli now uses "multiple input files" as default mode. See `zstd -h`.
- Fix : high compression modes for big-endian platforms (#123)
- New : zstd cli : `-t` | `--test` command
2016-02-18T11:08:04+00:00zstd v0.6.0zstd v0.6.02016-04-12T23:31:58+00:00Stronger high compression modes, thanks to @inikep
Changed : highest compression modes require `--ultra` command to remove memory restrictions
API : `ZSTD_getFrameParams()` provides size of decompressed content
Fixed : zstd cli return error code > 0 and removes dst file artifact when decompression fails, thanks to Chip Turner
Various fixes and small performance improvements
2016-04-12T23:31:58+00:00zstd v0.6.1zstd v0.6.12016-05-13T12:04:56+00:00New : zlib wrapper API, thanks to @inikep
New : Ability to compile compressor / decompressor separately
Changed : new lib directory structure
Fixed : Legacy codec v0.5 compatible with dictionary decompression
Fixed : Decoder corruption error (#173)
Fixed : null-string roundtrip (#176)
New : benchmark mode can select directory as input
Experimental : midipix support, VMS support
2016-05-13T12:04:56+00:00zstd v0.7.1zstd v0.7.12016-06-23T08:16:44+00:00v0.7.1
fixed : `ZBUFF_compressEnd()` called multiple times with too small `dst` buffer, reported by @KrzysFR
fixed : dictBuilder fails if first sample is too small, reported by @velavokr
fixed : corruption issue, reported by cj
modified : frame checksum enabled by default in command line mode (can be disabled with `--no-check`)
fixed : cli breaks during destination file overwrite confirmation
v0.7.0
**Candidate compression format**
New : Support for directory compression, using `-r`, thanks to @inikep
New : Command `--rm`, to remove source file after successful de/compression
New : Visual build scripts, by @KrzysFR
New : Support for Sparse File-systems (do not use space for zero-filled sectors)
New : Frame checksum support
New : Support pass-through mode (when using `-df`)
API : more efficient Dictionary API : `ZSTD_compress_usingCDict()`, `ZSTD_decompress_usingDDict()`
API : create dictionary files from custom content, by @ot
API : support for custom malloc/free functions
New : controllable Dictionary ID
New : Support for skippable frames
Changed : removed `zstd_static.h`, now replaced by a `#define ZSTD_STATIC_LINKING_ONLY` before `#include zstd.h`. Same logic for all others `*_static.h`.
2016-06-23T08:16:44+00:00zstd v0.7.2zstd v0.7.22016-07-03T19:10:49+00:00fixed : ZSTD_decompressBlock() using multiple consecutive blocks. Reported by @GregSlazinski
fixed : potential segfault on very large files (many gigabytes). Reported by @chipturner
fixed : CLI displays system error message when destination file cannot be created (#231). Reported by @chipturner
fixed : leak in some fail scenario in dictionary builder, reported by @nemequ
2016-07-03T19:10:49+00:00zstd v0.7.3zstd v0.7.32016-07-08T19:33:59+00:00New : compression format specification `zstd_compression_format.md`
New : `--` separator, stating that all following arguments are file names. Suggested by @chipturner
New : `ZSTD_getDecompressedSize()`
New : OpenBSD target, by @juanfra684
New : `examples` directory
fixed : dictBuilder using HC levels, reported by Bartosz Taudul
fixed : legacy support from `ZSTD_decompress_usingDDict()`, reported by Felix Handte
fixed : multi-blocks decoding with intermediate uncompressed blocks, reported by @GregSlazinski
modified : removed "mem.h" and "error_public.h" dependencies from "zstd.h" (experimental section)
modified : legacy functions no longer need magic number
2016-07-08T19:33:59+00:00zstd v0.7.4zstd v0.7.42016-07-16T18:19:10+00:00Modified : default compression level is now **3** for CLI
Added : homebrew for Mac, by @cadedaniel
Fixed : segfault when using small dictionaries, reported by Felix Handte
Added : more examples
Updated : specification, to v0.1.1
2016-07-16T18:19:10+00:00zstd v0.7.5zstd v0.7.52016-08-01T12:28:38+00:00Same as v0.7.4
with added ability to decode v0.8x streams (forward compatibility)
2016-08-01T12:28:38+00:00zstd v0.6.2zstd v0.6.22016-08-02T12:04:14+00:00Same as v0.6.1
with added ability to decode v0.7x and v0.8x streams (forward compatibility)
2016-08-02T12:04:14+00:00zstd v0.8.0zstd v0.8.02016-08-02T13:57:17+00:00**Final compression format**
Improved : better speed on clang and gcc -O2, thanks to @ebiggers
New : Build on FreeBSD and DragonFly, thanks to @jrmarino
Changed : modified API : ZSTD_compressEnd()
Fixed : legacy mode with ZSTD_HEAPMODE=0, by @gymdis
Fixed : premature end of frame when zero-sized raw block, reported by @ebiggers
Fixed : large dictionaries (> 384 KB), reported by Ilona Papava
Fixed : checksum correctly checked in single-pass mode
Fixed : combined --test amd --rm, reported by @amnilsson
Modified : minor compression level adaptations
Updated : compression format specification to v0.2.0
changed : zstd.h moved to /lib directory
2016-08-02T13:57:17+00:00zstd v0.8.1zstd v0.8.12016-08-18T15:08:01+00:00New streaming API
Changed : --ultra now enables levels beyond 19
Changed : -i# now selects benchmark time in second
Fixed : ZSTD_compress\* can now compress > 4 GB in a single pass, reported by Nick Terrell
Fixed : speed regression on specific patterns (#272)
Fixed : support for Z_SYNC_FLUSH, by @dak-evanti-ru (#291)
Fixed : ICC compilation, by @inikep
2016-08-18T15:08:01+00:00zstd v1.0.0zstd v1.0.02016-08-31T16:10:23+00:00Change Licensing, all project is now BSD, copyright Facebook
Added Patent Grant
Small decompression speed improvement
API : Streaming API supports legacy format
API : New : ZDICT_getDictID(), ZSTD_sizeof_{CCtx, DCtx, CStream, DStream}(), ZSTD_setDStreamParamter()
CLI supports legacy formats v0.4+
Fixed : compression fails on certain huge files, reported by Jesse McGrew
Enhanced documentation, by @inikep
2016-08-31T16:10:23+00:00zstd v1.1.0zstd v1.1.02016-09-28T03:18:33+00:00New : **pzstd** , parallel version of zstd, by @terrelln
added : NetBSD install target (#338)
Improved : speed for batches of small files
Improved : speed of zlib wrapper, by @inikep
Changed : libzstd on Windows supports legacy formats, by @KrzysFR
Fixed : CLI -d output to stdout by default when input is stdin (#322)
Fixed : CLI correctly detects console on Mac OS-X
Fixed : CLI supports recursive mode -r on Mac OS-X
Fixed : Legacy decoders use unified error codes, reported by benrg (#341), fixed by @inikep
Fixed : compatibility with OpenBSD, reported by@juanfra684 (#319)
Fixed : compatibility with Hurd, by @inikep (#365)
Fixed : zstd-pgo, reported by @octoploid (#329)
2016-09-28T03:18:33+00:00zstd v1.1.1zstd v1.1.12016-11-02T04:06:40+00:00New : cli commands `-M#`, `--memory=`, `--memlimit=`, `--memlimit-decompress=` to limit allowed memory consumption during decompression
New : doc/zstd_manual.html, by @inikep
Improved : slightly better compression ratio at `--ultra` levels (>= 20)
Improved : better memory usage when using streaming compression API, thanks to @Rogier-5 report
Added : API : `ZSTD_initCStream_usingCDict()`, `ZSTD_initDStream_usingDDict()` (experimental section)
Added : `examples/multiple_streaming_compression.c`
Changed : `zstd_errors.h` is now installed within `/include` (and replaces `errors_public.h`)
Updated man page
Fixed : several sanitizer warnings, by @terrelln
Fixed : `zstd-small`, `zstd-compress` and `zstd-decompress` compilation targets
2016-11-02T04:06:40+00:00zstd v1.1.2zstd v1.1.22016-12-15T08:00:35+00:00**new** : programs/**gzstd** , combined `*.gz` and `*.zst` decoder, by @inikep
**new** : zstdless, less on compressed `*.zst` files
**new** : zstdgrep, grep on compressed `*.zst` files
fixed : zstdcat
cli : new : preserve file attributes
cli : fixed : status displays total amount decoded, even for file consisting of multiple frames (like pzstd)
lib : improved : faster decompression speed at ultra compression settings and 32-bits mode
lib : changed : only public ZSTD_ symbols are now exposed in dynamic library
lib : changed : reduced usage of stack memory
lib : fixed : several corner case bugs, by @terrelln
API : streaming : decompression : changed : automatic implicit reset when chain-decoding new frames without init
API : experimental : added : dictID retrieval functions, and ZSTD_initCStream_srcSize()
API : zbuff : changed : prototypes now generate deprecation warnings
zlib_wrapper : added support for gz\* functions, by @inikep
install : better compatibility with FreeBSD, by @DimitryAndric
source tree : changed : zbuff source files moved to lib/deprecated
2016-12-15T08:00:35+00:00zstd v1.1.3zstd v1.1.32017-02-06T17:19:09+00:00cli : zstd can decompress .gz files (can be disabled with `make zstd-nogz` or `make HAVE_ZLIB=0`)
cli : new : experimental target `make zstdmt`, with multi-threading support
cli : new : improved dictionary builder "cover" (experimental), by @terrelln, based on previous work by @ot
cli : new : advanced commands for detailed parameters, by @inikep
cli : fix zstdless on Mac OS-X, by @apjanke
cli : fix #232 "compress non-files"
API : new : `lib/compress/ZSTDMT_compress.h` multithreading API (experimental)
API : new : `ZSTD_create?Dict_byReference()`, requested by Bartosz Taudul
API : new : `ZDICT_finalizeDictionary()`
API : fix : `ZSTD_initCStream_usingCDict()` properly writes dictID into frame header, by @indygreg (#511)
API : fix : all symbols properly exposed in libzstd, by @terrelln
build : support for Solaris target, by @inikep
doc : clarified specification, by @iburinoc
Sample set for reference dictionary compression benchmark
=============================================
```
# Download and expand sample set
wget https://github.com/facebook/zstd/releases/download/v1.1.3/github_users_sample_set.tar.zst
zstd -d github_users_sample_set.tar.zst
tar xf github_users_sample_set.tar
```
```
# benchmark sample set with and without dictionary compression
zstd -b1 -r github
zstd --train -r github
zstd -b1 -r github -D dictionary
```
```
# rebuild sample set archive
tar cf github_users_sample_set.tar github
zstd -f --ultra -22 github_users_sample_set.tar
```
2017-02-06T17:19:09+00:00zstd v1.1.4zstd v1.1.42017-03-17T21:33:25+00:00cli : new : can compress in `*.gz` format, using `--format=gzip` command, by @inikep
cli : new : advanced benchmark command `--priority=rt`
cli : fix : write on sparse-enabled file systems in 32-bits mode, by @ds77
cli : fix : `--rm` remains silent when input is stdin
cli : experimental `xzstd` target, with support for xz/lzma decoding, by @inikep
speed : improved decompression speed in streaming mode for single pass scenarios (+5%)
memory : DDict (decompression dictionary) memory usage down from 150 KB to 20 KB
arch : 32-bits variant able to generate and decode very long matches (>32 MB), by @iburinoc
API : new : `ZSTD_findFrameCompressedSize()`, `ZSTD_getFrameContentSize()`, `ZSTD_findDecompressedSize()`
API : changed : dropped support of legacy versions <= v0.3 (can be selected by modifying `ZSTD_LEGACY_SUPPORT` value)
build: new: meson build system in contrib/meson, by @dimkr
build: improved cmake script, by @Majlen
build: added `-Wformat-security` flag, as recommended by @pixelb
doc : new : `doc/educational_decoder`, by @iburinoc
__Warning__ : the experimental target `zstdmt` contained in this release has an issue when using multiple threads on large enough files, which makes it generate buggy header. While fixing the header after the fact is possible, it's much better to avoid the issue. This can be done by using `zstdmt` in pipe mode :
`cat file | zstdmt -T2 -o file.zst`
This issue is fixed in current `dev` branch, so alternatively, create `zstdmt` from `dev` branch.
_Note_ : pre-compiled Windows binaries attached below contain the fix for `zstdmt`2017-03-17T21:33:25+00:00zstd v1.2.0zstd v1.2.02017-05-04T18:23:23+00:00Major features :
- Multithreading is enabled by default in the cli. Use `-T#` to select nb of thread. To disable multithreading, build target `zstd-nomt` or compile with `HAVE_THREAD=0`.
- New dictionary builder named "cover" with improved quality (produces better compression ratio), by @terrelln. Legacy dictionary builder remains available, using `--train-legacy` command.
Other changes :
cli : new : command `-T0` means "detect and use nb of cores", by @iburinoc
cli : new : `zstdmt` symlink hardwired to `zstd -T0`
cli : new : command `--threads=#` (#671)
cli : new : commands `--train-cover` and `--train-legacy`, to select dictionary algorithm and parameters
cli : experimental targets `zstd4` and `xzstd4`, supporting lz4 format, by @iburinoc
cli : fix : does not output compressed data on console
cli : fix : ignore symbolic links unless `--force` specified,
API : breaking change : `ZSTD_createCDict_advanced()` uses `compressionParameters` as argument
API : added : prototypes `ZSTD_*_usingCDict_advanced()`, for direct control over `frameParameters`.
API : improved: `ZSTDMT_compressCCtx()` reduced memory usage
API : fix : `ZSTDMT_compressCCtx()` now provides `srcSize` in header (#634)
API : fix : src size stored in frame header is controlled at end of frame
API : fix : enforced consistent rules for `pledgedSrcSize==0` (#641)
API : fix : error code `GENERIC` replaced by `dstSizeTooSmall` when appropriate
build: improved cmake script, by @Majlen
build: enabled Multi-threading support for *BSD, by @bapt
tools: updated `paramgrill`. Command `-O#` provides best parameters for sample and speed target.
new : `contrib/linux-kernel` version, by @terrelln 2017-05-04T18:23:23+00:00zstd v1.3.0zstd v1.3.02017-07-05T18:05:54+00:00cli : new : `--list` command, by @paulcruz74
cli : changed : xz/lzma support enabled by default
cli : changed : `-t *` continue processing list after a decompression error
API : added : `ZSTD_versionString()`
API : promoted to stable status : `ZSTD_getFrameContentSize()`, by @iburinoc
API exp : **new advanced API** : `ZSTD_compress_generic()`, `ZSTD_CCtx_setParameter()`
API exp : new : API for static or external allocation : `ZSTD_initStatic?Ctx()`
API exp : added : `ZSTD_decompressBegin_usingDDict()`, requested by @Crazee (#700)
API exp : clarified memory estimation / measurement functions.
API exp : changed : strongest strategy renamed `ZSTD_btultra`, fastest strategy `ZSTD_fast` set to 1
Improved : reduced stack memory usage, by @terrelln and @stellamplau
tools : decodecorpus can generate random dictionary-compressed samples, by @paulcruz74
new : contrib/seekable_format, demo and API, by @iburinoc
changed : contrib/linux-kernel, updated version and license, by @terrelln 2017-07-05T18:05:54+00:00zstd v1.3.1zstd v1.3.12017-08-20T19:37:00+00:00- **New license** : BSD + GPLv2
- perf: substantially decreased memory usage in Multi-threading mode, thanks to reports by Tino Reichardt (@mcmilk)
- perf: Multi-threading supports up to 256 threads. Cap at 256 when more are requested (#760)
- cli : improved and fixed `--list` command, by @ib (#772)
- cli : command `-vV` lists supported formats, by @ib (#771)
- build : fixed binary variants, reported by @svenha (#788)
- build : fix Visual compilation for non x86/x64 targets, reported by @GregSlazinski (#718)
- API exp : breaking change : `ZSTD_getframeHeader()` provides more information
- API exp : breaking change : pinned down values of error codes
- doc : fixed huffman example, by Ulrich Kunitz (@ulikunitz)
- new : `contrib/adaptive-compression`, I/O driven compression level, by Paul Cruz (@paulcruz74)
- new : `contrib/long_distance_matching`, statistics tool by Stella Lau (@stellamplau)
- updated : `contrib/linux-kernel`, by Nick Terrell (@terrelln)2017-08-20T19:37:00+00:00zstd fuzz-corporazstd fuzz-corpora2017-09-22T23:16:48+00:00Zstandard Fuzz Corpora2017-09-22T23:16:48+00:00zstd v1.3.2zstd v1.3.22017-10-09T23:31:00+00:00# Zstandard Long Range Match Finder
Zstandard has a new long range match finder written by our intern Stella Lau (@stellamplau), which specializes on finding long matches in the distant past. It integrates seamlessly with the regular compressor, and the output can be decompressed just like any other Zstandard compressed data.
The long range match finder adds minimal overhead to the compressor, works with any compression level, and maintains Zstandard's blazingly fast decompression speed. However, since the window size is larger, it requires more memory for compression and decompression.
To go along with the long range match finder, we've increased the maximum window size to 2 GB. The decompressor only accepts window sizes up to 128 MB by default, but `zstd -d --memory=2GB` will decompress window sizes up to 2 GB.
## Example usage
```
# 128 MB window size
zstd -1 --long file
zstd -d file.zst
# 2 GB window size (window log = 31)
zstd -6 --long=31 file
zstd -d --long=31 file.zst
# OR
zstd -d --memory=2GB file.zst
```
```c
ZSTD_CCtx *cctx = ZSTD_createCCtx();
ZSTD_CCtx_setParameter(cctx, ZSTD_p_compressionLevel, 19);
ZSTD_CCtx_setParameter(cctx, ZSTD_p_enableLongDistanceMatching, 1); // Sets windowLog=27
ZSTD_CCtx_setParameter(cctx, ZSTD_p_windowLog, 30); // Optionally increase the window log
ZSTD_compress_generic(cctx, &out, &in, ZSTD_e_end);
ZSTD_DCtx *dctx = ZSTD_createDCtx();
ZSTD_DCtx_setMaxWindowSize(dctx, 1 << 30);
ZSTD_decompress_generic(dctx, &out, &in);
```
## Benchmarks
We compared the zstd long range matcher to zstd and [lrzip](https://github.com/ckolivas/lrzip). The benchmarks were run on an AMD Ryzen 1800X (8 cores with 16 threads at 3.6 GHz).
### Compressors
* zstd — The regular Zstandard compressor.
* zstd 128 MB — The Zstandard compressor with a 128 MB window size.
* zstd 2 GB — The Zstandard compressor with a 2 GB window size.
* lrzip xz — The lrzip compressor with default options, which uses the xz backend at level 7 with 16 threads.
* lrzip xz single — The lrzip compressor with a single-threaded xz backend at level 7.
* lrzip zstd — The lrzip compressor without a backend, then its output is compressed by zstd (not multithreaded).
### Files
* Linux 4.7 - 4.12 — This file consists of the uncompressed tarballs of the six Linux kernel release from 4.7 to 4.12 concatenated together in order. This file is extremely compressible if the compressor can match against the previous versions well.
* Linux git — This file is a tarball of the linux repo, created by `git clone https://github.com/torvalds/linux && tar -cf linux-git.tar linux/`. This file gets a small benefit from long range matching. This file shows how the long range matcher performs when there isn't too many matches to find.
### Results
Both zstd and zstd 128 MB don't have large enough of a window size to compress Linux 4.7 - 4.12 well. zstd 2 GB compresses the fastest, and slightly better than lrzip-zstd. lrzip-xz compresses the best, and at a reasonable speed with multithreading enabled. The place where zstd shines is decompression ease and speed. Since it is just regular Zstandard compressed data, it is decompressed by the highly optimized decompressor.
The Linux git file shows that the long range matcher maintains good compression and decompression speed, even when there are far less long range matches. The decompression speed takes a small hit because it has to look further back to reconstruct the matches.
Compression Ratio vs Speed | Decompression Speed
---------------------------|--------------------
 | 
 | 
## Implementation details
The long distance match finder was inspired by great work from Con Kolivas' [lrzip](http://ck.kolivas.org/apps/lrzip/README.md), which in turn was inspired by Andrew Tridgell's [rzip](https://rzip.samba.org/). Also, let's mention Bulat Ziganshin's [srep](https://encode.ru/threads/43-FreeArc?highlight=srep), which we have not been able to test unfortunately (site down), but the discussions on [encode.ru](https://encode.ru/forums/2-Data-Compression) proved great sources of inspiration.
Therefore, many similar mechanisms are adopted, such as using a [rolling hash](https://en.wikipedia.org/wiki/Rolling_hash), and filling a [hash table](https://en.wikipedia.org/wiki/Hash_table) divided into buckets of entries.
That being said, we also made different choices, with the goal to favor speed, as can be observed in benchmark. The rolling hash formula is selected for computing efficiency. There is a restrictive insertion policy, which only inserts candidates that respect a mask condition. The insertion policy allows us to skip the hash table in the common case that a match isn't present. Confirmation bits are saved, to only check for matches when there is a strong presumption of success. These and a few more details add up to make zstd's long range matcher a speed-oriented implementation.
The biggest difference though is that the long range matcher is blended into the regular compressor, producing a single valid zstd frame, undistinguishable from normal operation (except obviously for the larger window size). This makes decompression a single pass process, preserving its speed property.
More details are available directly in source code, at [lib/compress/zstd_ldm.c](https://github.com/facebook/zstd/blob/master/lib/compress/zstd_ldm.c).
## Future work
This is a first implementation, and it still has a few limitations, that we plan to lift in the future.
The long range matcher doesn't interact well with multithreading. Due to the way zstd multithreading is currently implemented, memory usage will scale with the window size times the number of threads, which is a problem for large window sizes. We plan on supporting multithreaded long range matching with reasonable memory usage in a future version.
Secondly, Zstandard is currently limited to a 2 GB window size because of indexer's design. While this is a significant update compared to previous 128 MB limit, we believe this limitation can be lifted altogether, with some structural changes in the indexer. However, it also means that window size would become really big, with knock-off consequences on memory usage. So, to reduce this load, we will have to consider memory map as a complementary way to reference past content in the uncompressed file.
# Detailed list of changes
- new : __long range mode__, using `--long` command, by Stella Lau (@stellamplau)
- new : ability to generate and decode magicless frames (#591)
- changed : maximum nb of threads reduced to 200, to avoid address space exhaustion in 32-bits mode
- fix : multi-threading compression works with custom allocators, by @terrelln
- fix : a rare compression bug when compression generates very large distances and bunch of other conditions (only possible at `--ultra -22`)
- fix : 32-bits build can now decode large offsets (levels 21+)
- cli : added LZ4 frame support by default, by Felix Handte (@felixhandte)
- cli : improved `--list` output
- cli : new : can split input file for dictionary training, using command `-B#`
- cli : new : clean operation artefact on Ctrl-C interruption (#854)
- cli : fix : do not change /dev/null permissions when using command `-t` with root access, reported by @mike155 (#851)
- cli : fix : write file size in header in multiple-files mode
- api : added macro `ZSTD_COMPRESSBOUND()` for static allocation
- api : experimental : new advanced decompression API
- api : fix : `sizeof_CCtx()` used to over-estimate
- build: fix : compilation works with `-mbmi` (#868)
- build: fix : no-multithread variant compiles without `pool.c` dependency, reported by Mitchell Blank Jr (@mitchblank) (#819)
- build: better compatibility with reproducible builds, by Bernhard M. Wiedemann (@bmwiedemann) (#818)
- example : added `streaming_memory_usage`
- license : changed /examples license to BSD + GPLv2
- license : fix a few header files to reflect new license (#825)
## Warning
bug #944 : `v1.3.2` is known to produce corrupted data in the following scenario, requiring all these conditions simultaneously :
- compression using multi-threading
- with a dictionary
- on "large enough" files (several MB, exact threshold depends on compression level)
Note that dictionary is meant to help compression of small files (a few KB), while multi-threading is only useful for large files, so it's pretty rare to need both at the same time. Nonetheless, if your application happens to trigger this situation, it's recommended to skip `v1.3.2` for a newer version. At the time of this warning, the `dev` branch is known to work properly for the same scenario.2017-10-09T23:31:00+00:00zstd v1.3.3zstd v1.3.32017-12-21T09:25:55+00:00This is bugfix release, mostly focused on cleaning several detrimental corner cases scenarios.
It is nonetheless a recommended upgrade.
### Changes Summary
- perf: improved `zstd_opt` strategy (levels 16-19)
- fix : bug #944 : multithreading with shared ditionary and large data, reported by @gsliepen
- cli : change : `-o` can be combined with multiple inputs, by @terrelln
- cli : fix : content size written in header by default
- cli : fix : improved LZ4 format support, by @felixhandte
- cli : new : hidden command `-b -S`, to benchmark multiple files and generate one result per file
- api : change : when setting `pledgedSrcSize`, use `ZSTD_CONTENTSIZE_UNKNOWN` macro value to mean "unknown"
- api : fix : support large skippable frames, by @terrelln
- api : fix : re-using context could result in suboptimal block size in some corner case scenarios
- api : fix : streaming interface was adding a useless 3-bytes null block to small frames
- build: fix : compilation under rhel6 and centos6, reported by @pixelb
- build: added `check` target
- build: improved meson support, by @shawnl 2017-12-21T09:25:55+00:00zstd v1.3.4zstd v1.3.42018-03-26T22:24:27+00:00The v1.3.4 release of Zstandard is focused on performance, and will offers nice speed boost in most scenarios.
### Asynchronous compression by default for `zstd` CLI
`zstd` cli will now performs compression in parallel with I/O operations by default. This requires multi-threading capability (which is also enabled by default).
It doesn't sound like much, but effectively improves throughput by 20-30%, depending on compression level and underlying I/O performance.
For example, on a Mac OS-X laptop with an Intel Core i7-5557U CPU @ 3.10GHz, running `time zstd ` [`enwik9`](http://mattmahoney.net/dc/textdata.html) at default compression level (2) on a SSD gives the following :
| Version | real time |
| --- | --- |
| 1.3.3 | 9.2s |
| 1.3.4 --single-thread | 8.8s |
| 1.3.4 (asynchronous) | 7.5s |
This is a nice boost to all scripts using `zstd` cli, typically in network or storage tasks. The effect is even more pronounced at faster compression setting, since the CLI overlaps a proportionally higher share of compression with I/O.
Previous default behavior (blocking single thread) is still available, accessible through `--single-thread` long command. It's also the only mode available when no multi-threading capability is detected.
### General speed improvements
Some core routines have been refined to provide more speed on newer cpus, making better use of their out-of-order execution units. This is more sensible on the decompression side, and even more so with `gcc` compiler.
Example on the same platform, running in-memory benchmark `zstd -b1 silesia.tar` :
| Version | C.Speed | D.Speed |
| --- | ---- | --- |
| 1.3.3 llvm9 | 290 MB/s | 660 MB/s |
| 1.3.4 llvm9 | 304 MB/s | 700 MB/s (+6%) |
| 1.3.3 gcc7 | 280 MB/s | 710 MB/s
| 1.3.4 gcc7 | 300 MB/s | 890 MB/s (+25%)|
### Faster compression levels
So far, compression level 1 has been the fastest one available. Starting with v1.3.4, there will be additional choices. Faster compression levels can be invoked using negative values.
On the command line, the equivalent one can be triggered using `--fast[=#]` command.
Negative compression levels sample data more sparsely, and disable Huffman compression of literals, translating into faster decoding speed.
It's possible to create one's own custom fast compression level
by using strategy `ZSTD_fast`, increasing `ZSTD_p_targetLength` to desired value,
and turning on or off literals compression, using `ZSTD_p_compressLiterals`.
Performance is generally on par or better than other high speed algorithms. On below benchmark (compressing `silesia.tar` on an Intel Core i7-6700K CPU @ 4.00GHz) , it ends up being faster and stronger on all metrics compared with `quicklz` and `snappy` at `--fast=2`. It also compares favorably to `lzo` with `--fast=3`. `lz4` still offers a better speed / compression combo, with `zstd --fast=4` approaching close.
name | ratio | compression | decompression
-- | -- | -- | --
zstd 1.3.4 --fast=5 | 1.996 | 770 MB/s | 2060 MB/s
lz4 1.8.1 | 2.101 | 750 MB/s | 3700 MB/s
zstd 1.3.4 --fast=4 | 2.068 | 720 MB/s | 2000 MB/s
zstd 1.3.4 --fast=3 | 2.153 | 675 MB/s | 1930 MB/s
lzo1x 2.09 -1 | 2.108 | 640 MB/s | 810 MB/s
zstd 1.3.4 --fast=2 | 2.265 | 610 MB/s | 1830 MB/s
quicklz 1.5.0 -1 | 2.238 | 540 MB/s | 720 MB/s
snappy 1.1.4 | 2.091 | 530 MB/s | 1820 MB/s
zstd 1.3.4 --fast=1 | 2.431 | 530 MB/s | 1770 MB/s
zstd 1.3.4 -1 | 2.877 | 470 MB/s | 1380 MB/s
brotli 1.0.2 -0 | 2.701 | 410 MB/s | 430 MB/s
lzf 3.6 -1 | 2.077 | 400 MB/s | 860 MB/s
zlib 1.2.11 -1 | 2.743 | 110 MB/s | 400 MB/s
Applications which were considering Zstandard but were worried of being CPU-bounded are now able to shift the load from CPU to bandwidth on a larger scale, and may even vary temporarily their choice depending on local conditions (to deal with some sudden workload surge for example).
### Long Range Mode with Multi-threading
zstd-1.3.2 introduced the [long range mode](https://github.com/facebook/zstd/releases/tag/v1.3.2), capable to deduplicate long distance redundancies in a large data stream, a situation typical in backup scenarios for example. But its usage in association with multi-threading was discouraged, due to inefficient use of memory.
zstd-1.3.4 solves this issue, by making long range match finder run in serial mode, like a pre-processor, before passing its result to backend compressors (regular zstd). Memory usage is now bounded to the maximum of the long range window size, and the memory that zstdmt would require without long range matching. As the long range mode runs at about 200 MB/s, depending on the number of cores available, it's possible to tune compression level to match the LRM speed, which becomes the upper limit.
```sh
zstd -T0 -5 --long file # autodetect threads, level 5, 128 MB window
zstd -T16 -10 --long=31 file # 16 threads, level 10, 2 GB window
```
As illustration, benchmarks of the two files "Linux 4.7 - 4.12" and "Linux git" from the [1.3.2 release](https://github.com/facebook/zstd/releases/tag/v1.3.2) are shown below. All compressors are run with 16 threads, except "zstd single 2 GB". `zstd` compressors are run with either a 128 MB or 2 GB window size, and `lrzip` compressor is run with `lzo`, `gzip`, and `xz` backends. The benchmarks were run on a 16 core Sandy Bridge @ 2.2 GHz.


The association of Long Range Mode with multi-threading offers now some very compelling results for large stream scenarios.
### Miscellaneous
This release also brings its usual list of small improvements and bug fixes, as detailed below :
- perf: faster speed (especially decoding speed) on recent cpus (haswell+)
- perf: much better performance associating `--long` with multi-threading, by @terrelln
- perf: better compression at levels 13-15
- cli : asynchronous compression by default, for faster experience (use `--single-thread` for former behavior)
- cli : smoother status report in multi-threading mode
- cli : added command `--fast=#`, for faster compression modes
- cli : fix crash when not overwriting existing files, by Pádraig Brady (@pixelb)
- api : `nbThreads` becomes `nbWorkers` : 1 triggers asynchronous mode
- api : compression levels can be negative, for even more speed
- api : `ZSTD_getFrameProgression()` : get precise progress status of ZSTDMT anytime
- api : ZSTDMT can accept new compression parameters during compression
- api : implemented all advanced dictionary decompression prototypes
- build: improved meson recipe, by Shawn Landden (@shawnl)
- build: VS2017 scripts, by @HaydnTrigg
- misc: all `/contrib` projects fixed
- misc: added `/contrib/docker` script by @gyscos
2018-03-26T22:24:27+00:00zstd v1.3.5zstd v1.3.52018-06-28T16:57:59+00:00Zstandard v1.3.5 is a maintenance release focused on dictionary compression performance.
Compression is generally associated with the act of willingly requesting the compression of some large source. However, within datacenters, compression brings its best benefits when completed transparently. In such scenario, it's actually very common to compress a large number of very small blobs (individual messages in a stream or log, or records in a cache or datastore, etc.). Dictionary compression is a great tool for these use cases.
This release makes dictionary compression significantly faster for these situations, when compressing small to very small data (inputs up to ~16 KB).

The above image plots the compression speeds at different input sizes for `zstd` v1.3.4 (red) and v1.3.5 (green), at levels 1, 3, 9, and 18.
The benchmark data was gathered on an `Intel Xeon CPU E5-2680 v4 @ 2.40GHz`. The benchmark was compiled with `clang-7.0`, with the flags `-O3 -march=native -mtune=native -DNDEBUG`. The file used in the results shown here is the `osdb` file from the Silesia corpus, cut into small blocks. It was selected because it performed roughly in the middle of the pack among the Silesia files.
The new version saves substantial initialization time, which is increasingly important as the average size to compress becomes smaller. The impact is even more perceptible at higher levels, where initialization costs are higher. For larger inputs, performance remain similar.
Users can expect to measure substantial speed improvements for inputs smaller than 8 KB, and up to 32 KB depending on the context. The expected speed-up ranges from none (large, incompressible blobs) to many times faster (small, highly compressible inputs). Real world examples up to 15x have been observed.
#### Other noticeable improvements
The compression levels have been slightly adjusted, taking into consideration the higher top speed of level 1 since v1.3.4, and making level 19 a substantially stronger compression level while preserving the `8 MB` window size limit, hence keeping an acceptable memory budget for decompression.
It's also possible to select the content of `libzstd` by [modifying macro values](https://github.com/facebook/zstd/tree/v1.3.5/lib#modular-build) at compilation time. By default, `libzstd` contains everything, but its size can be made substantially smaller by removing support for the dictionary builder, or legacy formats, or deprecated functions. It's even possible to build a compression-only or a decompression-only library.
### Detailed changes list
- perf: much faster dictionary compression, by @felixhandte
- perf: small quality improvement for dictionary generation, by @terrelln
- perf: improved high compression levels (notably level 19)
- mem : automatic memory release for long duration contexts
- cli : fix : `overlapLog` can be manually set
- cli : fix : decoding invalid lz4 frames
- api : fix : performance degradation for dictionary compression when using advanced API, by @terrelln
- api : change : clarify `ZSTD_CCtx_reset()` vs` ZSTD_CCtx_resetParameters()`, by @terrelln
- build: select custom `libzstd` scope through control macros, by @GeorgeLu97
- build: OpenBSD support, by @bket
- build: `make` and `make all` are compatible with `-j`
- doc : clarify `zstd_compression_format.md`, updated for IETF RFC process
- misc: `pzstd` compatible with reproducible compilation, by @lamby2018-06-28T16:57:59+00:00zstd v1.3.6zstd v1.3.62018-10-05T16:48:23+00:00Zstandard v1.3.6 release is focused on intensive dictionary compression for database scenarios.
This is a new environment we are experimenting. The success of dictionary compression on small data, of which databases tend to store plentiful, led to increased adoption, and we now see scenarios where literally thousands of dictionaries are being used simultaneously, with permanent generation or update of new dictionaries.
To face these new conditions, v1.3.6 brings a few improvements to the table :
- A brand new, faster dictionary builder, by @jenniferliu, under guidance from @terrelln. The new builder, named _fastcover_, is about 10x faster than our previous default generator, cover, while suffering only negligible accuracy losses (<1%). It's effectively an approximative version of cover, which throws away accuracy for the benefit of speed and memory. The new dictionary builder is so effective that it has become our new default dictionary builder (`--train`). Slower but higher quality generator remains accessible using `--train-cover` command.
Here is an example, using the "github user records" public dataset (about 10K records of about 1K each) :
| builder algorithm | generation time | compression ratio |
| --- | --- | --- |
| fast cover (v1.3.6 `--train`) | 0.9 s | x10.29 |
| cover (v1.3.5 `--train`) | 10.1 s | x10.31
| High accuracy fast cover (`--train-fastcover`) | 6.6 s | x10.65
| High accuracy cover (`--train-cover`) | 50.5 s | x10.66
- Faster dictionary decompression under memory pressure, when using thousands of dictionaries simultaneously. The new decoder is able to detect cold vs hot dictionary scenarios, and adds clever prefetching decisions to minimize memory latency. It typically improves decoding speed by ~+30% (vs v1.3.5).
- Faster dictionary compression under memory pressure, when using a lot of contexts simultaneously. The new design, by @felixhandte, reduces considerably memory usage when compressing small data with dictionaries, which is the main scenario found in databases. The sharp memory usage reduction makes it easier for CPU caches to manages multiple contexts in parallel. Speed gains scale with number of active contexts, as shown in the graph below :

Note that, in real-life environment, benefits are present even faster, since cpu caches tend to be used by multiple other process / threads at the same time, instead of being monopolized by a single synthetic benchmark.
#### Other noticeable improvements
A new command `--adapt`, makes it possible to pipe gigantic amount of data between servers (typically for backup scenarios), and let the compressor automatically adjust compression level based on perceived network conditions. When the network becomes slower, `zstd` will use available time to compress more, and accelerate again when bandwidth permit. It reduces the need to "pre-calibrate" speed and compression level, and is a good simplification for system administrators. It also results in gains for both dimensions (better compression ratio _and_ better speed) compared to the more traditional "fixed" compression level strategy.
This is still early days for this feature, and we are eager to get feedback on its usages. We know it works better in fast bandwidth environments for example, as adaptation itself becomes slow when bandwidth is slow. This is something that will need to be improved. Nonetheless, in its current incarnation, `--adapt` already proves useful for several datacenter scenarios, which is why we are releasing it.
Finally, advanced users will be please by the expansion of an existing tool, `tests/paramgrill`, which has been refined by @georgelu. This tool explores the space of [advanced compression parameters](https://github.com/facebook/zstd/blob/v1.3.6/programs/zstd.1.md#advanced-compression-options), to find the best possible set of compression parameters for a given scenario. It takes as input a set of samples, and a set of constraints, and works its way towards better and better compression parameters respecting the constraints.
Example :
```
./paramgrill --optimize=cSpeed=50M dirToSamples/* # requires minimum compression speed of 50 MB/s
optimizing for dirToSamples/* - limit compression speed 50 MB/s
(...)
/* Level 5 */ { 20, 18, 18, 2, 5, 2,ZSTD_greedy , 0 }, /* R:3.147 at 75.7 MB/s - 567.5 MB/s */ # best level satisfying constraint
--zstd=windowLog=20,chainLog=18,hashLog=18,searchLog=2,searchLength=5,targetLength=2,strategy=3,forceAttachDict=0
(...)
/* Custom Level */ { 21, 16, 18, 2, 6, 0,ZSTD_lazy2 , 0 }, /* R:3.240 at 53.1 MB/s - 661.1 MB/s */ # best custom parameters found
--zstd=windowLog=21,chainLog=16,hashLog=18,searchLog=2,searchLength=6,targetLength=0,strategy=5,forceAttachDict=0 # associated command arguments, can be copy/pasted for `zstd`
```
Finally, documentation has been updated, to reflect wording adopted by [IETF RFC 8478 (_Zstandard Compression and the application/zstd Media Type_)](https://tools.ietf.org/html/rfc8478).
### Detailed changes list
- perf: much faster dictionary builder, by @jenniferliu
- perf: faster dictionary compression on small data when using multiple contexts, by @felixhandte
- perf: faster dictionary decompression when using a very large number of dictionaries simultaneously
- cli : fix : does no longer overwrite destination when source does not exist (#1082)
- cli : new command `--adapt`, for automatic compression level adaptation
- api : fix : block api can be streamed with > 4 GB, reported by @catid
- api : reduced `ZSTD_DDict` size by 2 KB
- api : minimum negative compression level is defined, and can be queried using `ZSTD_minCLevel()` (#1312).
- build: support Haiku target, by @korli
- build: Read Legacy support is now limited to v0.5+ by default. Can be changed at compile time with macro `ZSTD_LEGACY_SUPPORT`.
- doc : `zstd_compression_format.md` updated to match wording in [IETF RFC 8478](https://tools.ietf.org/html/rfc8478)
- misc: tests/paramgrill, a parameter optimizer, by @GeorgeLu97 2018-10-05T16:48:23+00:00zstd v1.3.7zstd v1.3.72018-10-19T21:34:33+00:00This is minor fix release building upon v1.3.6.
The main reason we publish this new version is that @indygreg detected an important compression ratio regression for a specific scenario (compressing with dictionary at level 9 or 10 for small data, or 11 - 12 for large data) . We don't anticipate this scenario to be common : dictionary compression is still rare, then most users prefer fast modes (levels <=3), a few rare ones use strong modes (level 15-19), so "middle compression" is an extreme rarity.
But just in case some user do, we publish this release.
A few other minor things were ongoing and are therefore bundled.
Decompression speed might be slightly better with `clang`, depending on exact target and version. We could observe as mush as 7% speed gains in some cases, though in other cases, it's rather in the ~2% range.
The integrated backtrace functionality in the cli is updated : its presence can be more easily controlled, invoking `BACKTRACE` build macro. The automatic detector is more restrictive, and release mode builds without it by default. We want to be sure the default `make` compiles without any issue on most platforms.
Finally, the list of man pages has been completed with documentation for `zstdless` and `zstdgrep`, by @samrussell .
#### Detailed list of changes
- perf: slightly better decompression speed on clang (depending on hardware target)
- fix : ratio for dictionary compression at levels 9 and 10, reported by @indygreg
- build: no longer build backtrace by default in release mode; restrict further automatic mode
- build: control backtrace support through build macro BACKTRACE
- misc: added man pages for zstdless and zstdgrep, by @samrussell2018-10-19T21:34:33+00:00zstd regression-datazstd regression-data2018-11-29T18:53:21+00:00Zstandard regression testing data2018-11-29T18:53:21+00:00zstd v1.3.8zstd v1.3.82018-12-27T18:39:10+00:00#### Advanced API
`v1.3.8` main focus is the stabilization of the [advanced API](https://github.com/facebook/zstd/blob/v1.3.8/lib/zstd.h#L419).
This API has been in the making for more than a year, and makes it possible to trigger advanced features, such as multithreading, `--long` mode, or detailed frame parameters, in a straightforward and extensible manner. Some examples are provided [in this blog entry](https://code.fb.com/core-data/zstandard/).
To make this vision possible, the advanced API relies on sticky parameters, which can be stacked on top of each other in any order. This makes it possible to introduce new features in the future without breaking API nor ABI.
This API has provided a good experience in our infrastructure, and we hope it will prove easy to use and efficient in your applications. Nonetheless, before being branded "stable", this proposal must spend a last round in "staging area", in order to generate comments and feedback from new users. It's planned to be labelled "stable" by `v1.4.0`, which is expected to be next release, depending on received feedback.
The experimental section still contains a lot of prototypes which are largely redundant with the new advanced API. Expect them to become deprecated, and then later dropped in some future. Transition towards the newer advanced API is therefore highly recommended.
#### Performance
Decoding speed has been improved again, primarily for some specific scenarios : frames using large window sizes (`--ultra` or `--long`), and cold dictionary. Cold dictionary is expected to become more important in the near future, as solutions relying on thousands of dictionaries simultaneously will be deployed.
The higher compression levels get a slight compression ratio boost, mostly visible for small (<256 KB) and large (>32 MB) data streams. This change benefits asymmetric scenarios (compress ones, decompress many times), typically targeting level 19.
#### New features
A noticeable addition, @terrelln introduces the [`--rsyncable` mode](https://github.com/facebook/zstd/blob/v1.3.8/programs/zstd.1.md#operation-modifiers) to `zstd`. Similar to `gzip --rsyncable`, it generates a compressed frame which is friendly to `rsync` in case of limited changes : a difference in the input data will only impact a small localized amount of compressed data, instead of everything from the position onward due to cascading impacts. This is useful for very large archives regularly updated and synchronized over long distance connections (as an example, compressed mailboxes come to mind).
The method used by `zstd` preserves the compression ratio very well, introducing only very tiny losses due to synchronization points, meaning it's no longer a sacrifice to use `--rsyncable`. Here is an example on `silesia.tar`, using default compression level :
| compressor | normal | `--rsyncable` | Ratio diff. | time |
| --- | --- | --- | --- | --- |
| gzip | 68235456 | 68778265 | -0.795% | 7.92s |
| zstd | 66829650 | 66846769 | -0.026% | 1.17s |
Speaking of compression of level : it's now possible to use [environment variable `ZSTD_CLEVEL`](https://github.com/facebook/zstd/blob/v1.3.8/programs/README.md#restricted-usage-of-environment-variables) to influence default compression level. This can prove useful in situations where it's not possible to provide command line parameters, typically when `zstd` is invoked "under the hood" by some calling process.
Lastly, anyone interested in embedding a small `zstd` decoder into a space-constrained application will be interested in a [new set of build macros](https://github.com/facebook/zstd/tree/v1.3.8/lib#modular-build) introduced by @felixhandte, which makes it possible to selectively turn off decoder features to reduce binary size even further. Final binary size will of course vary depending on target assembler and compiler, but in preliminary testings on x64, it helped reducing the decoder size by a factor 3 (from ~64KB towards ~20KB).
#### Detailed list of changes
- perf: better decompression speed on large files (+7%) and cold dictionaries (+15%)
- perf: slightly better compression ratio at high compression modes
- api : finalized advanced API, last stage before "stable" status
- api : new `--rsyncable` mode, by @terrelln
- api : support decompression of empty frames into `NULL` (used to be an error) (#1385)
- build: new set of build macros to generate a minimal size decoder, by @felixhandte
- build: fix compilation on MIPS32, reported by @clbr (#1441)
- build: fix compilation with multiple -arch flags, by @ryandesign
- build: highly upgraded meson build, by @lzutao
- build: improved buck support, by @obelisk
- build: fix `cmake` script : can create debug build, by @pitrou
- build: `Makefile` : grep works on both colored consoles and systems without color support
- build: fixed `zstd-pgo` target, by @bmwiedemann
- cli : support `ZSTD_CLEVEL` environment variable, by @yijinfb (#1423)
- cli : `--no-progress` flag, preserving final summary (#1371), by @terrelln
- cli : ensure destination file is not source file (#1422)
- cli : clearer error messages, notably when input file not present
- doc : clarified `zstd_compression_format.md`, by @ulikunitz
- misc: fixed `zstdgrep`, returns 1 on failure, by @lzutao
- misc: `NEWS` renamed as `CHANGELOG`, in accordance with fb.oss policy
2018-12-27T18:39:10+00:00zstd v1.4.0zstd v1.4.02019-04-16T22:53:28+00:00### Advanced API
The main focus of the v1.4.0 release is the stabilization of the advanced API.
The advanced API provides a way to set specific parameters during compression and decompression in an API and ABI compatible way. For example, it allows you to compress with [multiple threads](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L349), enable [--long](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L311) mode, set [frame parameters](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L338), and [load dictionaries](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L873). It is compatible with `ZSTD_compressStream*()` and `ZSTD_compress2()`. There is also an advanced decompression API that allows you to set parameters like [maximum memory usage](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L490), and [load dictionaries](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L925). It is compatible with the existing decompression functions `ZSTD_decompressStream()` and `ZSTD_decompressDCtx()`.
The old streaming functions are all compatible with the new API, and the documentation provides the equivalent function calls in the new API. For example, see [`ZSTD_initCStream()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L677). The stable functions will remain supported, but the functions in the experimental sections, like [`ZSTD_initCStream_usingDict()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L1597), will eventually be marked as deprecated and removed in favor of the new advanced API.
The [examples](https://github.com/facebook/zstd/tree/a880ca239b447968493dd2fed3850e766d6305cc/examples) have all been updated to use the new advanced API. If you have questions about how to use the new API, please refer to the examples, and if they are unanswered, please open an issue.
### Performance
Zstd's fastest compression level just got faster! Thanks to ideas from Intel's [igzip](https://github.com/01org/isa-l/tree/master/igzip) and @gbtucker, we've made level 1, zstd's fastest strategy, 6-8% faster in most scenarios. For example on the [Silesia Corpus](http://sun.aei.polsl.pl/~sdeor/index.php?page=silesia) with level 1, we see 0.2% better compression compared to zstd-1.3.8, and these performance figures on an Intel i9-9900K:
Version | C. Speed | D. Speed
-- | -- | --
1.3.8 gcc-8 | 489 MB/s | 1343 MB/s
1.4.0 gcc-8 | 532 MB/s (+8%) | 1346 MB/s
1.3.8 clang-8 | 488 MB/s | 1188 MB/s
1.4.0 clang-8 | 528 MB/s (+8%) | 1216 MB/s
### New Features
A new experimental function [`ZSTD_decompressBound()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L1178) has been added by @shakeelrao. It is useful when decompressing zstd data in a single shot that may, or may not have the decompressed size written into the frame. It is exact when the decompressed size is written into the frame, and a tight upper bound within 128 KB, as long as `ZSTD_e_flush` and `ZSTD_flushStream()` aren't used. When `ZSTD_e_flush` is used, in the worst case the bound can be very large, but this isn't a common scenario.
The parameter `ZSTD_c_literalCompressionMode` and the CLI flag `--[no-]compress-literals` allow users to explicitly enable and disable literal compression. By default literals are compressed with positive compression levels, and left uncompressed for negative compression levels. Disabling literal compression boosts compression and decompression speed, at the cost of compression ratio.
### Detailed list of changes
* perf: Improve level 1 compression speed in most scenarios by 6% by @gbtucker and @terrelln
* api: Move the advanced API, including all functions in the staging section, to the stable section
* api: Make ZSTD_e_flush and ZSTD_e_end block for maximum forward progress
* api: Rename `ZSTD_CCtxParam_getParameter` to `ZSTD_CCtxParams_getParameter`
* api: Rename `ZSTD_CCtxParam_setParameter` to `ZSTD_CCtxParams_setParameter`
* api: Don't export ZSTDMT functions from the shared library by default
* api: Require `ZSTD_MULTITHREAD` to be defined to use ZSTDMT
* api: Add `ZSTD_decompressBound()` to provide an upper bound on decompressed size by @shakeelrao
* api: Fix `ZSTD_decompressDCtx()` corner cases with a dictionary
* api: Move `ZSTD_getDictID_*()` functions to the stable section
* api: Add `ZSTD_c_literalCompressionMode` flag to enable or disable literal compression by @terrelln
* api: Allow compression parameters to be set when a dictionary is used
* api: Allow setting parameters before or after `ZSTD_CCtx_loadDictionary()` is called
* api: Fix `ZSTD_estimateCStreamSize_usingCCtxParams()`
* api: Setting `ZSTD_d_maxWindowLog` to `0` means use the default
* cli: Ensure that a dictionary is not used to compress itself by @shakeelrao
* cli: Add `--[no-]compress-literals` flag to enable or disable literal compression
* doc: Update the examples to use the advanced API
* doc: Explain how to transition from old streaming functions to the advanced API in the header
* build: Improve the Windows release packages
* build: Improve CMake build by @hjmjohnson
* build: Build fixes for FreeBSD by @lwhsu
* build: Remove redundant warnings by @thatsafunnyname
* build: Fix tests on OpenBSD by @bket
* build: Extend fuzzer build system to work with the new clang engine
* build: CMake now creates the `libzstd.so.1` symlink
* build: Improve Menson build by @lzutao
* misc: Fix symbolic link detection on FreeBSD
* misc: Use physical core count for `-T0` on FreeBSD by @cemeyer
* misc: Fix `zstd --list` on truncated files by @kostmo
* misc: Improve logging in debug mode by @felixhandte
* misc: Add CirrusCI tests by @lwhsu
* misc: Optimize dictionary memory usage in corner cases
* misc: Improve the dictionary builder on small or homogeneous data
* misc: Fix spelling across the repo by @jsoref2019-04-16T22:53:28+00:00zstd v1.4.1zstd v1.4.12019-07-19T19:03:30+00:00### Maintenance
This release is primarily a maintenance release.
It includes a few bug fixes, including a fix for a rare data corruption bug, which could only be triggered in a niche use case, when doing all of the following: using multithreading mode, with an overlap size >= 512 MB, using a strategy >= `ZSTD_btlazy`, and compressing more than 4 GB. None of the default compression levels meet these requirements (not even `--ultra` ones).
### Performance
This release also includes some performance improvements, among which the primary improvement is that Zstd decompression is ~7% faster, thanks to @mgrice.
See this comparison of decompression speeds at different compression levels, measured on the Silesia Corpus, on an Intel i9-9900K with GCC 9.1.0.
| Level | v1.4.0 | v1.4.1 | Delta |
| ---: | :---: | :---: | ---: |
| 1 | 1390 MB/s | 1453 MB/s | +4.5% |
| 3 | 1208 MB/s | 1301 MB/s | +7.6% |
| 5 | 1129 MB/s | 1233 MB/s | +9.2% |
| 7 | 1224 MB/s | 1347 MB/s | +10.0% |
| 16 | 1278 MB/s | 1430 MB/s | +11.8% |
### Detailed list of changes
* bug: Fix data corruption in niche use cases by @terrelln (#1659)
* bug: Fuzz legacy modes, fix uncovered bugs by @terrelln (#1593, #1594, #1595)
* bug: Fix out of bounds read by @terrelln (#1590)
* perf: Improved decoding speed by ~7% @mgrice (#1668)
* perf: Large compression ratio improvement for small `windowLog` by @cyan4973 (#1624)
* perf: Slightly improved compression ratio of level 3 and 4 (`ZSTD_dfast`) by @cyan4973 (#1681)
* perf: Slightly faster compression speed when re-using a context by @cyan4973 (#1658)
* perf: Faster compression speed in high compression mode for repetitive data by @terrelln (#1635)
* api: Add parameter to generate smaller dictionaries by @tyler-tran (#1656)
* cli: Recognize symlinks when built in C99 mode by @felixhandte (#1640)
* cli: Expose cpu load indicator for each file on -vv mode by @ephiepark (#1631)
* cli: Restrict read permissions on destination files by @chungy (#1644)
* cli: zstdgrep: handle -f flag by @felixhandte (#1618)
* cli: zstdcat: follow symlinks by @vejnar (#1604)
* doc: Remove extra size limit on compressed blocks by @felixhandte (#1689)
* doc: Fix typo by @yk-tanigawa (#1633)
* doc: Improve documentation on streaming buffer sizes by @cyan4973 (#1629)
* build: CMake: support building with LZ4 @leeyoung624 (#1626)
* build: CMake: install zstdless and zstdgrep by @leeyoung624 (#1647)
* build: CMake: respect existing uninstall target by @j301scott (#1619)
* build: Make: skip multithread tests when built without support by @michaelforney (#1620)
* build: Make: Fix examples/ test target by @sjnam (#1603)
* build: Meson: rename options out of deprecated namespace by @lzutao (#1665)
* build: Meson: fix build by @lzutao (#1602)
* build: Visual Studio: don't export symbols in static lib by @scharan (#1650)
* build: Visual Studio: fix linking by @absotively (#1639)
* build: Fix MinGW-W64 build by @myzhang1029 (#1600)
* misc: Expand decodecorpus coverage by @ephiepark (#1664)
2019-07-19T19:03:30+00:00zstd v1.4.2zstd v1.4.22019-07-25T17:48:57+00:00### Legacy Decompression Fix
This release is a small one, that corrects an issue discovered in the previous release. Zstandard v1.4.1 included a bug in decompressing v0.5 legacy frames, which is fixed in v1.4.2.
### Detailed Changes
* bug: Fix bug in zstd-0.5 decoder by @terrelln (#1696)
* bug: Fix seekable decompression in-memory API by @iburinoc (#1695)
* bug: Close minor memory leak in CLI by @LeeYoung624 (#1701)
* misc: Validate blocks are smaller than size limit by @vivekmig (#1685)
* misc: Restructure source files by @ephiepark (#1679)
2019-07-25T17:48:57+00:00zstd v1.4.3zstd v1.4.32019-08-19T20:55:18+00:00### Dictionary Compression Regression
We discovered an issue in the v1.4.2 release, which can degrade the effectiveness of dictionary compression. This release fixes that issue.
### Detailed Changes
* bug: Fix Dictionary Compression Ratio Regression by @cyan4973 (#1709)
* bug: Fix Buffer Overflow in v0.3 Decompression by @felixhandte (#1722)
* build: Add support for IAR C/C++ Compiler for Arm by @joseph0918 (#1705)
* misc: Add NULL pointer check in util.c by @leeyoung624 (#1706)2019-08-19T20:55:18+00:00zstd v1.4.4zstd v1.4.42019-11-05T18:36:09+00:00This release includes some major performance improvements and new CLI features, which make it a recommended upgrade.
## Faster Decompression Speed
Decompression speed has been substantially improved, thanks to @terrelln. Exact mileage obviously varies depending on files and scenarios, but the general expectation is a bump of about +10%. The benefit is considered applicable to all scenarios, and will be perceptible for most usages.
Some benchmark figures for illustration:
| | v1.4.3 | v1.4.4 |
| --- | --- | --- |
| silesia.tar | 1440 MB/s | 1600 MB/s |
| enwik8 | 1225 MB/s | 1390 MB/s |
| calgary.tar | 1360 MB/s | 1530 MB/s |
## Faster Compression Speed when Re-Using Contexts
In server workloads (characterized by very high compression volume of relatively small inputs), the allocation and initialization of `zstd`'s internal datastructures can become a significant part of the cost of compression. For this reason, `zstd` has long had an optimization (which we recommended for large-scale users, perhaps with something like [this](https://github.com/facebook/folly/blob/master/folly/compression/CompressionContextPool.h)): when you provide an already-used `ZSTD_CCtx` to a compression operation, `zstd` tries to re-use the existing data structures, if possible, rather than re-allocate and re-initialize them.
Historically, this optimization could avoid re-allocation most of the time, but required an exact match of internal parameters to avoid re-initialization. In this release, @felixhandte removed the dependency on matching parameters, allowing the full context re-use optimization to be applied to effectively all compressions. Practical workloads on small data should expect a ~3% speed-up.
In addition to improving average performance, this change also has some nice side-effects on the extremes of performance.
* On the fast end, it is now easier to get optimal performance from `zstd`. In particular, it is no longer necessary to do careful tracking and matching of contexts to compressions based on detailed parameters (as discussed for example in #1796). Instead, straightforwardly reusing contexts is now optimal.
* Second, this change ameliorates some rare, degenerate scenarios (e.g., high volume streaming compression of small inputs with varying, high compression levels), in which it was possible for the allocation and initialization work to vastly overshadow the actual compression work. These cases are up to 40x faster, and now perform in-line with similar happy cases.
## Dictionaries and Large Inputs
In theory, using a dictionary should always be beneficial. However, due to some long-standing implementation limitations, it can actually be detrimental. Case in point: by default, dictionaries are prepared to compress small data (where they are most useful). When this prepared dictionary is used to compress large data, there is a mismatch between the prepared parameters (targeting small data) and the ideal parameters (that would target large data). This can cause dictionaries to counter-intuitively result in a *lower* compression ratio when compressing large inputs.
Starting with v1.4.4, using a dictionary with a very large input will no longer be detrimental. Thanks to a patch from @senhuang42, whenever the library notices that input is sufficiently large (relative to dictionary size), the dictionary is re-processed, using the optimal parameters for large data, resulting in improved compression ratio.
The capability is also exposed, and can be manually triggered using `ZSTD_dictForceLoad`.
## New commands
`zstd` CLI extends its capabilities, providing new advanced commands, thanks to great contributions :
* `zstd` generated files (compressed or decompressed) can now be automatically stored into a *different* directory than the source one, using `--output-dir-flat=DIR` command, provided by @senhuang42 .
* It’s possible to inform `zstd` about the size of data coming from `stdin` . @nmagerko proposed 2 new commands, allowing users to provide the exact stream size (`--stream-size=#` ) or an approximative one (`--size-hint=#`). Both only make sense when compressing a data stream from a pipe (such as `stdin`), since for a real file, `zstd` obtains the exact source size from the file system. Providing a source size allows `zstd` to better adapt internal compression parameters to the input, resulting in better performance and compression ratio. Additionally, providing the precise size makes it possible to embed this information in the compressed frame header, which also allows decoder optimizations.
* In situations where the same directory content get regularly compressed, with the intention to only compress new files not yet compressed, it’s necessary to filter the file list, to exclude already compressed files. This process is simplified with command `--exclude-compressed`, provided by [@shashank0791](https://github.com/shashank0791) . As the name implies, it simply excludes all compressed files from the list to process.
## Single-File Decoder with Web Assembly
Let’s complete the picture with an impressive contribution from @cwoffenden. `libzstd` has long offered the capability to build only the decoder, in order to generate smaller binaries that can be more easily embedded into memory-constrained devices and applications.
@cwoffenden built on this capability and offers a script creating a single-file decoder, as an amalgamated variant of reference Zstandard’s decoder. The package is completed with a nice build script, which compiles the one-file decoder into `WASM` code, for embedding into web application, and even tests it.
As a capability example, check out the awesome WebGL demo provided by @cwoffenden in `/contrib/single_file_decoder/examples` directory!
## Full List
- perf: Improved decompression speed, by > 10%, by @terrelln
- perf: Better compression speed when re-using a context, by @felixhandte
- perf: Fix compression ratio when compressing large files with small dictionary, by @senhuang42
- perf: `zstd` reference encoder can generate `RLE` blocks, by @bimbashrestha
- perf: minor generic speed optimization, by @davidbolvansky
- api: new ability to extract sequences from the parser for analysis, by @bimbashrestha
- api: fixed decoding of magic-less frames, by @terrelln
- api: fixed `ZSTD_initCStream_advanced()` performance with fast modes, reported by @QrczakMK
- cli: Named pipes support, by @bimbashrestha
- cli: short tar's extension support, by @stokito
- cli: command `--output-dir-flat=DIE` , generates target files into requested directory, by @senhuang42
- cli: commands `--stream-size=#` and `--size-hint=#`, by @nmagerko
- cli: command `--exclude-compressed`, by @shashank0791
- cli: faster `-t` test mode
- cli: improved some error messages, by @vangyzen
- cli: fix rare deadlock condition within dictionary builder, by @terrelln
- build: single-file decoder with emscripten compilation script, by @cwoffenden
- build: fixed `zlibWrapper` compilation on Visual Studio, reported by @bluenlive
- build: fixed deprecation warning for certain gcc version, reported by @jasonma163
- build: fix compilation on old gcc versions, by @cemeyer
- build: improved installation directories for cmake script, by Dmitri Shubin
- pack: modified `pkgconfig`, for better integration into openwrt, requested by @neheb
- misc: Improved documentation : `ZSTD_CLEVEL`, `DYNAMIC_BMI2`, `ZSTD_CDict`, function deprecation, zstd format
- misc: fixed educational decoder : accept larger literals section, and removed `UNALIGNED()` macro2019-11-05T18:36:09+00:00zstd v1.4.5zstd v1.4.52020-05-22T07:08:41+00:00# Zstd v1.4.5 Release Notes
This is a fairly important release which includes performance improvements and new major CLI features. It also fixes a few corner cases, making it a recommended upgrade.
## Faster Decompression Speed
Decompression speed has been improved again, thanks to great contributions from [@terrelln](https://github.com/terrelln).
As usual, exact mileage varies depending on files and compilers.
For `x64` cpus, expect a speed bump of at least +5%, and up to +10% in favorable cases.
`ARM` cpus receive more benefit, with speed improvements ranging from +15% vicinity, and up to +50% for certain SoCs and scenarios (`ARM`‘s situation is more complex due to larger differences in SoC designs).
For illustration, some benchmarks run on a modern `x64` platform using `zstd -b` compiled with `gcc` v9.3.0 :
| |v1.4.4 |v1.4.5 |
|--- |--- |--- |
|silesia.tar |1568 MB/s |1653 MB/s |
|--- |--- |--- |
|enwik8 |1374 MB/s |1469 MB/s |
|calgary.tar |1511 MB/s |1610 MB/s |
Same platform, using `clang` v10.0.0 compiler :
| |v1.4.4 |v1.4.5 |
|--- |--- |--- |
|silesia.tar |1439 MB/s |1496 MB/s |
|--- |--- |--- |
|enwik8 |1232 MB/s |1335 MB/s |
|calgary.tar |1361 MB/s |1457 MB/s |
## Simplified integration
Presuming a project needs to integrate `libzstd`'s *source code* (as opposed to linking a pre-compiled library), the `/lib` source directory can be copy/pasted into target project. Then the local build system must setup a few include directories. Some setups are automatically provided in prepared build scripts, such as `Makefile`, but any other 3rd party build system must do it on its own.
This integration is now simplified, thanks to @felixhandte, by making all dependencies within `/lib` relative, meaning it’s only necessary to setup include directories for the `*.h` header files that are directly included into target project (typically `zstd.h`). Even that task can be circumvented by copy/pasting the `*.h` into already established include directories.
Alternatively, if you are a fan of one-file integration strategy, @cwoffenden has extended his one-file decoder script into a full feature [one-file compression library](https://github.com/facebook/zstd/tree/dev/contrib/single_file_libs). The script [`create_single_file_library.sh`](https://github.com/facebook/zstd/blob/dev/contrib/single_file_libs/create_single_file_library.sh) will generate a file `zstd.c`, which contains all selected elements from the library (by default, compression and decompression). It’s then enough to import just `zstd.h` and the generated `zstd.c` into target project to access all included capabilities.
## `--patch-from`
Zstandard CLI is introducing a new command line option `--patch-from`, which leverages existing compressors, dictionaries and long range match finder to deliver a high speed engine for producing and applying patches to files.
`--patch-from` is based on dictionary compression. It will consider a previous version of a file as a dictionary, to better compress a new version of same file. This operation preserves fast `zstd` speeds at lower compression levels. To this ends, it also increases the previous maximum limit for dictionaries from 32 MB to 2 GB, and automatically uses the long range match finder when needed (though it can also be manually overruled).
`--patch-from` can also be combined with multi-threading mode at a very minimal compression ratio loss.
Example usage:
```
`# create the patch
zstd --patch-from=<oldfile> <newfile> -o <patchfile>
# apply the patch
zstd -d --patch-from=<oldfile> <patchfile> -o <newfile>`
```
Benchmarks:
We compared `zstd` to `bsdiff`, a popular industry grade diff engine. Our test corpus were tarballs of different versions of source code from popular GitHub repositories. Specifically:
```
`repos = {
# ~31mb (small file)
"zstd": {"url": "https://github.com/facebook/zstd", "dict-branch": "refs/tags/v1.4.2", "src-branch": "refs/tags/v1.4.3"},
# ~273mb (medium file)
"wordpress": {"url": "https://github.com/WordPress/WordPress", "dict-branch": "refs/tags/5.3.1", "src-branch": "refs/tags/5.3.2"},
# ~1.66gb (large file)
"llvm": {"url": "https://github.com/llvm/llvm-project", "dict-branch": "refs/tags/llvmorg-9.0.0", "src-branch": "refs/tags/llvmorg-9.0.1"}
}`
```
`--patch-from` on level 19 (with chainLog=30 and targetLength=4kb) is comparable with `bsdiff` when comparing patch sizes.
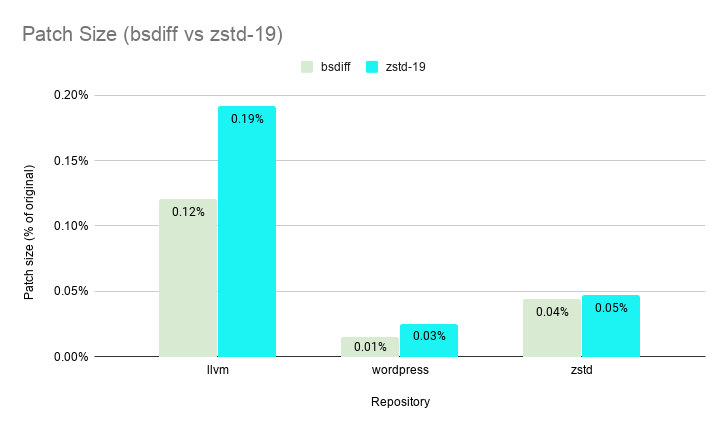
`--patch-from` greatly outperforms `bsdiff` in speed even on its slowest setting of level 19 boasting an average speedup of ~7X. `--patch-from` is >200X faster on level 1 and >100X faster (shown below) on level 3 vs `bsdiff` while still delivering patch sizes less than 0.5% of the original file size.
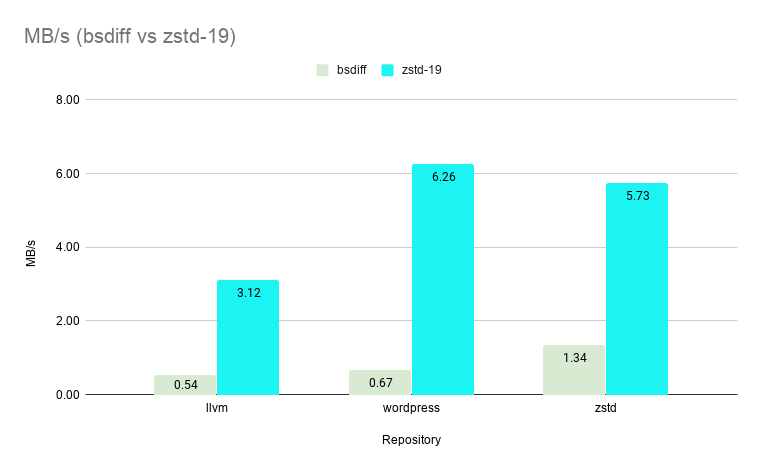
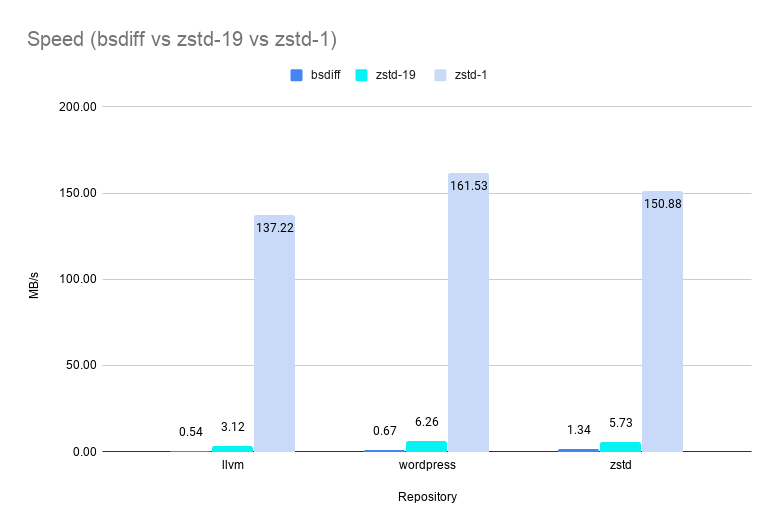
And of course, there is no change to the fast zstd decompression speed.
## `--filelist=`
Finally, `--filelist=` is a new CLI capability, which makes it possible to pass a list of files to operate upon from a file,
as opposed to listing all target files solely on the command line.
This makes it possible to prepare a list offline, save it into a file, and then provide the prepared list to `zstd`.
Another advantage is that this method circumvents command line size limitations, which can become a problem when operating on very large directories (such situation can typically happen with shell expansion).
In contrast, passing a very large list of filenames from within a file is free of such size limitation.
## Full List
- perf: Improved decompression speed (x64 >+5%, ARM >+15%), by @terrelln
- perf: Automatically downsizes `ZSTD_DCtx` when too large for too long (#2069, by @bimbashreshta)
- perf: Improved fast compression speed on `aarch64` (#2040, ~+3%, by @caoyzh)
- perf: Small level 1 compression speed gains (depending on compiler)
- fix: Compression ratio regression on huge files (> 3 GB) using high levels (`--ultra`) and multithreading, by @terrelln
- api: `ZDICT_finalizeDictionary()` is promoted to stable (#2111)
- api: new experimental parameter `ZSTD_d_stableOutBuffer` (#2094)
- build: Generate a single-file `libzstd` library (#2065, by [@cwoffenden](https://github.com/cwoffenden))
- build: Relative includes, no longer require `-I` flags for `zstd` lib subdirs (#2103, by @felixhandte)
- build: `zstd` now compiles cleanly under `-pedantic` (#2099)
- build: `zstd` now compiles with make-4.3
- build: Support `mingw` cross-compilation from Linux, by @Ericson2314
- build: Meson multi-thread build fix on windows
- build: Some misc `icc` fixes backed by new ci test on travis
- cli: New `--patch-from` command, create and apply patches from files, by @bimbashreshta
- cli: `--filelist=` : Provide a list of files to operate upon from a file
- cli: `-b` can now benchmark multiple files in decompression mode
- cli: New `--no-content-size` command
- cli: New `--show-default-cparams` command
- misc: new diagnosis tool, `checked_flipped_bits`, in `contrib/`, by @felixhandte
- misc: Extend largeNbDicts benchmark to compression
- misc: experimental edit-distance match finder in `contrib/`
- doc: Improved beginner `CONTRIBUTING.md` docs
- doc: New issue templates for zstd 2020-05-22T07:08:41+00:00zstd v1.4.7zstd v1.4.72020-12-17T03:32:24+00:00`v1.4.7` unleashes several months of improvements across many axis, from performance to various fixes, to new capabilities, of which a few are highlighted below. It’s a recommended upgrade.
(Note: if you ever wondered what happened to `v1.4.6`, it’s an internal release number reserved for synchronization with Linux Kernel)
## Improved `--long` mode
`--long` mode makes it possible to analyze vast quantities of data in reasonable time and memory budget. The `--long` mode algorithm runs on top of the regular match finder, and both contribute to the final compressed outcome.
However, the fact that these 2 stages were working independently resulted in minor discrepancies at highest compression levels, where the cost of each decision must be carefully monitored. For this reason, in situations where the input is not a good fit for `--long` mode (no large repetition at long distance), enabling it *could* reduce compression performance, even if by very little, compared to not enabling it (at high compression levels). This situation made it more difficult to "just always enable" the `--long` mode by default.
This is fixed in this version. For compression levels 16 and up, usage of `--long` will now never regress compared to compression without `--long`. This property made it possible to ramp up `--long` mode contribution to the compression mix, improving its effectiveness.
The compression ratio improvements are most notable when `--long` mode is actually useful. In particular, `--patch-from` (which implicitly relies on `--long`) shows excellent gains from the improvements. We present some brief results [here](https://github.com/facebook/zstd/wiki/Zstandard-as-a-patching-engine) (tested on Macbook Pro 16“, i9).

Since `--long` mode is now always beneficial at high compression levels, it’s now automatically enabled for any window size >= 128MB and up.
## Faster decompression of small blocks
This release includes optimizations that significantly speed up decompression of small blocks and small data. The decompression speed gains will vary based on the block size according to the table below:
Block Size | Decompression Speed Improvement
-----------|--------------------------------
1 KB | ~+30%
2 KB | ~+30%
4 KB | ~+25%
8 KB | ~+15%
16 KB | ~+10%
32 KB | ~+5%
These optimizations come from improving the process of reading the block header, and building the Huffman and FSE decoding tables. `zstd`’s default block size is 128 KB, and at this block size the time spent decompressing the data dominates the time spent reading the block header and building the decoding tables. But, as blocks become smaller, the cost of reading the block header and building decoding tables becomes more prominent.
## CLI improvements
The CLI received several noticeable upgrades with this version.
To begin with, `zstd` can accept a new parameter through environment variable, `ZSTD_NBTHREADS` . It’s useful when `zstd` is called behind an application (`tar`, or a python script for example). Also, users which prefer multithreaded compression by default can now set a desired nb of threads with their environment. This setting can still be overridden on demand via command line.
A new command `--output-dir-mirror` makes it possible to compress a directory containing subdirectories (typically with `-r` command) producing one compressed file per source file, and reproduce the arborescence into a selected destination directory.
There are other various improvements, such as more accurate warning and error messages, full equivalence between conventions `--long-command=FILE` and `--long-command FILE`, fixed confusion risks between `stdin` and user prompt, or between console output and status message, as well as a new short execution summary when processing multiple files, cumulatively contributing to a nicer command line experience.
## New experimental features
### Shared Thread Pool
By default, each compression context can be set to use a maximum nb of threads.
In complex scenarios, there might be multiple compression contexts, working in parallel, and each using some nb of threads. In such cases, it might be desirable to control the _total_ nb of threads used by _all_ these compression contexts altogether.
This is now possible, by making all these compression contexts share the same threadpool. This capability is expressed thanks to a new advanced compression parameter, ``ZSTD_CCtx_refThreadPool()``, contributed by @marxin. See its [documentation](https://github.com/facebook/zstd/blob/v1.4.7/lib/zstd.h#L1501) for more details.
### Faster Dictionary Compression
This release introduces a new experimental dictionary compression algorithm, applicable to mid-range compression levels, employing strategies such as `ZSTD_greedy`, `ZSTD_lazy`, and `ZSTD_lazy2`. This new algorithm can be triggered by selecting the compression parameter `ZSTD_c_enableDedicatedDictSearch` during `ZSTD_CDict` creation (experimental section).
Benchmarks show the new algorithm providing significant compression speed gains :
Level | Hot Dict | Cold Dict
----- | -------- | ---------
5 | ~+17% | ~+30%
6 | ~+12% | ~+45%
7 | ~+13% | ~+40%
8 | ~+16% | ~+50%
9 | ~+19% | ~+65%
10 | ~+24% | ~+70%
We hope it will help making mid-levels compression more attractive for dictionary scenarios. See [the documentation](https://github.com/facebook/zstd/blob/9f8b180/lib/zstd.h#L1663-L1717) for more details. Feedback is welcome!
### New Sequence Ingestion API
We introduce a new entry point, `ZSTD_compressSequences()`, which makes it possible for users to define their own sequences, by whatever mechanism they prefer, and present them to this new entry point, which will generate a single `zstd`-compressed frame, based on provided sequences.
So for example, users can now feed to the function an array of externally generated `ZSTD_Sequence`:
`[(offset: 5, matchLength: 4, litLength: 10), (offset: 7, matchLength: 6, litLength: 3), ...]` and the function will output a zstd compressed frame based on these sequences.
This experimental API has currently several limitations (and its relevant params exist in the “experimental” section). Notably, this API currently ignores any repeat offsets provided, instead always recalculating them on the fly. Additionally, there is no way to forcibly specify existence of certain zstd features, such as RLE or raw blocks.
If you are interested in this new entry point, please refer to `zstd.h` for more detailed usage instructions.
## Changelog
There are many other features and improvements in this release, and since we can’t highlight them all, they are listed below:
- perf: stronger `--long` mode at high compression levels, by @senhuang42
- perf: stronger `--patch-from` at high compression levels, thanks to `--long` improvements
- perf: faster decompression speed for small blocks, by @terrelln
- perf: faster dictionary compression at medium compression levels, by @felixhandte
- perf: small speed & memory usage improvements for `ZSTD_compress2()`, by @terrelln
- perf: minor generic decompression speed improvements, by @helloguo
- perf: improved fast compression speeds with Visual Studio, by @animalize
- cli : Set nb of threads with environment variable `ZSTD_NBTHREADS`, by @senhuang42
- cli : new `--output-dir-mirror DIR` command, by @xxie24 (#2219)
- cli : accept decompressing files with `*.zstd` suffix
- cli : `--patch-from` can compress `stdin` when used with `--stream-size`, by @bimbashrestha (#2206)
- cli : provide a condensed summary by default when processing multiple files
- cli : fix : `stdin` input can no longer be confused with user prompt
- cli : fix : console output no longer mixes `stdout` and status messages
- cli : improve accuracy of several error messages
- api : new sequence ingestion API, by @senhuang42
- api : shared thread pool: control total nb of threads used by multiple compression jobs, by @marxin
- api : new `ZSTD_getDictID_fromCDict()`, by @LuAPi
- api : zlibWrapper only uses public API, and is compatible with dynamic library, by @terrelln
- api : fix : multithreaded compression has predictable output even in special cases (see #2327) (issue not present on cli)
- api : fix : dictionary compression correctly respects dictionary compression level (see #2303) (issue not present on cli)
- api : fix : return `dstSize_tooSmall` error whenever appropriate
- api : fix : `ZSTD_initCStream_advanced()` with static allocation and no dictionary
- build: fix cmake script when employing path including spaces, by @terrelln
- build: new `ZSTD_NO_INTRINSICS` macro to avoid explicit intrinsics
- build: new `STATIC_BMI2` macro for compile time detection of BMI2 on MSVC, by @Niadb (#2258)
- build: improved compile-time detection of aarch64/neon platforms, by @bsdimp
- build: Fix building on AIX 5.1, by @likema
- build: compile paramgrill with cmake on Windows, requested by @mirh
- build: install pkg-config file with CMake and MinGW, by @tonytheodore (#2183)
- build: Install DLL with CMake on Windows, by @BioDataAnalysis (#2221)
- build: fix : cli compilation with uclibc
- misc: Improve single file library and include dictBuilder, by @cwoffenden
- misc: Fix single file library compilation with Emscripten, by @yoshihitoh (#2227)
- misc: Add freestanding translation script in `contrib/freestanding_lib`, by @terrelln
- doc : clarify repcode updates in format specification, by @felixhandte2020-12-17T03:32:24+00:00zstd v1.4.8zstd v1.4.82020-12-19T00:51:41+00:00This is a minor hotfix for `v1.4.7`,
where an internal buffer unalignment bug was detected by @bmwiedemann .
The issue is of no consequence for `x64` and `arm64` targets,
but could become a problem for cpus relying on strict alignment, such as `mips` or older `arm` designs.
Additionally, some targets, like 32-bit `x86` cpus, do not care much about alignment, but the code does, and will detect the misalignment and return an error code. Some other less common platforms, such as `s390x`, also seem to trigger the same issue.
While it's a minor fix, this update is nonetheless recommended.
2020-12-19T00:51:41+00:00zstd v1.4.9zstd v1.4.92021-03-03T20:38:04+00:00This is an incremental release which includes various improvements and bug-fixes.
## >2x Faster Long Distance Mode
Long Distance Mode (LDM) `--long` just got a whole lot faster thanks to optimizations by @mpu in #2483! These optimizations preserve the compression ratio but drastically speed up compression. It is especially noticeable in multithreaded mode, because the long distance match finder is not parallelized. Benchmarking with `zstd -T0 -1 --long=31` on an Intel I9-9900K at 3.2 GHz we see:
|File |v1.4.8 MB/s |v1.4.9 MB/s |Improvement |
|--- |--- |--- |--- |
|silesia.tar |308 |692 |125% |
|linux-versions* |312 |667 |114% |
|enwik9 |294 |747 |154% |
\* `linux-versions` is a concatenation of the linux 4.0, 5.0, and 5.10 git archives.
## New Experimental Decompression Feature: `ZSTD_d_refMultipleDDicts`
If the advanced parameter `ZSTD_d_refMultipleDDicts` is enabled, then multiple calls to `ZSTD_refDDict()` will be honored in the corresponding `DCtx`. Example usage:
```
ZSTD_DCtx* dctx = ZSTD_createDCtx();
ZSTD_DCtx_setParameter(dctx, ZSTD_d_refMultipleDDicts, ZSTD_rmd_refMultipleDDicts);
ZSTD_DCtx_refDDict(dctx, ddict1);
ZSTD_DCtx_refDDict(dctx, ddict2);
ZSTD_DCtx_refDDict(dctx, ddict3);
...
ZSTD_decompress...
```
Decompression of multiple frames, each with their own `dictID`, is now possible with a single `ZSTD_decompress` call. As long as the `dictID` from each frame header references one of the `dictID`s within the `DCtx`, then the corresponding dictionary will be used to decompress that particular frame. Note that this feature is disabled with a statically-allocated `DCtx`.
## Changelog
* bug: Use `umask()` to Constrain Created File Permissions (#2495, @felixhandte)
* bug: Make Simple Single-Pass Functions Ignore Advanced Parameters (#2498, @terrelln)
* api: Add (De)Compression Tracing Functionality (#2482, @terrelln)
* api: Support References to Multiple DDicts (#2446, @senhuang42)
* api: Add Function to Generate Skippable Frame (#2439, @senhuang42)
* perf: New Algorithms for the Long Distance Matcher (#2483, @mpu)
* perf: Performance Improvements for Long Distance Matcher (#2464, @mpu)
* perf: Don't Shrink Window Log when Streaming with a Dictionary (#2451, @terrelln)
* cli: Fix `--output-dir-mirror`'s Rejection of `..`-Containing Paths (#2512, @felixhandte)
* cli: Allow Input From Console When `-f`/`--force` is Passed (#2466, @felixhandte)
* cli: Improve Help Message (#2500, @senhuang42)
* tests: Avoid Using `stat -c` on NetBSD (#2513, @felixhandte)
* tests: Correctly Invoke md5 Utility on NetBSD (#2492, @niacat)
* tests: Remove Flaky Tests (#2455, #2486, #2445, @Cyan4973)
* build: Zstd CLI Can Now be Linked to Dynamic `libzstd` (#2457, #2454 @Cyan4973)
* build: Avoid Using Static-Only Symbols (#2504, @skitt)
* build: Fix Fuzzer Compiler Detection & Update UBSAN Flags (#2503, @terrelln)
* build: Explicitly Hide Static Symbols (#2501, @skitt)
* build: CMake: Enable Only C for lib/ and programs/ Projects (#2498, @concatime)
* build: CMake: Use `configure_file()` to Create the `.pc` File (#2462, @lazka)
* build: Add Guards for `_LARGEFILE_SOURCE` and `_LARGEFILE64_SOURCE` (#2444, @indygreg)
* build: Improve `zlibwrapper` Makefile (#2437, @Cyan4973)
* contrib: Add `recover_directory` Program (#2473, @terrelln)
* doc: Change License Year to 2021 (#2452 & #2465, @terrelln & @senhuang42)
* doc: Fix Typos (#2459, @ThomasWaldmann)
2021-03-03T20:38:04+00:00zstd v1.5.0zstd v1.5.02021-05-14T16:01:54+00:00`v1.5.0` is a major release featuring large performance improvements as well as API changes.
# Performance
## Improved Middle-Level Compression Speed
1.5.0 introduces a new default match finder for the compression strategies `greedy`, `lazy`, and `lazy2`, (which map to levels 5-12 for inputs larger than 256K). The optimization brings a massive improvement in compression speed with slight perturbations in compression ratio (< 0.5%) and equal or decreased memory usage.
Benchmarked with gcc, on an i9-9900K:
| level | `silesia.tar` speed delta | `enwik7` speed delta |
|--------|-----------|------------|
| 5 | +25% | +25% |
| 6 | +50% | +50% |
| 7 | +40% | +40% |
| 8 | +40% | +50% |
| 9 | +50% | +65% |
| 10 | +65% | +80% |
| 11 | +85% | +105% |
| 12 | +110% | +140% |
On heavily loaded machines with significant cache contention, we have internally measured _even larger gains_: 2-3x+ speed at levels 5-7. 🚀
The biggest gains are achieved on files typically larger than 128KB. On files smaller than 16KB, by default we revert back to the legacy match finder which becomes the faster one. This default policy can be overriden manually: the new match finder can be forcibly enabled with the advanced parameter `ZSTD_c_useRowMatchFinder`, or through the CLI option `--[no-]row-match-finder`.
Note: only CPUs that support `SSE2` realize the full extent of this improvement.
## Improved High-Level Compression Ratio
Improving compression ratio via block splitting is now enabled by default for high compression levels (16+). The amount of benefit varies depending on the workload. Compressing archives comprised of heavily differing files will see more improvement than compression of single files that don’t vary much entropically (like text files/enwik). At levels 16+, we observe no measurable regression to compression speed.
**level 22 compression**
| file | ratio 1.4.9 | ratio 1.5.0 | ratio % delta |
|-----|---------|--------|-------|
| silesia.tar | 4.021 | 4.041 | +0.49% |
| calgary.tar | 3.646 | 3.672 | +0.71% |
| enwik7 | 3.579 | 3.579 | +0.0% |
The block splitter can be forcibly enabled on lower compression levels as well with the advanced parameter `ZSTD_c_splitBlocks`. When forcibly enabled at lower levels, speed regressions can become more notable. Additionally, since more compressed blocks may be produced, decompression speed on these blobs may also see small regressions.
## Faster Decompression Speed
The decompression speed of data compressed with large window settings (such as `--long` or `--ultra`) has been significantly improved in this version. The gains vary depending on compiler brand and version, with `clang` generally benefiting the most.
The following benchmark was measured by compressing `enwik9` at level `--ultra -22` (with a 128 MB window size) on a core i7-9700K.
| Compiler version | D. Speed improvement |
| --- | --- |
| gcc-7 | +15% |
| gcc-8 | +10 % |
| gcc-9 | +5% |
| gcc-10 | +1% |
| clang-6 | +21% |
| clang-7 | +16% |
| clang-8 | +16% |
| clang-9 | +18% |
| clang-10 | +16% |
| clang-11 | +15% |
Average decompression speed for “normal” payload is slightly improved too, though the impact is less impressive. Once again, mileage varies depending on exact compiler version, payload, and even compression level. In general, a majority of scenarios see benefits ranging from +1 to +9%. There are also a few outliers here and there, from -4% to +13%. The average gain across all these scenarios stands at ~+4%.
# Library Updates
## Dynamic Library Supports Multithreading by Default
It was already possible to compile `libzstd` with multithreading support. But it was an active operation. By default, the `make` build script would build `libzstd` as a single-thread-only library.
This changes in `v1.5.0`.
Now the dynamic library (typically `libzstd.so.1` on Linux) supports multi-threaded compression by default.
Note that this property is not extended to the static library (typically `libzstd.a` on Linux) because doing so would have impacted the build script of existing client applications (requiring them to add `-pthread` to their recipe), thus potentially breaking their build. In order to avoid this disruption, the static library remains single-threaded by default.
Luckily, this build disruption does not extend to the dynamic library, which can be built with multi-threading support while existing applications linking to `libzstd.so` and expecting only single-thread capabilities will be none the wiser, and remain completely unaffected.
The idea is that starting from `v1.5.0`, applications can _expect_ the dynamic library to support multi-threading should they need it, which will progressively lead to increased adoption of this capability overtime.
That being said, since the locally deployed dynamic library may, or may not, support multi-threading compression, depending on local build configuration, it’s always better to check this capability at runtime. For this goal, it’s enough to check the return value when changing parameter `ZSTD_c_nbWorkers` , and if it results in an error, then multi-threading is not supported.
_Q: What if I prefer to keep the libraries in single-thread mode only ?_
The target `make lib-nomt` will ensure this outcome.
_Q: Actually, I want both static and dynamic library versions to support multi-threading !_
The target `make lib-mt` will generate this outcome.
## Promotions to Stable
Moving up to the higher digit `1.5` signals an opportunity to extend the _stable_ portion of `zstd` public API.
This update is relatively minor, featuring only a few non-controversial newcomers.
`ZSTD_defaultCLevel()` indicates which level is default (applied when selecting level `0`). It completes existing
`ZSTD_minCLevel()` and `ZSTD_maxCLevel()`.
Similarly, `ZSTD_getDictID_fromCDict()` is a straightforward equivalent to already promoted `ZSTD_getDictID_fromDDict()`.
## Deprecations
[Zstd-1.4.0](https://github.com/facebook/zstd/releases/tag/v1.4.0) stabilized a new [advanced API](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L238) which allows users to pass advanced parameters to zstd. We’re now deprecating all the old experimental APIs that are subsumed by the new advanced API. They will be considered for removal in the next Zstd major release zstd-1.6.0. Note that only experimental symbols are impacted. Stable functions, like `ZSTD_initCStream()`, remain fully supported.
The deprecated functions are listed below, together with the migration. All the suggested migrations are stable APIs, meaning that once you migrate, the API will be supported forever. See the documentation for the deprecated functions for more details on how to migrate.
- Functions that migrate to `ZSTD_compress2()` with parameter setters:
* `ZSTD_compress_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469).
* `ZSTD_compress_usingCDict_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469) and [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
- Functions that migrate to `ZSTD_compressStream()` or `ZSTD_compressStream2()` with parameter setters:
* `ZSTD_initCStream_srcSize()`: Use [`ZSTD_CCtx_setPledgedSrcSize()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L471-L486).
* `ZSTD_initCStream_usingDict()`: Use [`ZSTD_CCtx_loadDictionary()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L941-L958).
* `ZSTD_initCStream_usingCDict()`: Use [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
* `ZSTD_initCStream_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469).
* `ZSTD_initCStream_usingCDict_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469) and [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
* `ZSTD_resetCStream()`: Use [`ZSTD_CCtx_reset()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L494-L508) and [`ZSTD_CCtx_setPledgedSrcSize()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L471-L486).
- Functions that are deprecated without replacement. We don’t expect any users of these functions. Please open an issue if you use these and have questions about how to migrate.
* `ZSTD_compressBegin_advanced()`
* `ZSTD_compressBegin_usingCDict_advanced()`
## Header File Locations
Zstd has slightly re-organized the library layout to move all public headers to the top level `lib/` directory. This is for consistency, so all public headers are in `lib/` and all private headers are in a sub-directory. If you build zstd from source, this may affect your build system.
- `lib/common/zstd_errors.h` has moved to `lib/zstd_errors.h`.
- `lib/dictBuilder/zdict.h` has moved to `lib/zdict.h`.
## Single-File Library
We have moved the scripts in `contrib/single_file_libs` to `build/single_file_libs`. These scripts, originally contributed by @cwoffenden, produce a single compilation-unit amalgamation of the zstd library, which can be convenient for integrating Zstandard into other source trees. This move reflects a commitment on our part to support this tool and this pattern of using zstd going forward.
## Windows Release Artifact Format
We are slightly changing the format of the Windows release `.zip` files, to match our other release artifacts. The `.zip` files now bundle everything in a single folder whose name matches the archive name. The contents of that folder exactly match what was previously included in the root of the archive.
## Signed Releases
We have created a [signing key](http://keys.gnupg.net/pks/lookup?op=get&search=0xEF8FE99528B52FFD) for the Zstandard project. This release and all future releases will be signed by this key. See #2520 for discussion.
# Changelog
- api: Various functions promoted from experimental to stable API: ([#2579](https://github.com/facebook/zstd/pull/2579)-[#2581](https://github.com/facebook/zstd/pull/2581), [@senhuang42](https://github.com/senhuang42))
* `ZSTD_defaultCLevel()`
* `ZSTD_getDictID_fromCDict()`
- api: Several experimental functions have been deprecated and will emit a compiler warning ([#2582](https://github.com/facebook/zstd/pull/2582), [@senhuang42](https://github.com/senhuang42))
* `ZSTD_compress_advanced()`
* `ZSTD_compress_usingCDict_advanced()`
* `ZSTD_compressBegin_advanced()`
* `ZSTD_compressBegin_usingCDict_advanced()`
* `ZSTD_initCStream_srcSize()`
* `ZSTD_initCStream_usingDict()`
* `ZSTD_initCStream_usingCDict()`
* `ZSTD_initCStream_advanced()`
* `ZSTD_initCStream_usingCDict_advanced()`
* `ZSTD_resetCStream()`
- api: `ZSTDMT_NBWORKERS_MAX` reduced to 64 for 32-bit environments ([#2643](https://github.com/facebook/zstd/pull/2643), [@Cyan4973](https://github.com/Cyan4973))
- perf: Significant speed improvements for middle compression levels ([#2494](https://github.com/facebook/zstd/pull/2494), [@senhuang42](https://github.com/senhuang42) & [@terrelln](https://github.com/terrelln))
- perf: Block splitter to improve compression ratio, enabled by default for high compression levels ([#2447](https://github.com/facebook/zstd/pull/2447), [@senhuang42](https://github.com/senhuang42))
- perf: Decompression loop refactor, speed improvements on `clang` and for `--long` modes ([#2614](https://github.com/facebook/zstd/pull/2614) [#2630](https://github.com/facebook/zstd/pull/2630), [@Cyan4973](https://github.com/Cyan4973))
- perf: Reduced stack usage during compression and decompression entropy stage ([#2522](https://github.com/facebook/zstd/pull/2522) [#2524](https://github.com/facebook/zstd/pull/2524), [@terrelln](https://github.com/terrelln))
- bug: Make the number of physical CPU cores detection more robust ([#2517](https://github.com/facebook/zstd/pull/2517), [@PaulBone](https://github.com/PaulBone))
- bug: Improve setting permissions of created files ([#2525](https://github.com/facebook/zstd/pull/2525), [@felixhandte](https://github.com/felixhandte))
- bug: Fix large dictionary non-determinism ([#2607](https://github.com/facebook/zstd/pull/2607), [@terrelln](https://github.com/terrelln))
- bug: Fix various dedicated dictionary search bugs ([#2540](https://github.com/facebook/zstd/pull/2540) [#2586](https://github.com/facebook/zstd/pull/2586), [@senhuang42](https://github.com/senhuang42) [@felixhandte](https://github.com/felixhandte))
- bug: Fix non-determinism test failures on Linux i686 ([#2606](https://github.com/facebook/zstd/pull/2606), [@terrelln](https://github.com/terrelln))
- bug: Fix UBSAN error in decompression ([#2625](https://github.com/facebook/zstd/pull/2625), [@terrelln](https://github.com/terrelln))
- bug: Fix superblock compression divide by zero bug ([#2592](https://github.com/facebook/zstd/pull/2592), [@senhuang42](https://github.com/senhuang42))
- bug: Ensure `ZSTD_estimateCCtxSize*()` monotonically increases with compression level ([#2538](https://github.com/facebook/zstd/pull/2538), [@senhuang42](https://github.com/senhuang42))
- doc: Improve `zdict.h` dictionary training API documentation ([#2622](https://github.com/facebook/zstd/pull/2622), [@terrelln](https://github.com/terrelln))
- doc: Note that public `ZSTD_free*()` functions accept NULL pointers ([#2521](https://github.com/facebook/zstd/pull/2521), [@animalize](https://github.com/animalize))
- doc: Add style guide docs for open source contributors ([#2626](https://github.com/facebook/zstd/pull/2626), [@Cyan4973](https://github.com/Cyan4973))
- tests: Better regression test coverage for different dictionary modes ([#2559](https://github.com/facebook/zstd/pull/2559), [@senhuang42](https://github.com/senhuang42))
- tests: Better test coverage of index reduction ([#2603](https://github.com/facebook/zstd/pull/2603), [@terrelln](https://github.com/terrelln))
- tests: OSS-Fuzz coverage for seekable format ([#2617](https://github.com/facebook/zstd/pull/2617), [@senhuang42](https://github.com/senhuang42))
- tests: Test coverage for ZSTD threadpool API ([#2604](https://github.com/facebook/zstd/pull/2604), [@senhuang42](https://github.com/senhuang42))
- build: Dynamic library built multithreaded by default ([#2584](https://github.com/facebook/zstd/pull/2584), [@senhuang42](https://github.com/senhuang42))
- build: Move `zstd_errors.h` and `zdict.h` to `lib/` root ([#2597](https://github.com/facebook/zstd/pull/2597), [@terrelln](https://github.com/terrelln))
- build: Single file library build script moved to `build/` directory ([#2618](https://github.com/facebook/zstd/pull/2618), [@felixhandte](https://github.com/felixhandte))
- build: Allow `ZSTDMT_JOBSIZE_MIN` to be configured at compile-time, reduce default to 512KB ([#2611](https://github.com/facebook/zstd/pull/2611), [@Cyan4973](https://github.com/Cyan4973))
- build: Fixed Meson build ([#2548](https://github.com/facebook/zstd/pull/2548), [@SupervisedThinking](https://github.com/SupervisedThinking) & [@kloczek](https://github.com/kloczek))
- build: `ZBUFF_*()` is no longer built by default ([#2583](https://github.com/facebook/zstd/pull/2583), [@senhuang42](https://github.com/senhuang42))
- build: Fix excessive compiler warnings with clang-cl and CMake ([#2600](https://github.com/facebook/zstd/pull/2600), [@nickhutchinson](https://github.com/nickhutchinson))
- build: Detect presence of `md5` on Darwin ([#2609](https://github.com/facebook/zstd/pull/2609), [@felixhandte](https://github.com/felixhandte))
- build: Avoid SIGBUS on armv6 ([#2633](https://github.com/facebook/zstd/pull/2633), @bmwiedmann)
- cli: `--progress` flag added to always display progress bar ([#2595](https://github.com/facebook/zstd/pull/2595), [@senhuang42](https://github.com/senhuang42))
- cli: Allow reading from block devices with `--force` ([#2613](https://github.com/facebook/zstd/pull/2613), [@felixhandte](https://github.com/felixhandte))
- cli: Fix CLI filesize display bug ([#2550](https://github.com/facebook/zstd/pull/2550), [@Cyan4973](https://github.com/Cyan4973))
- cli: Fix windows CLI `--filelist` end-of-line bug ([#2620](https://github.com/facebook/zstd/pull/2620), [@Cyan4973](https://github.com/Cyan4973))
- contrib: Various fixes for linux kernel patch ([#2539](https://github.com/facebook/zstd/pull/2539), [@terrelln](https://github.com/terrelln))
- contrib: Seekable format - Decompression hanging edge case fix ([#2516](https://github.com/facebook/zstd/pull/2516), [@senhuang42](https://github.com/senhuang42))
- contrib: Seekable format - New seek table-only API ([#2113](https://github.com/facebook/zstd/pull/2113) [#2518](https://github.com/facebook/zstd/pull/2518), [@mdittmer](https://github.com/mdittmer) [@Cyan4973](https://github.com/Cyan4973))
- contrib: Seekable format - Fix seek table descriptor check when loading ([#2534](https://github.com/facebook/zstd/pull/2534), [@foxeng](https://github.com/foxeng))
- contrib: Seekable format - Decompression fix for large offsets, ([#2594](https://github.com/facebook/zstd/pull/2594), [@azat](https://github.com/azat))
- misc: Automatically published release tarballs available on Github ([#2535](https://github.com/facebook/zstd/pull/2535), [@felixhandte](https://github.com/felixhandte))
2021-05-14T16:01:54+00:00zstd v1.5.1zstd v1.5.12021-12-21T00:42:34+00:00__Notice__ : it has been brought to our attention that the `v1.5.1` library might be built with an executable stack on non-`x64` architectures, which could end up being flagged as problematic by some systems with thorough security settings which disallow executable stack. We are currently reviewing the issue. Be aware of it if you build `libzstd` for non-`x64` architecture.
Zstandard v1.5.1 is a maintenance release, bringing a good number of small refinements to the project. It also offers a welcome crop of performance improvements, as detailed below.
## Performance Improvements
### Speed improvements for fast compression (levels 1–4)
PRs #2749, #2774, and #2921 refactor single-segment compression for `ZSTD_fast` and `ZSTD_dfast`, which back compression levels 1 through 4 (as well as the negative compression levels). Speedups in the ~3-5% range are observed. In addition, the compression ratio of `ZSTD_dfast` (levels 3 and 4) is slightly improved.
### Rebalanced middle compression levels
`v1.5.0` introduced major speed improvements for mid-level compression (from 5 to 12), while preserving roughly similar compression ratio. As a consequence, the speed scale became tilted towards faster speed. Unfortunately, the difference between successive levels was no longer regular, and there is a large performance gap just after the impacted range, between levels 12 and 13.
`v1.5.1` tries to rebalance parameters so that compression levels can be roughly associated to their former speed budget. Consequently, `v1.5.1` mid compression levels feature speeds closer to former `v1.4.9` (though still sensibly faster) and receive in exchange an improved compression ratio, as shown in below graph.


Note that, since middle levels only experience a rebalancing, save some special cases, no significant performance differences between versions `v1.5.0` and `v1.5.1` should be expected: levels merely occupy different positions on the same curve. The situation is a bit different for fast levels (1-4), for which `v1.5.1` delivers a small but consistent performance benefit on all platforms, as described in previous paragraph.
### Huffman Improvements
Our Huffman code was significantly revamped in this release. Both encoding and decoding speed were improved. Additionally, encoding speed for small inputs was improved even further. Speed is measured on the Silesia corpus by compressing with level 1 and extracting the literals left over after compression. Then compressing and decompressing the literals from each block. Measurements are done on an Intel i9-9900K @ 3.6 GHz.
| Compiler | Scenario | v1.5.0 Speed | v1.5.1 Speed | Delta |
|----------|-------------------------------------|--------------|--------------|--------|
| gcc-11 | Literal compression - 128KB block | 748 MB/s | 927 MB/s | +23.9% |
| clang-13 | Literal compression - 128KB block | 810 MB/s | 927 MB/s | +14.4% |
| gcc-11 | Literal compression - 4KB block | 223 MB/s | 321 MB/s | +44.0% |
| clang-13 | Literal compression - 4KB block | 224 MB/s | 310 MB/s | +38.2% |
| gcc-11 | Literal decompression - 128KB block | 1164 MB/s | 1500 MB/s | +28.8% |
| clang-13 | Literal decompression - 128KB block | 1006 MB/s | 1504 MB/s | +49.5% |
Overall impact on (de)compression speed depends on the compressibility of the data. Compression speed improves from 1-4%, and decompression speed improves from 5-15%.
PR #2722 implements the Huffman decoder in assembly for x86-64 with BMI2 enabled. We detect BMI2 support at runtime, so this speedup applies to all x86-64 builds running on CPUs that support BMI2. This improves Huffman decoding speed by about 40%, depending on the scenario. PR #2733 improves Huffman encoding speed by 10% for clang and 20% for gcc. PR #2732 drastically speeds up the `HUF_sort()` function, which speeds up Huffman tree building for compression. This is a significant speed boost for small inputs, measuring in at a 40% improvement for 4K inputs.
## Binary Size and Build Speed
`zstd` binary size grew significantly in `v1.5.0` due to the new code added for middle compression level speed optimizations. In this release we recover the binary size, and in the process also significantly speed up builds, especially with sanitizers enabled.
Measured on x86-64 compiled with `-O3` we measure `libzstd.a` size. We regained 161 KB of binary size on gcc, and 293 KB of binary size on clang. Note that these binary sizes are listed for the whole library, optimized for speed over size. The decoder only, with size saving options enabled, and compiled with `-Os` or `-Oz` can be much smaller.
| Version | gcc-11 size | clang-13 size |
|---------|-------------|---------------|
| v1.5.1 | 1177 KB | 1167 KB |
| v1.5.0 | 1338 KB | 1460 KB |
| v1.4.9 | 1137 KB | 1151 KB |
## Change log
### Featured user-visible changes
- perf: rebalanced compression levels, to better match intended speed/level curve, by @senhuang42 and @cyan4973
- perf: faster huffman decoder, using `x64` assembly, by @terrelln
- perf: slightly faster high speed modes (strategies fast & dfast), by @felixhandte
- perf: smaller binary size and faster compilation times, by @terrelln and @nolange
- perf: new row64 mode, used notably at highest `lazy2` levels 11-12, by @senhuang42
- perf: faster mid-level compression speed in presence of highly repetitive patterns, by @senhuang42
- perf: minor compression ratio improvements for small data at high levels, by @cyan4973
- perf: reduced stack usage (mostly useful for Linux Kernel), by @terrelln
- perf: faster compression speed on incompressible data, by @bindhvo
- perf: on-demand reduced `ZSTD_DCtx` state size, using build macro `ZSTD_DECODER_INTERNAL_BUFFER`, at a small cost of performance, by @bindhvo
- build: allows hiding static symbols in the dynamic library, using build macro, by @skitt
- build: support for `m68k` (Motorola 68000's), by @cyan4973
- build: improved `AIX` support, by @Helflym
- build: improved meson unofficial build, by @eli-schwartz
- cli : fix : forward `mtime` to output file, by @felixhandte
- cli : custom memory limit when training dictionary (#2925), by @embg
- cli : report advanced parameters information when compressing in very verbose mode (`-vv`), by @Svetlitski-FB
- cli : advanced commands in the form `--long-param=` can accept negative value arguments, by @binhdvo
### PR full list
* Add determinism fuzzers and fix rare determinism bugs by @terrelln in https://github.com/facebook/zstd/pull/2648
* `ZSTD_VecMask_next`: fix incorrect variable name in fallback code path by @dnelson-1901 in https://github.com/facebook/zstd/pull/2657
* improve tar compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/2660
* Enable SSE2 compression path to work on MSVC by @TrianglesPCT in https://github.com/facebook/zstd/pull/2653
* Fix CircleCI Config to Fully Remove `publish-github-release` Job by @felixhandte in https://github.com/facebook/zstd/pull/2649
* [CI] Fix zlib-wrapper test by @senhuang42 in https://github.com/facebook/zstd/pull/2668
* [CI] Add ARM tests back into CI by @senhuang42 in https://github.com/facebook/zstd/pull/2667
* [trace] Refine the ZSTD_HAVE_WEAK_SYMBOLS detection by @terrelln in https://github.com/facebook/zstd/pull/2674
* [CI][1/2] Re-do the github actions workflows, migrate various travis and appveyor tests. by @senhuang42 in https://github.com/facebook/zstd/pull/2675
* Make GH Actions CI tests run apt-get update before apt-get install by @senhuang42 in https://github.com/facebook/zstd/pull/2682
* Add arm64 fuzz test to travis by @senhuang42 in https://github.com/facebook/zstd/pull/2686
* Add ldm and block splitter auto-enable to old api by @senhuang42 in https://github.com/facebook/zstd/pull/2684
* Add documentation for --patch-from by @binhdvo in https://github.com/facebook/zstd/pull/2693
* Make regression test run on every PR by @senhuang42 in https://github.com/facebook/zstd/pull/2691
* Initialize "potentially uninitialized" pointers. by @wolfpld in https://github.com/facebook/zstd/pull/2654
* Flatten `ZSTD_row_getMatchMask` by @aqrit in https://github.com/facebook/zstd/pull/2681
* Update `README` for Travis CI Badge by @gauthamkrishna9991 in https://github.com/facebook/zstd/pull/2700
* Fuzzer test with no intrinsics on `S390x` (big endian) by @senhuang42 in https://github.com/facebook/zstd/pull/2678
* Fix `--progress` flag to properly control progress display and default … by @binhdvo in https://github.com/facebook/zstd/pull/2698
* [bug] Fix entropy repeat mode bug by @senhuang42 in https://github.com/facebook/zstd/pull/2697
* Format File Sizes Human-Readable in the cli by @felixhandte in https://github.com/facebook/zstd/pull/2702
* Add support for negative values in advanced flags by @binhdvo in https://github.com/facebook/zstd/pull/2705
* [fix] Add missing bounds checks during compression by @terrelln in https://github.com/facebook/zstd/pull/2709
* Add API for fetching skippable frame content by @binhdvo in https://github.com/facebook/zstd/pull/2708
* Add option to use logical cores for default threads by @binhdvo in https://github.com/facebook/zstd/pull/2710
* lib/Makefile: Fix small typo in `ZSTD_FORCE_DECOMPRESS_*` build macros by @luisdallos in https://github.com/facebook/zstd/pull/2714
* [RFC] Add internal API for converting `ZSTD_Sequence` into `seqStore` by @senhuang42 in https://github.com/facebook/zstd/pull/2715
* Optimize zstd decompression by another x% by @danlark1 in https://github.com/facebook/zstd/pull/2689
* Include what you use in `zstd_ldm_geartab` by @danlark1 in https://github.com/facebook/zstd/pull/2719
* [trace] remove zstd_trace.c reference from freestanding by @heitbaum in https://github.com/facebook/zstd/pull/2655
* Remove folder when done with test by @senhuang42 in https://github.com/facebook/zstd/pull/2720
* Proactively skip huffman compression based on sampling where non-comp… by @binhdvo in https://github.com/facebook/zstd/pull/2717
* Add support for MCST LCC compiler by @makise-homura in https://github.com/facebook/zstd/pull/2725
* [bug-fix] Fix a determinism bug with the DUBT by @terrelln in https://github.com/facebook/zstd/pull/2726
* Fix DDSS Load by @felixhandte in https://github.com/facebook/zstd/pull/2729
* `Z_PREFIX zError` function by @koalabearguo in https://github.com/facebook/zstd/pull/2707
* `pzstd`: fix linking for static builds by @jonringer in https://github.com/facebook/zstd/pull/2724
* [HUF] Improve Huffman encoding speed by @terrelln in https://github.com/facebook/zstd/pull/2733
* [HUF] Improve Huffman sorting algorithm by @senhuang42 in https://github.com/facebook/zstd/pull/2732
* Set `mtime` on Output Files by @felixhandte in https://github.com/facebook/zstd/pull/2742
* [RFC] Rebalance compression levels by @senhuang42 in https://github.com/facebook/zstd/pull/2692
* Improve branch misses on FSE symbol spreading by @senhuang42 in https://github.com/facebook/zstd/pull/2750
* make `ZSTD_HASHLOG3_MAX` private by @Cyan4973 in https://github.com/facebook/zstd/pull/2752
* meson fixups by @eli-schwartz in https://github.com/facebook/zstd/pull/2746
* [easy] Fix zstd bench error message by @senhuang42 in https://github.com/facebook/zstd/pull/2753
* Reduce test time on TravisCI by @Cyan4973 in https://github.com/facebook/zstd/pull/2757
* added `qemu` tests by @Cyan4973 in https://github.com/facebook/zstd/pull/2758
* Add 8 bytes to FSE_buildCTable wksp by @senhuang42 in https://github.com/facebook/zstd/pull/2761
* minor rebalancing of level 13 by @Cyan4973 in https://github.com/facebook/zstd/pull/2762
* Improve compile speed and binary size in `opt` by @senhuang42 in https://github.com/facebook/zstd/pull/2763
* [easy] Fix patch-from help msg typo by @senhuang42 in https://github.com/facebook/zstd/pull/2769
* Pipelined Implementation of `ZSTD_fast` (~+5% Speed) by @felixhandte in https://github.com/facebook/zstd/pull/2749
* meson: fix type error for integer option by @eli-schwartz in https://github.com/facebook/zstd/pull/2775
* Fix dictionary training huffman segfault and small speed improvement by @senhuang42 in https://github.com/facebook/zstd/pull/2773
* [rsyncable] Ensure `ZSTD_compressBound()` is respected by @terrelln in https://github.com/facebook/zstd/pull/2776
* Improve optimal parser performance on small data by @Cyan4973 in https://github.com/facebook/zstd/pull/2771
* [rsyncable] Fix test failures by @terrelln in https://github.com/facebook/zstd/pull/2777
* Revert opt outlining change by @senhuang42 in https://github.com/facebook/zstd/pull/2778
* [build] Add support for ASM files in `Make` + `CMake` by @terrelln in https://github.com/facebook/zstd/pull/2783
* add `msvc2019` to build.generic.cmd by @animalize in https://github.com/facebook/zstd/pull/2787
* [fuzzer] Add Huffman decompression fuzzer by @terrelln in https://github.com/facebook/zstd/pull/2784
* Assembly implementation of 4X1 & 4X2 Huffman by @terrelln in https://github.com/facebook/zstd/pull/2722
* [huf] Fix compilation when `DYNAMIC_BMI2=0 && BMI2` is supported by @terrelln in https://github.com/facebook/zstd/pull/2791
* Use new paramSwitch enum for row matchfinder and block splitter by @senhuang42 in https://github.com/facebook/zstd/pull/2788
* Fix `NCountWriteBound` by @senhuang42 in https://github.com/facebook/zstd/pull/2779
* [contrib][linux] Fix up SPDX license identifiers by @terrelln in https://github.com/facebook/zstd/pull/2794
* [contrib][linux] Reduce stack usage by 80 bytes by @terrelln in https://github.com/facebook/zstd/pull/2795
* Reduce stack usage of block splitter by @senhuang42 in https://github.com/facebook/zstd/pull/2780
* minor: constify `MatchState*` parameter when possible by @Cyan4973 in https://github.com/facebook/zstd/pull/2797
* [build] Fix oss-fuzz build with the dataflow sanitizer by @terrelln in https://github.com/facebook/zstd/pull/2799
* [lib] Make lib compatible with `-Wfall-through` excepting legacy by @terrelln in https://github.com/facebook/zstd/pull/2796
* [contrib][linux] Fix build after introducing ASM HUF implementation by @solbjorn in https://github.com/facebook/zstd/pull/2790
* Smaller code with disabled features by @nolange in https://github.com/facebook/zstd/pull/2805
* [huf] Fix OSS-Fuzz assert by @terrelln in https://github.com/facebook/zstd/pull/2808
* Skip most long matches in lazy hash table update by @senhuang42 in https://github.com/facebook/zstd/pull/2755
* add missing BUNDLE DESTINATION by @3nids in https://github.com/facebook/zstd/pull/2810
* [contrib][linux] Fix `-Wundef` inside Linux kernel tree by @solbjorn in https://github.com/facebook/zstd/pull/2802
* [contrib][linux-kernel] Add standard warnings and `-Werror` to CI by @terrelln in https://github.com/facebook/zstd/pull/2803
* Add AIX support in Makefile by @Helflym in https://github.com/facebook/zstd/pull/2747
* Limit train samples by @stanjo74 in https://github.com/facebook/zstd/pull/2809
* [multiple-ddicts] Fix `NULL` checks by @terrelln in https://github.com/facebook/zstd/pull/2817
* [ldm] Fix `ZSTD_c_ldmHashRateLog` bounds check by @terrelln in https://github.com/facebook/zstd/pull/2819
* [binary-tree] Fix underflow of `nbCompares` by @terrelln in https://github.com/facebook/zstd/pull/2820
* Enhance streaming_compression examples. by @marxin in https://github.com/facebook/zstd/pull/2813
* Pipelined Implementation of `ZSTD_dfast` by @felixhandte in https://github.com/facebook/zstd/pull/2774
* Fix a C89 error in msvc by @animalize in https://github.com/facebook/zstd/pull/2800
* [asm] Switch to C style comments by @terrelln in https://github.com/facebook/zstd/pull/2825
* Support thread pool section in HTML documentation. by @marxin in https://github.com/facebook/zstd/pull/2822
* Reduce size of `dctx` by reutilizing dst buffer by @binhdvo in https://github.com/facebook/zstd/pull/2751
* [lazy] Speed up compilation times by @terrelln in https://github.com/facebook/zstd/pull/2828
* separate compression level tables into their own file by @Cyan4973 in https://github.com/facebook/zstd/pull/2830
* minor : change build macro to `ZSTD_DECODER_INTERNAL_BUFFER` by @Cyan4973 in https://github.com/facebook/zstd/pull/2829
* Fix oss fuzz test error by @binhdvo in https://github.com/facebook/zstd/pull/2837
* Move mingw tests from appveyor to github actions by @binhdvo in https://github.com/facebook/zstd/pull/2838
* Improvements to verbose mode output by @Svetlitski-FB in https://github.com/facebook/zstd/pull/2839
* Use unused functions to appease Visual Studio by @senhuang42 in https://github.com/facebook/zstd/pull/2846
* Backport zstd patch from LKML by @terrelln in https://github.com/facebook/zstd/pull/2849
* Fix fullbench CI failure by @binhdvo in https://github.com/facebook/zstd/pull/2851
* Fix Determinism Bug: Avoid Reducing Indices to Reserved Values by @felixhandte in https://github.com/facebook/zstd/pull/2850
* `ZSTD_copy16()` uses ZSTD_memcpy() by @animalize in https://github.com/facebook/zstd/pull/2836
* Display command line parameters with concrete values in verbose mode by @Svetlitski-FB in https://github.com/facebook/zstd/pull/2847
* Reduce function size in fast & dfast by @terrelln in https://github.com/facebook/zstd/pull/2863
* [linux-kernel] Don't inline function in `zstd_opt.c` by @terrelln in https://github.com/facebook/zstd/pull/2864
* Remove executable flag from GNU_STACK segment by @ko-zu in https://github.com/facebook/zstd/pull/2857
* [linux-kernel] Don't add `-O3` to `CFLAGS` by @terrelln in https://github.com/facebook/zstd/pull/2866
* Support Swift Package Manager by @cntrump in https://github.com/facebook/zstd/pull/2858
* Determinism: Avoid Mapping Window into Reserved Indices during Reduction by @felixhandte in https://github.com/facebook/zstd/pull/2869
* Clarify documentation for `-c` by @binhdvo in https://github.com/facebook/zstd/pull/2883
* Fix build for cygwin/bsd by @binhdvo in https://github.com/facebook/zstd/pull/2882
* Move visual studio tests from per-release to per-PR by @senhuang42 in https://github.com/facebook/zstd/pull/2845
* Fix SPM warning: umbrella header for module 'libzstd' does not include header 'xxx.h' by @cntrump in https://github.com/facebook/zstd/pull/2872
* Add detection when compiling with Clang and Ninja under Windows by @jannkoeker in https://github.com/facebook/zstd/pull/2877
* [contrib][pzstd] Fix build issue with gcc-5 by @terrelln in https://github.com/facebook/zstd/pull/2889
* [bmi2] Add `lzcnt` and `bmi` target attributes by @terrelln in https://github.com/facebook/zstd/pull/2888
* [test] Test that the exec-stack bit isn't set on libzstd.so by @terrelln in https://github.com/facebook/zstd/pull/2886
* Solve the bug of extra output newline character by @15596858998 in https://github.com/facebook/zstd/pull/2876
* [zdict] Remove `ZDICT_CONTENTSIZE_MIN` restriction for `ZDICT_finalizeDictionary` by @terrelln in https://github.com/facebook/zstd/pull/2887
* Explicitly hide static symbols by @skitt in https://github.com/facebook/zstd/pull/2501
* Makefile: sort all wildcard file list expansions by @kanavin in https://github.com/facebook/zstd/pull/2895
* merge #2501 by @Cyan4973 in https://github.com/facebook/zstd/pull/2894
* Makefile: fix build for mingw by @sapiippo in https://github.com/facebook/zstd/pull/2687
* [CircleCI] Fix short-tests-0 by @terrelln in https://github.com/facebook/zstd/pull/2892
* Zstandard compiles and run on `m68k` cpus by @Cyan4973 in https://github.com/facebook/zstd/pull/2896
* Improve zstd_opt build speed and size by @terrelln in https://github.com/facebook/zstd/pull/2898
* [CI] Add `cmake` windows build by @terrelln in https://github.com/facebook/zstd/pull/2900
* Disable Multithreading in CMake Builds for Android by @felixhandte in https://github.com/facebook/zstd/pull/2899
* Avoid Using Deprecated Functions in Deprecated Code by @felixhandte in https://github.com/facebook/zstd/pull/2897
* [asm] Share portability macros and restrict ASM further by @terrelln in https://github.com/facebook/zstd/pull/2893
* fixbug CLI's -D fails when the argument is not a regular file by @15596858998 in https://github.com/facebook/zstd/pull/2890
* Apply `FORCE_MEMORY_ACCESS=1` to legacy by @Hello71 in https://github.com/facebook/zstd/pull/2907
* [lib] Fix libzstd.pc for lib-mt builds by @ericonr in https://github.com/facebook/zstd/pull/2659
* Imply `-q` when stderr is not a tty by @binhdvo in https://github.com/facebook/zstd/pull/2884
* Fix Up #2659; Build `libzstd.pc` Whenever Building the Lib on Unix by @felixhandte in https://github.com/facebook/zstd/pull/2912
* Remove possible `NULL` pointer addition by @terrelln in https://github.com/facebook/zstd/pull/2916
* updated `xxHash` to latest `v0.8.1` by @Cyan4973 in https://github.com/facebook/zstd/pull/2914
* Reject Irregular Dictionary Files by @felixhandte in https://github.com/facebook/zstd/pull/2910
* `x32` compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/2922
* typo: Small spelling mistake in example by @IAL32 in https://github.com/facebook/zstd/pull/2923
* add test case by @15596858998 in https://github.com/facebook/zstd/pull/2905
* Stagger Stepping in Negative Levels by @felixhandte in https://github.com/facebook/zstd/pull/2921
* Fix performance degradation with `-m32` by @binhdvo in https://github.com/facebook/zstd/pull/2926
* Reduce tables to 8bit by @nolange in https://github.com/facebook/zstd/pull/2930
* simplify SSE implementation of row_lazy match finder by @Cyan4973 in https://github.com/facebook/zstd/pull/2929
* Allow user to specify memory limit for dictionary training by @embg in https://github.com/facebook/zstd/pull/2925
* fixed incorrect rowlog initialization by @Cyan4973 in https://github.com/facebook/zstd/pull/2931
* rebalance lazy compression levels by @Cyan4973 in https://github.com/facebook/zstd/pull/2934
### New Contributors
* @dnelson-1901 made their first contribution in https://github.com/facebook/zstd/pull/2657
* @TrianglesPCT made their first contribution in https://github.com/facebook/zstd/pull/2653
* @binhdvo made their first contribution in https://github.com/facebook/zstd/pull/2693
* @wolfpld made their first contribution in https://github.com/facebook/zstd/pull/2654
* @aqrit made their first contribution in https://github.com/facebook/zstd/pull/2681
* @gauthamkrishna9991 made their first contribution in https://github.com/facebook/zstd/pull/2700
* @luisdallos made their first contribution in https://github.com/facebook/zstd/pull/2714
* @danlark1 made their first contribution in https://github.com/facebook/zstd/pull/2689
* @heitbaum made their first contribution in https://github.com/facebook/zstd/pull/2655
* @makise-homura made their first contribution in https://github.com/facebook/zstd/pull/2725
* @koalabearguo made their first contribution in https://github.com/facebook/zstd/pull/2707
* @jonringer made their first contribution in https://github.com/facebook/zstd/pull/2724
* @eli-schwartz made their first contribution in https://github.com/facebook/zstd/pull/2746
* @abxhr made their first contribution in https://github.com/facebook/zstd/pull/2798
* @solbjorn made their first contribution in https://github.com/facebook/zstd/pull/2790
* @nolange made their first contribution in https://github.com/facebook/zstd/pull/2805
* @3nids made their first contribution in https://github.com/facebook/zstd/pull/2810
* @Helflym made their first contribution in https://github.com/facebook/zstd/pull/2747
* @stanjo74 made their first contribution in https://github.com/facebook/zstd/pull/2809
* @Svetlitski-FB made their first contribution in https://github.com/facebook/zstd/pull/2839
* @cntrump made their first contribution in https://github.com/facebook/zstd/pull/2858
* @rex4539 made their first contribution in https://github.com/facebook/zstd/pull/2856
* @jannkoeker made their first contribution in https://github.com/facebook/zstd/pull/2877
* @yoniko made their first contribution in https://github.com/facebook/zstd/pull/2885
* @15596858998 made their first contribution in https://github.com/facebook/zstd/pull/2876
* @kanavin made their first contribution in https://github.com/facebook/zstd/pull/2895
* @sapiippo made their first contribution in https://github.com/facebook/zstd/pull/2687
* @supperPants made their first contribution in https://github.com/facebook/zstd/pull/2891
* @Hello71 made their first contribution in https://github.com/facebook/zstd/pull/2907
* @ericonr made their first contribution in https://github.com/facebook/zstd/pull/2659
* @IAL32 made their first contribution in https://github.com/facebook/zstd/pull/2923
* @embg made their first contribution in https://github.com/facebook/zstd/pull/2925
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.0...v1.5.12021-12-21T00:42:34+00:00zstd v1.5.2zstd v1.5.22022-01-20T21:54:37+00:00Zstandard v1.5.2 is a bug-fix release, addressing issues that were raised with the v1.5.1 release.
In particular, as a side-effect of the inclusion of assembly code in our source tree, binary artifacts were being marked as needing an executable stack on non-amd64 architectures. This release corrects that issue. More context is available in #2963.
This release also corrects a performance regression that was introduced in v1.5.0 that slows down compression of very small data when using the streaming API. Issue #2966 tracks that topic.
In addition there are a number of smaller improvements and fixes.
## Full Changelist
* Fix zstd-static output name with MINGW/Clang by @MehdiChinoune in https://github.com/facebook/zstd/pull/2947
* storeSeq & mlBase : clarity refactoring by @Cyan4973 in https://github.com/facebook/zstd/pull/2954
* Fix mini typo by @fwessels in https://github.com/facebook/zstd/pull/2960
* Refactor offset+repcode sumtype by @Cyan4973 in https://github.com/facebook/zstd/pull/2962
* meson: fix MSVC support by @eli-schwartz in https://github.com/facebook/zstd/pull/2951
* fix performance issue in scenario #2966 (part 1) by @Cyan4973 in https://github.com/facebook/zstd/pull/2969
* [meson] Explicitly disable assembly for non clang/gcc copmilers by @terrelln in https://github.com/facebook/zstd/pull/2972
* Mark Huffman Decoder Assembly `noexecstack` on All Architectures by @felixhandte in https://github.com/facebook/zstd/pull/2964
* Improve Module Map File by @felixhandte in https://github.com/facebook/zstd/pull/2953
* Remove Dependencies to Allow the Zstd Binary to Dynamically Link to the Library by @felixhandte in https://github.com/facebook/zstd/pull/2977
* [opt] Fix oss-fuzz bug in optimal parser by @terrelln in https://github.com/facebook/zstd/pull/2980
* [license] Fix license header of huf_decompress_amd64.S by @terrelln in https://github.com/facebook/zstd/pull/2981
* Fix `stderr` progress logging for decompression by @terrelln in https://github.com/facebook/zstd/pull/2982
* Fix tar test cases by @sunwire in https://github.com/facebook/zstd/pull/2956
* Fixup MSVC source file inclusion for cmake builds by @hmaarrfk in https://github.com/facebook/zstd/pull/2957
* x86-64: Hide internal assembly functions by @hjl-tools in https://github.com/facebook/zstd/pull/2993
* Prepare v1.5.2 by @felixhandte in https://github.com/facebook/zstd/pull/2987
* Documentation and minor refactor to clarify MT memory management by @embg in https://github.com/facebook/zstd/pull/3000
* Avoid updating timestamps when the destination is `stdout` by @floppym in https://github.com/facebook/zstd/pull/2998
* [build][asm] Pass ASFLAGS to the assembler instead of CFLAGS by @terrelln in https://github.com/facebook/zstd/pull/3009
* Update CI documentation by @embg in https://github.com/facebook/zstd/pull/2999
## New Contributors
* @MehdiChinoune made their first contribution in https://github.com/facebook/zstd/pull/2947
* @fwessels made their first contribution in https://github.com/facebook/zstd/pull/2960
* @sunwire made their first contribution in https://github.com/facebook/zstd/pull/2956
* @hmaarrfk made their first contribution in https://github.com/facebook/zstd/pull/2957
* @floppym made their first contribution in https://github.com/facebook/zstd/pull/2998
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.1...v1.5.22022-01-20T21:54:37+00:00zstd v1.5.4zstd v1.5.42023-02-10T00:55:48+00:00Zstandard `v1.5.4` is a pretty big release benefiting from one year of work, spread over > 650 commits. It offers significant performance improvements across multiple scenarios, as well as new features (detailed below). There is a crop of little bug fixes too, a few ones targeting the 32-bit mode are important enough to make this release a recommended upgrade.
### Various Speed improvements
This release has accumulated a number of scenario-specific improvements, that cumulatively benefit a good portion of installed base in one way or another.
Among the easier ones to describe, the repository has received several contributions for `arm` optimizations, notably from @JunHe77 and @danlark1. And @terrelln has improved decompression speed for non-x64 systems, including `arm`. The combination of this work is visible in the following example, using an M1-Pro (`aarch64` architecture) :
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| M1 Pro | decompress | `silesia.tar` | 1370 MB/s | 1480 MB/s | + 8% |
| Galaxy S22 | decompress | `silesia.tar` | 1150 MB/s | 1200 MB/s | + 4% |
Middle compression levels (5-12) receive some care too, with @terrelln improving the dispatch engine, and @danlark1 offering `NEON` optimizations. Exact speed up vary depending on platform, cpu, compiler, and compression level, though one can expect gains ranging from +1 to +10% depending on scenarios.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | ---:| ---:| --- |
| i7-9700k | compress -6 | `silesia.tar` | 110 MB/s | 121 MB/s | +10%
| Galaxy S22 | compress -6 | `silesia.tar` | 98 MB/s | 103 MB/s | +5%
| M1 Pro | compress -6 | `silesia.tar` | 122 MB/s | 130 MB/s | +6.5%
| i7-9700k | compress -9 | `silesia.tar` | 64 MB/s | 70 MB/s | +9.5%
| Galaxy S22 | compress -9 | `silesia.tar` | 51 MB/s | 52 MB/s | +1%
| M1 Pro | compress -9 | `silesia.tar` | 77 MB/s | 86 MB/s | +11.5%
| i7-9700k | compress -12 | `silesia.tar` | 31.6 MB/s | 31.8 MB/s | +0.5%
| Galaxy S22 | compress -12 | `silesia.tar` | 20.9 MB/s | 22.1 MB/s | +5%
| M1 Pro | compress -12 | `silesia.tar` | 36.1 MB/s | 39.7 MB/s | +10%
Speed of the streaming compression interface has been improved by @embg in scenarios involving large files (where size is a multiple of the `windowSize` parameter). The improvement is mostly perceptible at high speeds (i.e. ~level 1). In the following sample, the measurement is taken directly at `ZSTD_compressStream()` function call, using a dedicated benchmark tool `tests/fullbench`.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| i7-9700k | `ZSTD_compressStream()` -1 | `silesia.tar` | 392 MB/s | 429 MB/s | +9.5% |
| Galaxy S22 | `ZSTD_compressStream()` -1 | `silesia.tar` | 380 MB/s | 430 MB/s | +13% |
| M1 Pro | `ZSTD_compressStream()` -1 | `silesia.tar` | 476 MB/s | 539 MB/s | +13% |
Finally, dictionary compression speed has received a good boost by @embg. Exact outcome varies depending on system and corpus. The following result is achieved by cutting the `enwik8` compression corpus into 1KB blocks, generating a dictionary from these blocks, and then benchmarking the compression speed at level 1.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| i7-9700k | dictionary compress | `enwik8` -B1K | 125 MB/s | 165 MB/s | +32% |
| Galaxy S22 | dictionary compress | `enwik8` -B1K | 138 MB/s | 166 MB/s | +20% |
| M1 Pro | dictionary compress | `enwik8` -B1K | 155 MB/s | 195 MB/s | +25 % |
There are a few more scenario-specifics improvements listed in the `changelog` section below.
### I/O Performance improvements
The 1.5.4 release improves IO performance of `zstd` CLI, by using system buffers (`macos`) and adding a new asynchronous I/O capability, enabled by default on large files (when threading is available). The user can also explicitly control this capability with the `--[no-]asyncio` flag . These new threads remove the need to block on IO operations. The impact is mostly noticeable when decompressing large files (>= a few MBs), though exact outcome depends on environment and run conditions.
Decompression speed gets significant gains due to its single-threaded serial nature and the high speeds involved. In some cases we observe up to double performance improvement (local Mac machines) and a wide +15-45% benefit on Intel Linux servers (see table for details).
On the compression side of things, we’ve measured up to 5% improvements. The impact is lower because compression is already partially asynchronous via the internal MT mode (see release [v1.3.4](https://github.com/facebook/zstd/releases/tag/v1.3.4)).
The following table shows the elapsed run time for decompressions of `silesia` and `enwik8` on several platforms - some Skylake-era Linux servers and an M1 MacbookPro. It compares the time it takes for version `v1.5.2` to version `v1.5.4` with asyncio on and off.
platform | corpus | `v1.5.2` | `v1.5.4-no-asyncio` | `v1.5.4` | Improvement
-- | -- | -- | -- | -- | --
Xeon D-2191A CentOS8 | `enwik8` | 280 MB/s | 280 MB/s | 324 MB/s | +16%
Xeon D-2191A CentOS8 | `silesia.tar` | 303 MB/s | 302 MB/s | 386 MB/s | +27%
i7-1165g7 win10 | `enwik8` | 270 MB/s | 280 MB/s | 350 MB/s | +27%
i7-1165g7 win10 | `silesia.tar` | 450 MB/s | 440 MB/s | 580 MB/s | +28%
i7-9700K Ubuntu20 | `enwik8` | 600 MB/s | 604 MB/s | 829 MB/s | +38%
i7-9700K Ubuntu20 | `silesia.tar` | 683 MB/s | 678 MB/s | 991 MB/s | +45%
Galaxy S22 | `enwik8` | 360 MB/s | 420 MB/s | 515 MB/s | +70%
Galaxy S22 | `silesia.tar` | 310 MB/s | 320 MB/s | 580 MB/s | +85%
MBP M1 | `enwik8` | 428 MB/s | 734 MB/s | 815 MB/s | +90%
MBP M1 | `silesia.tar` | 465 MB/s | 875 MB/s | 1001 MB/s | +115%
### Support of externally-defined sequence producers
`libzstd` can now support external sequence producers via a new advanced registration function `ZSTD_registerSequenceProducer()` (#3333).
This API allows users to provide their own custom sequence producer which libzstd invokes to process each block. The produced list of sequences (literals and matches) is then post-processed by libzstd to produce valid compressed blocks.
This block-level offload API is a more granular complement of the existing frame-level offload API `compressSequences()` (introduced in `v1.5.1`). It offers an easier migration story for applications already integrated with `libzstd`: the user application continues to invoke the same compression functions `ZSTD_compress2()` or `ZSTD_compressStream2()` as usual, and transparently benefits from the specific properties of the external sequence producer. For example, the sequence producer could be tuned to take advantage of known characteristics of the input, to offer better speed / ratio.
One scenario that becomes possible is to combine this capability with hardware-accelerated matchfinders, such as the Intel® QuickAssist accelerator (Intel® QAT) provided in server CPUs such as the 4th Gen Intel® Xeon® Scalable processors (previously codenamed Sapphire Rapids). More details to be provided in future communications.
## Change Log
perf: +20% faster huffman decompression for targets that can't compile x64 assembly (#3449, @terrelln)
perf: up to +10% faster streaming compression at levels 1-2 (#3114, @embg)
perf: +4-13% for levels 5-12 by optimizing function generation (#3295, @terrelln)
pref: +3-11% compression speed for `arm` target (#3199, #3164, #3145, #3141, #3138, @JunHe77 and #3139, #3160, @danlark1)
perf: +5-30% faster dictionary compression at levels 1-4 (#3086, #3114, #3152, @embg)
perf: +10-20% cold dict compression speed by prefetching CDict tables (#3177, @embg)
perf: +1% faster compression by removing a branch in ZSTD_fast_noDict (#3129, @felixhandte)
perf: Small compression ratio improvements in high compression mode (#2983, #3391, @Cyan4973 and #3285, #3302, @daniellerozenblit)
perf: small speed improvement by better detecting `STATIC_BMI2` for `clang` (#3080, @TocarIP)
perf: Improved streaming performance when `ZSTD_c_stableInBuffer` is set (#2974, @Cyan4973)
cli: Asynchronous I/O for improved cli speed (#2975, #2985, #3021, #3022, @yoniko)
cli: Change `zstdless` behavior to align with `zless` (#2909, @binhdvo)
cli: Keep original file if `-c` or `--stdout` is given (#3052, @dirkmueller)
cli: Keep original files when result is concatenated into a single output with `-o` (#3450, @Cyan4973)
cli: Preserve Permissions and Ownership of regular files (#3432, @felixhandte)
cli: Print zlib/lz4/lzma library versions with `-vv` (#3030, @terrelln)
cli: Print checksum value for single frame files with `-lv` (#3332, @Cyan4973)
cli: Print `dictID` when present with `-lv` (#3184, @htnhan)
cli: when `stderr` is *not* the console, disable status updates, but preserve final summary (#3458, @Cyan4973)
cli: support `--best` and `--no-name` in `gzip` compatibility mode (#3059, @dirkmueller)
cli: support for `posix` high resolution timer `clock_gettime()`, for improved benchmark accuracy (#3423, @Cyan4973)
cli: improved help/usage (`-h`, `-H`) formatting (#3094, @dirkmueller and #3385, @jonpalmisc)
cli: Fix better handling of bogus numeric values (#3268, @ctkhanhly)
cli: Fix input consists of multiple files _and_ `stdin` (#3222, @yoniko)
cli: Fix tiny files passthrough (#3215, @cgbur)
cli: Fix for `-r` on empty directory (#3027, @brailovich)
cli: Fix empty string as argument for `--output-dir-*` (#3220, @embg)
cli: Fix decompression memory usage reported by `-vv --long` (#3042, @u1f35c, and #3232, @zengyijing)
cli: Fix infinite loop when empty input is passed to trainer (#3081, @terrelln)
cli: Fix `--adapt` doesn't work when `--no-progress` is also set (#3354, @terrelln)
api: Support for External Sequence Producer (#3333, @embg)
api: Support for in-place decompression (#3432, @terrelln)
api: New `ZSTD_CCtx_setCParams()` function, set all parameters defined in a `ZSTD_compressionParameters` structure (#3403, @Cyan4973)
api: Streaming decompression detects incorrect header ID sooner (#3175, @Cyan4973)
api: Window size resizing optimization for edge case (#3345, @daniellerozenblit)
api: More accurate error codes for busy-loop scenarios (#3413, #3455, @Cyan4973)
api: Fix limit overflow in `compressBound` and `decompressBound` (#3362, #3373, Cyan4973) reported by @nigeltao
api: Deprecate several advanced experimental functions: streaming (#3408, @embg), copy (#3196, @mileshu)
bug: Fix corruption that rarely occurs in 32-bit mode with wlog=25 (#3361, @terrelln)
bug: Fix for block-splitter (#3033, @Cyan4973)
bug: Fixes for Sequence Compression API (#3023, #3040, @Cyan4973)
bug: Fix leaking thread handles on Windows (#3147, @animalize)
bug: Fix timing issues with cmake/meson builds (#3166, #3167, #3170, @Cyan4973)
build: Allow user to select legacy level for cmake (#3050, @shadchin)
build: Enable legacy support by default in cmake (#3079, @niamster)
build: Meson build script improvements (#3039, #3120, #3122, #3327, #3357, @eli-schwartz and #3276, @neheb)
build: Add aarch64 to supported architectures for zstd_trace (#3054, @ooosssososos)
build: support AIX architecture (#3219, @qiongsiwu)
build: Fix `ZSTD_LIB_MINIFY` build macro, which now reduces static library size by half (#3366, @terrelln)
build: Fix Windows issues with Multithreading translation layer (#3364, #3380, @yoniko) and ARM64 target (#3320, @cwoffenden)
build: Fix `cmake` script (#3382, #3392, @terrelln and #3252 @Tachi107 and #3167 @Cyan4973)
doc: Updated man page, providing more details for `--train` mode (#3112, @Cyan4973)
doc: Add decompressor errata document (#3092, @terrelln)
misc: Enable Intel CET (#2992, #2994, @hjl-tools)
misc: Fix `contrib/` seekable format (#3058, @yhoogstrate and #3346, @daniellerozenblit)
misc: Improve speed of the one-file library generator (#3241, @wahern and #3005, @cwoffenden)
## PR list (generated by Github)
* x86-64: Enable Intel CET by @hjl-tools in https://github.com/facebook/zstd/pull/2992
* Add GitHub Action Checking that Zstd Runs Successfully Under CET by @felixhandte in https://github.com/facebook/zstd/pull/3015
* [opt] minor compression ratio improvement by @Cyan4973 in https://github.com/facebook/zstd/pull/2983
* Simplify HUF_decompress4X2_usingDTable_internal_bmi2_asm_loop by @WojciechMula in https://github.com/facebook/zstd/pull/3013
* Async write for decompression by @yoniko in https://github.com/facebook/zstd/pull/2975
* ZSTD CLI: Use buffered output by @yoniko in https://github.com/facebook/zstd/pull/2985
* Use faster Python script to amalgamate by @cwoffenden in https://github.com/facebook/zstd/pull/3005
* Change zstdless behavior to align with zless by @binhdvo in https://github.com/facebook/zstd/pull/2909
* AsyncIO compression part 1 - refactor of existing asyncio code by @yoniko in https://github.com/facebook/zstd/pull/3021
* Converge sumtype (offset | repcode) numeric representation towards offBase by @Cyan4973 in https://github.com/facebook/zstd/pull/2965
* fix sequence compression API in Explicit Delimiter mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3023
* Lazy parameters adaptation (part 1 - ZSTD_c_stableInBuffer) by @Cyan4973 in https://github.com/facebook/zstd/pull/2974
* Print zlib/lz4/lzma library versions in verbose version output by @terrelln in https://github.com/facebook/zstd/pull/3030
* fix for -r on empty directory by @brailovich in https://github.com/facebook/zstd/pull/3027
* Add new CLI testing platform by @terrelln in https://github.com/facebook/zstd/pull/3020
* AsyncIO compression part 2 - added async read and asyncio to compression code by @yoniko in https://github.com/facebook/zstd/pull/3022
* Macos playtest envvars fix by @yoniko in https://github.com/facebook/zstd/pull/3035
* Fix required decompression memory usage reported by -vv + --long by @u1f35c in https://github.com/facebook/zstd/pull/3042
* Select legacy level for cmake by @shadchin in https://github.com/facebook/zstd/pull/3050
* [trace] Add aarch64 to supported architectures for zstd_trace by @ooosssososos in https://github.com/facebook/zstd/pull/3054
* New features for largeNbDicts benchmark by @embg in https://github.com/facebook/zstd/pull/3063
* Use helper function for bit manipulations. by @TocarIP in https://github.com/facebook/zstd/pull/3075
* [programs] Fix infinite loop when empty input is passed to trainer by @terrelln in https://github.com/facebook/zstd/pull/3081
* Enable STATIC_BMI2 for gcc/clang by @TocarIP in https://github.com/facebook/zstd/pull/3080
* build:cmake: enable ZSTD legacy support by default by @niamster in https://github.com/facebook/zstd/pull/3079
* Implement more gzip compatibility (#3037) by @dirkmueller in https://github.com/facebook/zstd/pull/3059
* [doc] Add decompressor errata document by @terrelln in https://github.com/facebook/zstd/pull/3092
* Handle newer less versions in zstdless testing by @dirkmueller in https://github.com/facebook/zstd/pull/3093
* [contrib][linux] Fix a warning in zstd_reset_cstream() by @cyberknight777 in https://github.com/facebook/zstd/pull/3088
* Software pipeline for ZSTD_compressBlock_fast_dictMatchState (+5-6% compression speed) by @embg in https://github.com/facebook/zstd/pull/3086
* Keep original file if -c or --stdout is given by @dirkmueller in https://github.com/facebook/zstd/pull/3052
* Split help in long and short version, cleanup formatting by @dirkmueller in https://github.com/facebook/zstd/pull/3094
* updated man page, providing more details for --train mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3112
* Meson fixups for Windows by @eli-schwartz in https://github.com/facebook/zstd/pull/3039
* meson: for internal linkage, link to both libzstd and a static copy of it by @eli-schwartz in https://github.com/facebook/zstd/pull/3122
* Software pipeline for ZSTD_compressBlock_fast_extDict (+4-9% compression speed) by @embg in https://github.com/facebook/zstd/pull/3114
* ZSTD_fast_noDict: Avoid Safety Check When Writing `ip1` into Table by @felixhandte in https://github.com/facebook/zstd/pull/3129
* Correct and clarify repcode offset history logic by @embg in https://github.com/facebook/zstd/pull/3127
* [lazy] Optimize ZSTD_row_getMatchMask for levels 8-10 for ARM by @danlark1 in https://github.com/facebook/zstd/pull/3139
* fix leaking thread handles on Windows by @animalize in https://github.com/facebook/zstd/pull/3147
* Remove expensive assert in --rsyncable hot loop by @terrelln in https://github.com/facebook/zstd/pull/3154
* Bugfix for huge dictionaries by @embg in https://github.com/facebook/zstd/pull/3157
* common: apply two stage copy to aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3145
* dec: adjust seqSymbol load on aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3141
* Fix big endian ARM NEON path by @danlark1 in https://github.com/facebook/zstd/pull/3160
* [contrib] largeNbDicts bugfix + improvements by @embg in https://github.com/facebook/zstd/pull/3161
* display a warning message when using C90 clock_t by @Cyan4973 in https://github.com/facebook/zstd/pull/3166
* remove explicit standard setting from cmake script by @Cyan4973 in https://github.com/facebook/zstd/pull/3167
* removed gnu99 statement from meson recipe by @Cyan4973 in https://github.com/facebook/zstd/pull/3170
* "Short cache" optimization for level 1-4 DMS (+5-30% compression speed) by @embg in https://github.com/facebook/zstd/pull/3152
* Streaming decompression can detect incorrect header ID sooner by @Cyan4973 in https://github.com/facebook/zstd/pull/3175
* Add prefetchCDictTables CCtxParam (+10-20% cold dict compression speed) by @embg in https://github.com/facebook/zstd/pull/3177
* Fix ZSTD_BUILD_TESTS=ON with MSVC by @nocnokneo in https://github.com/facebook/zstd/pull/3180
* zstd -lv <file> to show dictID by @htnhan in https://github.com/facebook/zstd/pull/3184
* Intial commit to address 3090. Added support to decompress empty block. by @udayanbapat in https://github.com/facebook/zstd/pull/3118
* [largeNbDicts] Second try at fixing decompression segfault to always create compressInstructions by @zhuhan0 in https://github.com/facebook/zstd/pull/3209
* Clarify benchmark chunking docstring by @embg in https://github.com/facebook/zstd/pull/3197
* decomp: add prefetch for matched seq on aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3164
* lib: add hint to generate more pipeline friendly code by @JunHe77 in https://github.com/facebook/zstd/pull/3138
* [AIX] Fix Compiler Flags and Bugs on AIX to Pass All Tests by @qiongsiwu in https://github.com/facebook/zstd/pull/3219
* zlibWrapper: Update for zlib 1.2.12 by @orbea in https://github.com/facebook/zstd/pull/3217
* Fix small file passthrough by @cgbur in https://github.com/facebook/zstd/pull/3215
* Add warning when multi-thread decompression is requested by @tomcwang in https://github.com/facebook/zstd/pull/3208
* stdin + multiple file fixes by @yoniko in https://github.com/facebook/zstd/pull/3222
* [AIX] Fixing hash4Ptr for Big Endian Systems by @qiongsiwu in https://github.com/facebook/zstd/pull/3227
* Disallow empty string as argument for --output-dir-flat and --output-dir-mirror by @embg in https://github.com/facebook/zstd/pull/3220
* Deprecate ZSTD_getDecompressedSize() by @terrelln in https://github.com/facebook/zstd/pull/3225
* [T124890272] Mark 2 Obsolete Functions(ZSTD_copy*Ctx) Deprecated in Zstd by @mileshu in https://github.com/facebook/zstd/pull/3196
* fileio_types.h : avoid dependency on mem.h by @Cyan4973 in https://github.com/facebook/zstd/pull/3232
* fixed: verbose output prints wrong value for `wlog` when doing `--long` by @zengyijing in https://github.com/facebook/zstd/pull/3226
* Add explicit --pass-through flag and default to enabled for *cat by @terrelln in https://github.com/facebook/zstd/pull/3223
* Document pass-through behavior by @cgbur in https://github.com/facebook/zstd/pull/3242
* restore combine.sh bash performance while still sticking to POSIX by @wahern in https://github.com/facebook/zstd/pull/3241
* Benchmark program for sequence compression API by @embg in https://github.com/facebook/zstd/pull/3257
* streamline `make clean` list maintenance by adding a `CLEAN` variable by @Cyan4973 in https://github.com/facebook/zstd/pull/3256
* drop `-E` flag in `sed` by @haampie in https://github.com/facebook/zstd/pull/3245
* compress:check more bytes to reduce `ZSTD_count` call by @JunHe77 in https://github.com/facebook/zstd/pull/3199
* build(cmake): improve pkg-config generation by @Tachi107 in https://github.com/facebook/zstd/pull/3252
* Fix for `zstd` CLI accepts bogus values for numeric parameters by @ctkhanhly in https://github.com/facebook/zstd/pull/3268
* ci: test pkg-config file by @Tachi107 in https://github.com/facebook/zstd/pull/3267
* Move ZSTD_DEPRECATED before ZSTDLIB_API/ZSTDLIB_STATIC_API for `clang` by @MaskRay in https://github.com/facebook/zstd/pull/3273
* Enable OpenSSF Scorecard Action by @felixhandte in https://github.com/facebook/zstd/pull/3277
* fixed zstd-pgo target for GCC by @ilyakurdyukov in https://github.com/facebook/zstd/pull/3281
* Cleaner threadPool initialization by @Cyan4973 in https://github.com/facebook/zstd/pull/3288
* Make fuzzing work without ZSTD_MULTITHREAD by @danlark1 in https://github.com/facebook/zstd/pull/3291
* Optimal huf depth by @daniellerozenblit in https://github.com/facebook/zstd/pull/3285
* Make ZSTD_getDictID_fromDDict() Read DictID from DDict by @felixhandte in https://github.com/facebook/zstd/pull/3290
* [contrib][linux-kernel] Generate SPDX license identifiers by @ojeda in https://github.com/facebook/zstd/pull/3294
* [lazy] Use switch instead of indirect function calls, improving compression speed by @terrelln in https://github.com/facebook/zstd/pull/3295
* [linux] Add zstd_common module by @terrelln in https://github.com/facebook/zstd/pull/3292
* Complete migration of ZSTD_c_enableLongDistanceMatching to ZSTD_paramSwitch_e framework by @embg in https://github.com/facebook/zstd/pull/3321
* meson: get version up front by @eli-schwartz in https://github.com/facebook/zstd/pull/3327
* Fix for MSVC C4267 warning on ARM64 (which becomes error C2220 with /WX) by @cwoffenden in https://github.com/facebook/zstd/pull/3320
* Enable dependabot for automatic GitHub Actions updates by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3284
* Print checksum value for single frame files in cli with -v -l options by @Cyan4973 in https://github.com/facebook/zstd/pull/3332
* Fix window size resizing optimization for edge case by @daniellerozenblit in https://github.com/facebook/zstd/pull/3345
* [linux-kernel] Fix stack detection for newer gcc by @terrelln in https://github.com/facebook/zstd/pull/3348
* Reserve two fields in ZSTD_frameHeader by @embg in https://github.com/facebook/zstd/pull/3349
* Fix seekable format for empty string by @daniellerozenblit in https://github.com/facebook/zstd/pull/3346
* meson: make backtrace dependency on execinfo for musl libc compatibility by @neheb in https://github.com/facebook/zstd/pull/3276
* Refactor progress bar & summary line logic by @terrelln in https://github.com/facebook/zstd/pull/2984
* Use `__attribute__((aligned(1)))` for unaligned access by @Hello71 in https://github.com/facebook/zstd/pull/2881
* Separate parameter adaption from display update rate by @terrelln in https://github.com/facebook/zstd/pull/3354
* [decompress] Fix UB nullptr addition & improve fuzzer by @terrelln in https://github.com/facebook/zstd/pull/3356
* [legacy] Simplify legacy codebase by removing esoteric memory accesses and only use memcpy by @terrelln in https://github.com/facebook/zstd/pull/3355
* Fix corruption that rarely occurs in 32-bit mode with wlog=25 by @terrelln in https://github.com/facebook/zstd/pull/3361
* meson: partial fix for building pzstd on MSVC by @eli-schwartz in https://github.com/facebook/zstd/pull/3357
* [CI] Re-enable versions-test by @terrelln in https://github.com/facebook/zstd/pull/3371
* [api][visibility] Make the visibility macros more consistent by @terrelln in https://github.com/facebook/zstd/pull/3363
* [build] Fix ZSTD_LIB_MINIFY build option by @terrelln in https://github.com/facebook/zstd/pull/3366
* [zdict] Fix static linking only include guards by @terrelln in https://github.com/facebook/zstd/pull/3372
* check potential overflow of compressBound() by @Cyan4973 in https://github.com/facebook/zstd/pull/3362
* decompressBound tests and fix by @Cyan4973 in https://github.com/facebook/zstd/pull/3373
* Meson test fixups by @eli-schwartz in https://github.com/facebook/zstd/pull/3120
* [pzstd] Fixes for Windows build by @terrelln in https://github.com/facebook/zstd/pull/3380
* Windows MT layer bug fixes by @yoniko in https://github.com/facebook/zstd/pull/3364
* Update Copyright Comments by @felixhandte in https://github.com/facebook/zstd/pull/3173
* [docs] Clarify dictionary loading documentation by @terrelln in https://github.com/facebook/zstd/pull/3381
* [build][cmake] Fix cmake with custom assembler by @terrelln in https://github.com/facebook/zstd/pull/3382
* Pin actions/checkout Dependency to Specific Commit Hash by @felixhandte in https://github.com/facebook/zstd/pull/3384
* Improve help/usage (`-h`, `-H`) formatting by @jonpalmisc in https://github.com/facebook/zstd/pull/3385
* [cmake] Add noexecstack to compiler/linker flags by @terrelln in https://github.com/facebook/zstd/pull/3392
* Fix `-Wdocumentation` by @terrelln in https://github.com/facebook/zstd/pull/3393
* Support decompression of compressed blocks of size ZSTD_BLOCKSIZE_MAX by @Cyan4973 in https://github.com/facebook/zstd/pull/3399
* spec update : require minimum nb of literals for 4-streams mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3398
* External matchfinder API by @embg in https://github.com/facebook/zstd/pull/3333
* New `ZSTD_CCtx_setCParams()` entry point, to set all parameters defined in a `ZSTD_compressionParameters` structure by @Cyan4973 in https://github.com/facebook/zstd/pull/3403
* Move deprecated annotation before static to allow C++ compilation for clang by @danlark1 in https://github.com/facebook/zstd/pull/3400
* Optimal huff depth speed improvements by @daniellerozenblit in https://github.com/facebook/zstd/pull/3302
* improve compression ratio of small alphabets by @Cyan4973 in https://github.com/facebook/zstd/pull/3391
* Fix fuzzing with ZSTD_MULTITHREAD by @danlark1 in https://github.com/facebook/zstd/pull/3417
* minor refactoring for timefn by @Cyan4973 in https://github.com/facebook/zstd/pull/3413
* Add support for in-place decompression by @terrelln in https://github.com/facebook/zstd/pull/3421
* fix when nb of literals is very small by @Cyan4973 in https://github.com/facebook/zstd/pull/3419
* Deprecate advanced streaming functions by @embg in https://github.com/facebook/zstd/pull/3408
* Disable Custom ASAN/MSAN Poisoning on MinGW Builds by @felixhandte in https://github.com/facebook/zstd/pull/3424
* [tests] Fix version test determinism by @terrelln in https://github.com/facebook/zstd/pull/3422
* Refactor `timefn` unit, restore support for `clock_gettime()` by @Cyan4973 in https://github.com/facebook/zstd/pull/3423
* Fuzz on maxBlockSize by @daniellerozenblit in https://github.com/facebook/zstd/pull/3418
* Fuzz the External Matchfinder API by @embg in https://github.com/facebook/zstd/pull/3437
* Cap hashLog & chainLog to ensure that we only use 32 bits of hash by @terrelln in https://github.com/facebook/zstd/pull/3438
* [versions-test] Work around bug in dictionary builder for older versions by @terrelln in https://github.com/facebook/zstd/pull/3436
* added c89 build test to CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3435
* added cygwin tests to Github Actions by @Cyan4973 in https://github.com/facebook/zstd/pull/3431
* Huffman refactor by @terrelln in https://github.com/facebook/zstd/pull/3434
* Fix bufferless API with attached dictionary by @terrelln in https://github.com/facebook/zstd/pull/3441
* Test PGO Builds by @felixhandte in https://github.com/facebook/zstd/pull/3442
* Fix CLI Handling of Permissions and Ownership by @felixhandte in https://github.com/facebook/zstd/pull/3432
* Fix -Wstringop-overflow warning by @terrelln in https://github.com/facebook/zstd/pull/3440
* refactor : --rm ignored with stdout by @Cyan4973 in https://github.com/facebook/zstd/pull/3443
* Fix sequence validation and seqStore bounds check by @daniellerozenblit in https://github.com/facebook/zstd/pull/3439
* Fix ZSTD_estimate* and ZSTD_initCStream() docs by @embg in https://github.com/facebook/zstd/pull/3448
* Fix 32-bit build errors in zstd seekable format by @daniellerozenblit in https://github.com/facebook/zstd/pull/3452
* Fuzz large offsets through sequence compression api by @daniellerozenblit in https://github.com/facebook/zstd/pull/3447
* [huf] Add generic C versions of the fast decoding loops by @terrelln in https://github.com/facebook/zstd/pull/3449
* Provide more accurate error codes for busy-loop scenarios by @Cyan4973 in https://github.com/facebook/zstd/pull/3455
* disable --rm on -o command by @Cyan4973 in https://github.com/facebook/zstd/pull/3450
* [Bugfix] CLI row hash flags set the wrong values by @yoniko in https://github.com/facebook/zstd/pull/3457
* [huf] Fix bug in fast C decoders by @terrelln in https://github.com/facebook/zstd/pull/3459
* Disable status updates when `stderr` is not the console by @Cyan4973 in https://github.com/facebook/zstd/pull/3458
* fix long offset resolution by @daniellerozenblit in https://github.com/facebook/zstd/pull/3460
* Simplify 32-bit long offsets decoding logic by @terrelln in https://github.com/facebook/zstd/pull/3467
## New Contributors
* @WojciechMula made their first contribution in https://github.com/facebook/zstd/pull/3013
* @trixirt made their first contribution in https://github.com/facebook/zstd/pull/3026
* @brailovich made their first contribution in https://github.com/facebook/zstd/pull/3027
* @u1f35c made their first contribution in https://github.com/facebook/zstd/pull/3042
* @shadchin made their first contribution in https://github.com/facebook/zstd/pull/3050
* @ooosssososos made their first contribution in https://github.com/facebook/zstd/pull/3054
* @TocarIP made their first contribution in https://github.com/facebook/zstd/pull/3075
* @xry111 made their first contribution in https://github.com/facebook/zstd/pull/3084
* @niamster made their first contribution in https://github.com/facebook/zstd/pull/3079
* @dirkmueller made their first contribution in https://github.com/facebook/zstd/pull/3059
* @cyberknight777 made their first contribution in https://github.com/facebook/zstd/pull/3088
* @dpelle made their first contribution in https://github.com/facebook/zstd/pull/3095
* @paulmenzel made their first contribution in https://github.com/facebook/zstd/pull/3108
* @cuishuang made their first contribution in https://github.com/facebook/zstd/pull/3117
* @averred made their first contribution in https://github.com/facebook/zstd/pull/3135
* @JunHe77 made their first contribution in https://github.com/facebook/zstd/pull/3145
* @htnhan made their first contribution in https://github.com/facebook/zstd/pull/3184
* @udayanbapat made their first contribution in https://github.com/facebook/zstd/pull/3118
* @zhuhan0 made their first contribution in https://github.com/facebook/zstd/pull/3205
* @mgord9518 made their first contribution in https://github.com/facebook/zstd/pull/3218
* @qiongsiwu made their first contribution in https://github.com/facebook/zstd/pull/3219
* @orbea made their first contribution in https://github.com/facebook/zstd/pull/3217
* @cgbur made their first contribution in https://github.com/facebook/zstd/pull/3215
* @tomcwang made their first contribution in https://github.com/facebook/zstd/pull/3208
* @mileshu made their first contribution in https://github.com/facebook/zstd/pull/3196
* @zengyijing made their first contribution in https://github.com/facebook/zstd/pull/3226
* @grossws made their first contribution in https://github.com/facebook/zstd/pull/3230
* @wahern made their first contribution in https://github.com/facebook/zstd/pull/3241
* @daniellerozenblit made their first contribution in https://github.com/facebook/zstd/pull/3258
* @DimitriPapadopoulos made their first contribution in https://github.com/facebook/zstd/pull/3259
* @sashashura made their first contribution in https://github.com/facebook/zstd/pull/3264
* @haampie made their first contribution in https://github.com/facebook/zstd/pull/3247
* @Tachi107 made their first contribution in https://github.com/facebook/zstd/pull/3252
* @ctkhanhly made their first contribution in https://github.com/facebook/zstd/pull/3268
* @MaskRay made their first contribution in https://github.com/facebook/zstd/pull/3273
* @ilyakurdyukov made their first contribution in https://github.com/facebook/zstd/pull/3281
* @ojeda made their first contribution in https://github.com/facebook/zstd/pull/3294
* @GermanAizek made their first contribution in https://github.com/facebook/zstd/pull/3304
* @joycebrum made their first contribution in https://github.com/facebook/zstd/pull/3309
* @yiyuaner made their first contribution in https://github.com/facebook/zstd/pull/3300
* @nmoinvaz made their first contribution in https://github.com/facebook/zstd/pull/3289
* @jonpalmisc made their first contribution in https://github.com/facebook/zstd/pull/3385
**Full Automated Changelog**: https://github.com/facebook/zstd/compare/v1.5.2...v1.5.42023-02-10T00:55:48+00:00zstd v1.5.5zstd v1.5.52023-04-04T22:20:32+00:00# Zstandard v1.5.5 Release Note
This is a quick fix release. The primary focus is to correct a rare corruption bug in high compression mode, detected by @danlark1 . The probability to generate such a scenario by random chance is extremely low. It evaded months of continuous fuzzer tests, due to the number and complexity of simultaneous conditions required to trigger it. Nevertheless, @danlark1 from Google shepherds such a humongous amount of data that he managed to detect a reproduction case (corruptions are detected thanks to the checksum), making it possible for @terrelln to investigate and fix the bug. Thanks !
While the probability might be very small, corruption issues are nonetheless very serious, so an update to this version is highly recommended, especially if you employ high compression modes (levels 16+).
When the issue was detected, there were a number of other improvements and minor fixes already in the making, hence they are also present in this release. Let’s detail the main ones.
### Improved memory usage and speed for the `--patch-from` mode
`V1.5.5` introduces memory-mapped dictionaries, by @daniellerozenblit, for both posix [#3486](https://github.com/facebook/zstd/pull/3486) and windows [#3557](https://github.com/facebook/zstd/pull/3557).
This feature allows `zstd` to memory-map large dictionaries, rather than requiring to load them into memory. This can make a pretty big difference for memory-constrained environments operating patches for large data sets.
It's mostly visible under memory pressure, since `mmap` will be able to release less-used memory and continue working.
But even when memory is plentiful, there are still measurable memory benefits, as shown in the graph below, especially when the reference turns out to be not completely relevant for the patch.

This feature is automatically enabled for `--patch-from` compression/decompression when the dictionary is larger than the user-set memory limit. It can also be manually enabled/disabled using `--mmap-dict` or `--no-mmap-dict` respectively.
Additionally, @daniellerozenblit introduces significant speed improvements for `--patch-from`.
An `I/O` optimization in [#3486](https://github.com/facebook/zstd/pull/3486) greatly improves `--patch-from` decompression speed on Linux, typically by `+50%` on large files (~1GB).

Compression speed is also taken care of, with a dictionary-indexing speed optimization introduced in [#3545](https://github.com/facebook/zstd/pull/3545). It wildly accelerates `--patch-from` compression, typically doubling speed on large files (~1GB), sometimes even more depending on exact scenario.

This speed improvement comes at a slight regression in compression ratio, and is therefore enabled only on non-ultra compression strategies.
### Speed improvements of middle-level compression for specific scenarios
The row-hash match finder introduced in version 1.5.0 for levels 5-12 has been improved in version 1.5.5, enhancing its speed in specific corner-case scenarios.
The first optimization ([#3426](https://github.com/facebook/zstd/pull/3426)) accelerates streaming compression using `ZSTD_compressStream` on small inputs by removing an expensive table initialization step. This results in remarkable speed increases for very small inputs.
The following scenario measures compression speed of `ZSTD_compressStream` at level 9 for different sample sizes on a linux platform running an i7-9700k cpu.
| sample size | `v1.5.4` (MB/s) | `v1.5.5` (MB/s) | improvement |
| --- | ----:| ---:| --- |
| 100 | 1.4 | 44.8 | x32
| 200 | 2.8 | 44.9 | x16
| 500 | 6.5 | 60.0 | x9.2
| 1K | 12.4 | 70.0 | x5.6
| 2K | 25.0 | 111.3 | x4.4
| 4K | 44.4 | 139.4 | x3.2
| ... | ... | ... |
| 1M | 97.5 | 99.4 | +2%
The second optimization ([#3552](https://github.com/facebook/zstd/issues/3552)) speeds up compression of incompressible data by a large multiplier. This is achieved by increasing the step size and reducing the frequency of matching when no matches are found, with negligible impact on the compression ratio. It makes mid-level compression essentially inexpensive when processing incompressible data, typically, already compressed data (note: this was already the case for fast compression levels).
The following scenario measures compression speed of `ZSTD_compress` compiled with `gcc-9` for a ~10MB incompressible sample on a linux platform running an i7-9700k cpu.
| level | `v1.5.4` (MB/s) | `v1.5.5` (MB/s) | improvement |
| --- | ----:| ---:| --- |
| 3 | 3500 | 3500 | not a row-hash level (control)
| 5 | 400 | 2500 | x6.2
| 7 | 380 | 2200 | x5.8
| 9 | 176 | 1880 | x10
| 11 | 67 | 1130 | x16
| 13 | 89 | 89 | not a row-hash level (control)
### Miscellaneous
There are other welcome speed improvements in this package.
For example, @felixhandte managed to increase processing speed of small files by carefully reducing the nb of system calls (#3479). This can easily translate into +10% speed when processing a lot of small files in batch.
The Seekable format received a bit of care. It's now much faster when splitting data into very small blocks (#3544). In an extreme scenario reported by @P-E-Meunier, it improves processing speed by x90. Even for more "common" settings, such as using 4KB blocks on some "normally" compressible data like `enwik`, it still provides a healthy x2 processing speed benefit. Moreover, @dloidolt merged an optimization that reduces the nb of `I/O` `seek()` events during reads (decompression), which is also beneficial for speed.
The release is not limited to speed improvements, several loose ends and corner cases were also fixed in this release. For a more detailed list of changes, please take a look at the changelog.
## Change Log
- fix: fix rare corruption bug affecting the high compression mode, reported by @danlark1 (#3517, @terrelln)
- perf: improve mid-level compression speed (#3529, #3533, #3543, @yoniko and #3552, @terrelln)
- lib: deprecated bufferless block-level API (#3534) by @terrelln
- cli: `mmap` large dictionaries to save memory, by @daniellerozenblit
- cli: improve speed of `--patch-from` mode (~+50%) (#3545) by @daniellerozenblit
- cli: improve i/o speed (~+10%) when processing lots of small files (#3479) by @felixhandte
- cli: `zstd` no longer crashes when requested to write into write-protected directory (#3541) by @felixhandte
- cli: fix decompression into block device using `-o` (#3584, @Cyan4973) reported by @georgmu
- build: fix zstd CLI compiled with lzma support but not zlib support (#3494) by @Hello71
- build: fix `cmake` does no longer require 3.18 as minimum version (#3510) by @kou
- build: fix MSVC+ClangCL linking issue (#3569) by @tru
- build: fix zstd-dll, version of zstd CLI that links to the dynamic library (#3496) by @yoniko
- build: fix MSVC warnings (#3495) by @embg
- doc: updated zstd specification to clarify corner cases, by @Cyan4973
- doc: document how to create fat binaries for macos (#3568) by @rickmark
- misc: improve seekable format ingestion speed (~+100%) for very small chunk sizes (#3544) by @Cyan4973
- misc: `tests/fullbench` can benchmark multiple files (#3516) by @dloidolt
## Full change list (auto-generated)
* Fix all MSVC warnings by @embg in https://github.com/facebook/zstd/pull/3495
* Fix zstd-dll build missing dependencies by @yoniko in https://github.com/facebook/zstd/pull/3496
* Bump github/codeql-action from 2.2.1 to 2.2.4 by @dependabot in https://github.com/facebook/zstd/pull/3503
* Github Action to generate Win64 artifacts by @Cyan4973 in https://github.com/facebook/zstd/pull/3491
* Use correct types in LZMA comp/decomp by @Hello71 in https://github.com/facebook/zstd/pull/3497
* Make Github workflows permissions read-only by default by @yoniko in https://github.com/facebook/zstd/pull/3488
* CI Workflow for external compressors dependencies by @yoniko in https://github.com/facebook/zstd/pull/3505
* Fix cli-tests issues by @daniellerozenblit in https://github.com/facebook/zstd/pull/3509
* Fix Permissions on Publish Release Artifacts Job by @felixhandte in https://github.com/facebook/zstd/pull/3511
* Use `f`-variants of `chmod()` and `chown()` by @felixhandte in https://github.com/facebook/zstd/pull/3479
* Don't require CMake 3.18 or later by @kou in https://github.com/facebook/zstd/pull/3510
* meson: always build the zstd binary when tests are enabled by @eli-schwartz in https://github.com/facebook/zstd/pull/3490
* [bug-fix] Fix rare corruption bug affecting the block splitter by @terrelln in https://github.com/facebook/zstd/pull/3517
* Clarify zstd specification for Huffman blocks by @Cyan4973 in https://github.com/facebook/zstd/pull/3514
* Fix typos found by codespell by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3513
* Bump github/codeql-action from 2.2.4 to 2.2.5 by @dependabot in https://github.com/facebook/zstd/pull/3518
* fullbench with two files by @dloidolt in https://github.com/facebook/zstd/pull/3516
* Add initialization of clevel to static cdict (#3525) by @yoniko in https://github.com/facebook/zstd/pull/3527
* [linux-kernel] Fix assert definition by @terrelln in https://github.com/facebook/zstd/pull/3532
* Add ZSTD_set{C,F,}Params() helper functions by @terrelln in https://github.com/facebook/zstd/pull/3530
* Clarify dstCapacity requirements by @terrelln in https://github.com/facebook/zstd/pull/3531
* Mmap large dictionaries in patch-from mode by @daniellerozenblit in https://github.com/facebook/zstd/pull/3486
* added clarifications for sizes of compressed huffman blocks and streams. by @Cyan4973 in https://github.com/facebook/zstd/pull/3538
* Simplify benchmark unit invocation API from CLI by @Cyan4973 in https://github.com/facebook/zstd/pull/3526
* Avoid Segfault Caused by Calling `setvbuf()` on Null File Pointer by @felixhandte in https://github.com/facebook/zstd/pull/3541
* Pin Moar Action Dependencies by @felixhandte in https://github.com/facebook/zstd/pull/3542
* Improved seekable format ingestion speed for small frame size by @Cyan4973 in https://github.com/facebook/zstd/pull/3544
* Reduce RowHash's tag space size by x2 by @yoniko in https://github.com/facebook/zstd/pull/3543
* [Bugfix] row hash tries to match position 0 by @yoniko in https://github.com/facebook/zstd/pull/3548
* Bump github/codeql-action from 2.2.5 to 2.2.6 by @dependabot in https://github.com/facebook/zstd/pull/3549
* Add init once memory (#3528) by @yoniko in https://github.com/facebook/zstd/pull/3529
* Introduce salt into row hash (#3528 part 2) by @yoniko in https://github.com/facebook/zstd/pull/3533
* added documentation for the seekable format by @Cyan4973 in https://github.com/facebook/zstd/pull/3547
* patch-from speed optimization by @daniellerozenblit in https://github.com/facebook/zstd/pull/3545
* Deprecated bufferless and block level APIs by @terrelln in https://github.com/facebook/zstd/pull/3534
* added documentation for LDM + dictionary compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/3553
* Fix a bug in the CLI tests newline processing, then simplify it further by @ppentchev in https://github.com/facebook/zstd/pull/3559
* [lazy] Skip over incompressible data by @terrelln in https://github.com/facebook/zstd/pull/3552
* Fix patch-from speed optimization by @daniellerozenblit in https://github.com/facebook/zstd/pull/3556
* Bump actions/checkout from 3.3.0 to 3.5.0 by @dependabot in https://github.com/facebook/zstd/pull/3572
* [easy] minor doc update for --rsyncable by @Cyan4973 in https://github.com/facebook/zstd/pull/3570
* [contrib/pzstd] Select `-std=c++11` When Default is Older by @felixhandte in https://github.com/facebook/zstd/pull/3574
* Add instructions for building Universal2 on macOS via CMake by @rickmark in https://github.com/facebook/zstd/pull/3568
* Provide an interface for fuzzing sequence producer plugins by @embg in https://github.com/facebook/zstd/pull/3551
* mmap for windows by @daniellerozenblit in https://github.com/facebook/zstd/pull/3557
* Bump github/codeql-action from 2.2.6 to 2.2.8 by @dependabot in https://github.com/facebook/zstd/pull/3573
* Disable linker flag detection on MSVC/ClangCL. by @tru in https://github.com/facebook/zstd/pull/3569
* Couple tweaks to improve decompression speed with clang PGO compilation by @zhuhan0 in https://github.com/facebook/zstd/pull/3576
* Increase tests timeout by @dvoropaev in https://github.com/facebook/zstd/pull/3540
* added a Clang-CL Windows test to CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3579
* Seekable format read optimization by @Cyan4973 in https://github.com/facebook/zstd/pull/3581
* Check that `dest` is valid for decompression by @daniellerozenblit in https://github.com/facebook/zstd/pull/3555
* fix decompression with -o writing into a block device by @Cyan4973 in https://github.com/facebook/zstd/pull/3584
* updated version number to v1.5.5 by @Cyan4973 in https://github.com/facebook/zstd/pull/3577
## New Contributors
* @kou made their first contribution in https://github.com/facebook/zstd/pull/3510
* @dloidolt made their first contribution in https://github.com/facebook/zstd/pull/3516
* @ppentchev made their first contribution in https://github.com/facebook/zstd/pull/3559
* @rickmark made their first contribution in https://github.com/facebook/zstd/pull/3568
* @dvoropaev made their first contribution in https://github.com/facebook/zstd/pull/3540
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.4...v1.5.52023-04-04T22:20:32+00:00rocksdb rocksdb-5.5.3rocksdb rocksdb-5.5.32017-07-17T21:32:38+00:00### Bug Fixes
* Fix LITE build error.2017-07-17T21:32:38+00:00rocksdb v5.5.3rocksdb v5.5.32017-07-17T21:33:08+00:005.5.3 release.2017-07-17T21:33:08+00:00rocksdb v5.5.4rocksdb v5.5.42017-07-18T18:49:59+00:00## 5.5.4 (07/18/2017)
* Change License to Apache + GPLv2
2017-07-18T18:49:59+00:00rocksdb v5.5.5rocksdb v5.5.52017-07-18T20:53:01+00:00* Change license section of java/rocksjni.pom
* Clear up some files still mentioning PATENTS file
2017-07-18T20:53:01+00:00rocksdb v5.6.1rocksdb v5.6.12017-07-25T17:14:22+00:005.6.1 release.2017-07-25T17:14:22+00:00rocksdb rocksdb-5.6.1rocksdb rocksdb-5.6.12017-07-25T17:15:35+00:00## 5.6.1 (07/25/2017)
### Bug Fixes
* Fix lite build.
## 5.6.0 (06/06/2017)
### Public API Change
* Scheduling flushes and compactions in the same thread pool is no longer supported by setting `max_background_flushes=0`. Instead, users can achieve this by configuring their high-pri thread pool to have zero threads.
* Replace `Options::max_background_flushes`, `Options::max_background_compactions`, and `Options::base_background_compactions` all with `Options::max_background_jobs`, which automatically decides how many threads to allocate towards flush/compaction.
* options.delayed_write_rate by default take the value of options.rate_limiter rate.
* Replace global variable `IOStatsContext iostats_context` with `IOStatsContext* get_iostats_context()`; replace global variable `PerfContext perf_context` with `PerfContext* get_perf_context()`.
### New Features
* Change ticker/histogram statistics implementations to use core-local storage. This improves aggregation speed compared to our previous thread-local approach, particularly for applications with many threads.
* Users can pass a cache object to write buffer manager, so that they can cap memory usage for memtable and block cache using one single limit.
* Flush will be triggered when 7/8 of the limit introduced by write_buffer_manager or db_write_buffer_size is triggered, so that the hard threshold is hard to hit.
* Introduce WriteOptions.low_pri. If it is true, low priority writes will be throttled if the compaction is behind.
* `DB::IngestExternalFile()` now supports ingesting files into a database containing range deletions.
### Bug Fixes
* Shouldn't ignore return value of fsync() in flush.2017-07-25T17:15:35+00:00rocksdb rocksdb-5.7.1rocksdb rocksdb-5.7.12017-08-12T02:11:58+00:00## 5.7.1 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T02:11:58+00:00rocksdb v5.7.1rocksdb v5.7.12017-08-12T02:12:47+00:00## 5.7.1 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T02:12:47+00:00rocksdb rocksdb-5.6.2rocksdb rocksdb-5.6.22017-08-12T23:17:54+00:00## 5.6.2 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.
2017-08-12T23:17:54+00:00rocksdb v5.6.2rocksdb v5.6.22017-08-12T23:18:34+00:00## 5.6.2 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T23:18:34+00:00rocksdb rocksdb-5.5.6rocksdb rocksdb-5.5.62017-08-12T23:20:17+00:00## 5.5.6 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T23:20:17+00:00rocksdb v5.5.6rocksdb v5.5.62017-08-12T23:20:45+00:00## 5.5.6 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T23:20:45+00:00rocksdb rocksdb-5.4.10rocksdb rocksdb-5.4.102017-08-12T23:22:33+00:00## 5.4.10 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.
2017-08-12T23:22:33+00:00rocksdb v5.4.10rocksdb v5.4.102017-08-12T23:23:24+00:00## 5.4.10 (08/12/2017)
### Bug Fixes
* Fix incorrect dropping of deletions during intra-L0 compaction.2017-08-12T23:23:24+00:00rocksdb v5.7.2rocksdb v5.7.22017-08-15T21:22:29+00:00### Bug Fixes
* Fix incorrect dropping of deletions issue with FIFO compaction.
* Fix LITE build compiler error with missing abort().2017-08-15T21:22:29+00:00rocksdb rocksdb-5.7.2rocksdb rocksdb-5.7.22017-08-15T21:23:22+00:00### Bug Fixes
* Fix incorrect dropping of deletions issue with FIFO compaction.
* Fix LITE build compiler error with missing abort().2017-08-15T21:23:22+00:00rocksdb rocksdb-5.7.3rocksdb rocksdb-5.7.32017-08-30T06:11:30+00:00## 5.7.3 (08/29/2017)
### Bug Fixes
* Fix transient reappearance of keys covered by range deletions when memtable prefix bloom filter is enabled.
* Fix potentially wrong file smallest key when range deletions separated by snapshot are written together.
2017-08-30T06:11:30+00:00rocksdb v5.7.3rocksdb v5.7.32017-08-30T06:12:19+00:00## 5.7.3 (08/29/2017)
### Bug Fixes
* Fix transient reappearance of keys covered by range deletions when memtable prefix bloom filter is enabled.
* Fix potentially wrong file smallest key when range deletions separated by snapshot are written together.2017-08-30T06:12:19+00:00rocksdb v5.8rocksdb v5.82017-09-28T15:56:04+00:00## 5.8 (09/28/2017)
### Public API Change
* Users of Statistics::getHistogramString() will see fewer histogram buckets and different bucket endpoints.
* Slice::compare and BytewiseComparator Compare no longer accept Slices containing nullptr.
* Transaction::Get and Transaction::GetForUpdate variants with PinnableSlice added.
### New Features
* Add Iterator::Refresh(), which allows users to update the iterator state so that they can avoid some initialization costs of recreating iterators.
* Replace dynamic_cast<> (except unit test) so people can choose to build with RTTI off. With make, release mode is by default built with -fno-rtti and debug mode is built without it. Users can override it by setting USE_RTTI=0 or 1.
* Universal compactions including the bottom level can be executed in a dedicated thread pool. This alleviates head-of-line blocking in the compaction queue, which cause write stalling, particularly in multi-instance use cases. Users can enable this feature via Env::SetBackgroundThreads(N, Env::Priority::BOTTOM), where N > 0.
* Allow merge operator to be called even with a single merge operand during compactions, by appropriately overriding MergeOperator::AllowSingleOperand.
* Add DB::VerifyChecksum(), which verifies the checksums in all SST files in a running DB.
Block-based table support for disabling checksums by setting BlockBasedTableOptions::checksum = kNoChecksum.
### Bug Fixes
* Fix wrong latencies in rocksdb.db.get.micros, rocksdb.db.write.micros, and rocksdb.sst.read.micros.
* Fix incorrect dropping of deletions during intra-L0 compaction.
* Fix transient reappearance of keys covered by range deletions when memtable prefix bloom filter is enabled.
* Fix potentially wrong file smallest key when range deletions separated by snapshot are written together.2017-09-28T15:56:04+00:00rocksdb v5.8.6rocksdb v5.8.62017-11-20T21:53:39+00:00## 5.8.6 (11/20/2017)
### Bug Fixes
* Fixed aligned_alloc issues with Windows.
## 5.8.1 (10/23/2017)
### New Features
* Add a new db property "rocksdb.estimate-oldest-key-time" to return oldest data timestamp. The property is available only for FIFO compaction with compaction_options_fifo.allow_compaction = false.2017-11-20T21:53:39+00:00rocksdb rocksdb-5.8.6rocksdb rocksdb-5.8.62017-11-20T21:54:19+00:00## 5.8.6 (11/20/2017)
### Bug Fixes
* Fixed aligned_alloc issues with Windows.
## 5.8.1 (10/23/2017)
### New Features
* Add a new db property "rocksdb.estimate-oldest-key-time" to return oldest data timestamp. The property is available only for FIFO compaction with compaction_options_fifo.allow_compaction = false.2017-11-20T21:54:19+00:00rocksdb v5.7.5rocksdb v5.7.52017-11-29T05:26:23+00:00### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower2017-11-29T05:26:23+00:00rocksdb rocksdb-5.7.5rocksdb rocksdb-5.7.52017-11-29T05:27:00+00:00### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower2017-11-29T05:27:00+00:00rocksdb v5.8.7rocksdb v5.8.72017-11-29T05:31:37+00:00### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower2017-11-29T05:31:37+00:00rocksdb rocksdb-5.8.7rocksdb rocksdb-5.8.72017-11-29T05:32:04+00:00### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower2017-11-29T05:32:04+00:00rocksdb rocksdb-5.8.8rocksdb rocksdb-5.8.82017-12-07T03:28:39+00:00### Bug Fixes
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.2017-12-07T03:28:39+00:00rocksdb v5.8.8rocksdb v5.8.82017-12-07T03:29:46+00:00### Bug Fixes
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.2017-12-07T03:29:46+00:00rocksdb v5.9.2rocksdb v5.9.22017-12-19T02:00:52+00:00### Public API Change
* `BackupableDBOptions::max_valid_backups_to_open == 0` now means no backups will be opened during BackupEngine initialization. Previously this condition disabled limiting backups opened.
* `DBOptions::preserve_deletes` is a new option that allows one to specify that DB should not drop tombstones for regular deletes if they have sequence number larger than what was set by the new API call `DB::SetPreserveDeletesSequenceNumber(SequenceNumber seqnum)`. Disabled by default.
* API call `DB::SetPreserveDeletesSequenceNumber(SequenceNumber seqnum)` was added, users who wish to preserve deletes are expected to periodically call this function to advance the cutoff seqnum (all deletes made before this seqnum can be dropped by DB). It's user responsibility to figure out how to advance the seqnum in the way so the tombstones are kept for the desired period of time, yet are eventually processed in time and don't eat up too much space.
* `ReadOptions::iter_start_seqnum` was added; if set to something > 0 user will see 2 changes in iterators behavior 1) only keys written with sequence larger than this parameter would be returned and 2) the `Slice` returned by iter->key() now points to the the memory that keep User-oriented representation of the internal key, rather than user key. New struct `FullKey` was added to represent internal keys, along with a new helper function `ParseFullKey(const Slice& internal_key, FullKey* result);`.
* Deprecate trash_dir param in NewSstFileManager, right now we will rename deleted files to <name>.trash instead of moving them to trash directory
* Return an error on write if write_options.sync = true and write_options.disableWAL = true to warn user of inconsistent options. Previously we will not write to WAL and not respecting the sync options in this case.
### New Features
* `DBOptions::writable_file_max_buffer_size` can now be changed dynamically.
* `DBOptions::bytes_per_sync` and `DBOptions::wal_bytes_per_sync` can now be changed dynamically, `DBOptions::wal_bytes_per_sync` will flush all memtables and switch to a new WAL file.
* Support dynamic adjustment of rate limit according to demand for background I/O. It can be enabled by passing `true` to the `auto_tuned` parameter in `NewGenericRateLimiter()`. The value passed as `rate_bytes_per_sec` will still be respected as an upper-bound.
* Support dynamically changing `ColumnFamilyOptions::compaction_options_fifo`.
* Introduce `EventListener::OnStallConditionsChanged()` callback. Users can implement it to be notified when user writes are stalled, stopped, or resumed.
* Add a new db property "rocksdb.estimate-oldest-key-time" to return oldest data timestamp. The property is available only for FIFO compaction with compaction_options_fifo.allow_compaction = false.
* Upon snapshot release, recompact bottommost files containing deleted/overwritten keys that previously could not be dropped due to the snapshot. This alleviates space-amp caused by long-held snapshots.
* Support lower bound on iterators specified via `ReadOptions::iterate_lower_bound`.
* Support for differential snapshots (via iterator emitting the sequence of key-values representing the difference between DB state at two different sequence numbers). Supports preserving and emitting puts and regular deletes, doesn't support SingleDeletes, MergeOperator, Blobs and Range Deletes.
### Bug Fixes
* Fix a potential data inconsistency issue during point-in-time recovery. `DB:Open()` will abort if column family inconsistency is found during PIT recovery.
* Fix possible metadata corruption in databases using `DeleteRange()`.
* Fix IOError on WAL write doesn't propagate to write group follower
* Fix calculating filter partition target size
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.2017-12-19T02:00:52+00:00rocksdb rocksdb-5.9.2rocksdb rocksdb-5.9.22017-12-19T02:02:35+00:00### Public API Change
* `BackupableDBOptions::max_valid_backups_to_open == 0` now means no backups will be opened during BackupEngine initialization. Previously this condition disabled limiting backups opened.
* `DBOptions::preserve_deletes` is a new option that allows one to specify that DB should not drop tombstones for regular deletes if they have sequence number larger than what was set by the new API call `DB::SetPreserveDeletesSequenceNumber(SequenceNumber seqnum)`. Disabled by default.
* API call `DB::SetPreserveDeletesSequenceNumber(SequenceNumber seqnum)` was added, users who wish to preserve deletes are expected to periodically call this function to advance the cutoff seqnum (all deletes made before this seqnum can be dropped by DB). It's user responsibility to figure out how to advance the seqnum in the way so the tombstones are kept for the desired period of time, yet are eventually processed in time and don't eat up too much space.
* `ReadOptions::iter_start_seqnum` was added; if set to something > 0 user will see 2 changes in iterators behavior 1) only keys written with sequence larger than this parameter would be returned and 2) the `Slice` returned by iter->key() now points to the the memory that keep User-oriented representation of the internal key, rather than user key. New struct `FullKey` was added to represent internal keys, along with a new helper function `ParseFullKey(const Slice& internal_key, FullKey* result);`.
* Deprecate trash_dir param in NewSstFileManager, right now we will rename deleted files to <name>.trash instead of moving them to trash directory
* Return an error on write if write_options.sync = true and write_options.disableWAL = true to warn user of inconsistent options. Previously we will not write to WAL and not respecting the sync options in this case.
### New Features
* `DBOptions::writable_file_max_buffer_size` can now be changed dynamically.
* `DBOptions::bytes_per_sync` and `DBOptions::wal_bytes_per_sync` can now be changed dynamically, `DBOptions::wal_bytes_per_sync` will flush all memtables and switch to a new WAL file.
* Support dynamic adjustment of rate limit according to demand for background I/O. It can be enabled by passing `true` to the `auto_tuned` parameter in `NewGenericRateLimiter()`. The value passed as `rate_bytes_per_sec` will still be respected as an upper-bound.
* Support dynamically changing `ColumnFamilyOptions::compaction_options_fifo`.
* Introduce `EventListener::OnStallConditionsChanged()` callback. Users can implement it to be notified when user writes are stalled, stopped, or resumed.
* Add a new db property "rocksdb.estimate-oldest-key-time" to return oldest data timestamp. The property is available only for FIFO compaction with compaction_options_fifo.allow_compaction = false.
* Upon snapshot release, recompact bottommost files containing deleted/overwritten keys that previously could not be dropped due to the snapshot. This alleviates space-amp caused by long-held snapshots.
* Support lower bound on iterators specified via `ReadOptions::iterate_lower_bound`.
* Support for differential snapshots (via iterator emitting the sequence of key-values representing the difference between DB state at two different sequence numbers). Supports preserving and emitting puts and regular deletes, doesn't support SingleDeletes, MergeOperator, Blobs and Range Deletes.
### Bug Fixes
* Fix a potential data inconsistency issue during point-in-time recovery. `DB:Open()` will abort if column family inconsistency is found during PIT recovery.
* Fix possible metadata corruption in databases using `DeleteRange()`.
* Fix IOError on WAL write doesn't propagate to write group follower
* Fix calculating filter partition target size
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.2017-12-19T02:02:35+00:00rocksdb v5.10.2rocksdb v5.10.22018-02-05T18:54:24+00:00### Public API Change
* When running `make` with environment variable `USE_SSE` set and `PORTABLE` unset, will use all machine features available locally. Previously this combination only compiled SSE-related features.
### New Features
* CRC32C is now using the 3-way pipelined SSE algorithm `crc32c_3way` on supported platforms to improve performance. The system will choose to use this algorithm on supported platforms automatically whenever possible. If PCLMULQDQ is not supported it will fall back to the old Fast_CRC32 algorithm.
* Provide lifetime hints when writing files on Linux. This reduces hardware write-amp on storage devices supporting multiple streams.
* Add a DB stat, `NUMBER_ITER_SKIP`, which returns how many internal keys were skipped during iterations (e.g., due to being tombstones or duplicate versions of a key).
* Add PerfContext counters, `key_lock_wait_count` and `key_lock_wait_time`, which measure the number of times transactions wait on key locks and total amount of time waiting.
### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower
* Make iterator invalid on merge error.
* Fix performance issue in `IngestExternalFile()` affecting databases with large number of SST files.
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.
* Fix DB::Flush() keep waiting after flush finish under certain condition.2018-02-05T18:54:24+00:00rocksdb v5.10.3rocksdb v5.10.32018-02-21T23:34:15+00:00## 5.10.3 (02/21/2018)
### Bug fixes
* Fix build break regression using gcc-7
* Direct I/O writable file should do fsync in Close()
### New Features
* Add rocksdb.iterator.internal-key property
## 5.10.1 (01/18/2018)
### Bug Fixes
* Fix DB::Flush() keep waiting after flush finish under certain condition.
## 5.10.0 (12/11/2017)
### Public API Change
* When running `make` with environment variable `USE_SSE` set and `PORTABLE` unset, will use all machine features available locally. Previously this combination only compiled SSE-related features.
### New Features
* CRC32C is now using the 3-way pipelined SSE algorithm `crc32c_3way` on supported platforms to improve performance. The system will choose to use this algorithm on supported platforms automatically whenever possible. If PCLMULQDQ is not supported it will fall back to the old Fast_CRC32 algorithm.
* Provide lifetime hints when writing files on Linux. This reduces hardware write-amp on storage devices supporting multiple streams.
* Add a DB stat, `NUMBER_ITER_SKIP`, which returns how many internal keys were skipped during iterations (e.g., due to being tombstones or duplicate versions of a key).
* Add PerfContext counters, `key_lock_wait_count` and `key_lock_wait_time`, which measure the number of times transactions wait on key locks and total amount of time waiting.
### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower
* Make iterator invalid on merge error.
* Fix performance issue in `IngestExternalFile()` affecting databases with large number of SST files.
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.2018-02-21T23:34:15+00:00rocksdb rocksdb-5.10.3rocksdb rocksdb-5.10.32018-02-21T23:34:57+00:002018-02-21T23:34:57+00:00rocksdb v5.10.4rocksdb v5.10.42018-03-01T19:17:09+00:00## 5.10.4 (02/22/2018)
### New Features
* Follow rsync-style naming convention for BackupEngine tempfiles. This enables some optimizations when run on GlusterFS.
### Bug fixes
* Fix regression of Java build break on Windows.
## 5.10.3 (02/21/2018)
### Bug fixes
* Fix build break regression using gcc-7
* Direct I/O writable file should do fsync in Close()
### New Features
* Add rocksdb.iterator.internal-key property
## 5.10.1 (01/18/2018)
### Bug Fixes
* Fix DB::Flush() keep waiting after flush finish under certain condition.
## 5.10.0 (12/11/2017)
### Public API Change
* When running `make` with environment variable `USE_SSE` set and `PORTABLE` unset, will use all machine features available locally. Previously this combination only compiled SSE-related features.
### New Features
* CRC32C is now using the 3-way pipelined SSE algorithm `crc32c_3way` on supported platforms to improve performance. The system will choose to use this algorithm on supported platforms automatically whenever possible. If PCLMULQDQ is not supported it will fall back to the old Fast_CRC32 algorithm.
* Provide lifetime hints when writing files on Linux. This reduces hardware write-amp on storage devices supporting multiple streams.
* Add a DB stat, `NUMBER_ITER_SKIP`, which returns how many internal keys were skipped during iterations (e.g., due to being tombstones or duplicate versions of a key).
* Add PerfContext counters, `key_lock_wait_count` and `key_lock_wait_time`, which measure the number of times transactions wait on key locks and total amount of time waiting.
### Bug Fixes
* Fix IOError on WAL write doesn't propagate to write group follower
* Make iterator invalid on merge error.
* Fix performance issue in `IngestExternalFile()` affecting databases with large number of SST files.
* Fix possible corruption to LSM structure when `DeleteFilesInRange()` deletes a subset of files spanned by a `DeleteRange()` marker.
2018-03-01T19:17:09+00:00rocksdb rocksdb-5.10.4rocksdb rocksdb-5.10.42018-03-01T19:17:55+00:002018-03-01T19:17:55+00:00rocksdb v5.11.2rocksdb v5.11.22018-03-12T17:30:43+00:00## 5.11.2 (02/24/2018)
### Bug Fixes
* Fix bug in iterator readahead causing blocks to incorrectly be considered truncated (corrupted).
## 5.11.1 (02/22/2018)
### New Features
* Follow rsync-style naming convention for BackupEngine tempfiles. This enables some optimizations when run on GlusterFS.
## 5.11.0 (01/08/2018)
### Public API Change
* Add `autoTune` and `getBytesPerSecond()` to RocksJava RateLimiter
### New Features
* Add a new histogram stat called rocksdb.db.flush.micros for memtable flush.
* Add "--use_txn" option to use transactional API in db_stress.
* Disable onboard cache for compaction output in Windows platform.
* Improve the performance of iterators doing long range scans by using readahead.
### Bug Fixes
* Fix a stack-use-after-scope bug in ForwardIterator.
* Fix builds on platforms including Linux, Windows, and PowerPC.
* Fix buffer overrun in backup engine for DBs with huge number of files.
* Fix a mislabel bug for bottom-pri compaction threads.
* Fix DB::Flush() keep waiting after flush finish under certain condition.2018-03-12T17:30:43+00:00rocksdb rocksdb-5.11.2rocksdb rocksdb-5.11.22018-03-12T17:33:18+00:00## 5.11.2 (02/24/2018)
### Bug Fixes
* Fix bug in iterator readahead causing blocks to incorrectly be considered truncated (corrupted).
## 5.11.1 (02/22/2018)
### New Features
* Follow rsync-style naming convention for BackupEngine tempfiles. This enables some optimizations when run on GlusterFS.
## 5.11.0 (01/08/2018)
### Public API Change
* Add `autoTune` and `getBytesPerSecond()` to RocksJava RateLimiter
### New Features
* Add a new histogram stat called rocksdb.db.flush.micros for memtable flush.
* Add "--use_txn" option to use transactional API in db_stress.
* Disable onboard cache for compaction output in Windows platform.
* Improve the performance of iterators doing long range scans by using readahead.
### Bug Fixes
* Fix a stack-use-after-scope bug in ForwardIterator.
* Fix builds on platforms including Linux, Windows, and PowerPC.
* Fix buffer overrun in backup engine for DBs with huge number of files.
* Fix a mislabel bug for bottom-pri compaction threads.
* Fix DB::Flush() keep waiting after flush finish under certain condition.2018-03-12T17:33:18+00:00rocksdb rocksdb-5.11.3rocksdb rocksdb-5.11.32018-03-12T18:52:33+00:00## 5.11.2 (02/24/2018)
### Bug Fixes
* Fix bug in iterator readahead causing blocks to incorrectly be considered truncated (corrupted).
## 5.11.1 (02/22/2018)
### New Features
* Follow rsync-style naming convention for BackupEngine tempfiles. This enables some optimizations when run on GlusterFS.
## 5.11.0 (01/08/2018)
### Public API Change
* Add `autoTune` and `getBytesPerSecond()` to RocksJava RateLimiter
### New Features
* Add a new histogram stat called rocksdb.db.flush.micros for memtable flush.
* Add "--use_txn" option to use transactional API in db_stress.
* Disable onboard cache for compaction output in Windows platform.
* Improve the performance of iterators doing long range scans by using readahead.
### Bug Fixes
* Fix a stack-use-after-scope bug in ForwardIterator.
* Fix builds on platforms including Linux, Windows, and PowerPC.
* Fix buffer overrun in backup engine for DBs with huge number of files.
* Fix a mislabel bug for bottom-pri compaction threads.
* Fix DB::Flush() keep waiting after flush finish under certain condition.2018-03-12T18:52:33+00:00rocksdb v5.11.3rocksdb v5.11.32018-03-12T18:56:46+00:00## 5.11.2 (02/24/2018)
### Bug Fixes
* Fix bug in iterator readahead causing blocks to incorrectly be considered truncated (corrupted).
## 5.11.1 (02/22/2018)
### New Features
* Follow rsync-style naming convention for BackupEngine tempfiles. This enables some optimizations when run on GlusterFS.
## 5.11.0 (01/08/2018)
### Public API Change
* Add `autoTune` and `getBytesPerSecond()` to RocksJava RateLimiter
### New Features
* Add a new histogram stat called rocksdb.db.flush.micros for memtable flush.
* Add "--use_txn" option to use transactional API in db_stress.
* Disable onboard cache for compaction output in Windows platform.
* Improve the performance of iterators doing long range scans by using readahead.
### Bug Fixes
* Fix a stack-use-after-scope bug in ForwardIterator.
* Fix builds on platforms including Linux, Windows, and PowerPC.
* Fix buffer overrun in backup engine for DBs with huge number of files.
* Fix a mislabel bug for bottom-pri compaction threads.
* Fix DB::Flush() keep waiting after flush finish under certain condition.2018-03-12T18:56:46+00:00rocksdb v5.12.2rocksdb v5.12.22018-04-03T23:47:31+00:00## 5.12.2 (3/23/2018)
### Bug Fixes
* Fsync after writing global seq number to the ingestion file in ExternalSstFileIngestionJob.
### Java API Changes
* Add `BlockBasedTableConfig.setBlockCache` to allow sharing a block cache across DB instances.
## 5.12.1 (3/16/2018)
### Public API Change
* RocksDBOptionsParser::Parse()'s `ignore_unknown_options` argument will only be effective if the option file shows it is generated using a higher version of RocksDB than the current version.
### New Features
* Avoid unnecessarily flushing in `CompactRange()` when the range specified by the user does not overlap unflushed memtables.
### Bug Fixes
* Fix WAL corruption caused by race condition between user write thread and backup/checkpoint thread.
## 5.12.0 (2/14/2018)
### Public API Change
* Iterator::SeekForPrev is now a pure virtual method. This is to prevent user who implement the Iterator interface fail to implement SeekForPrev by mistake.
* Add `include_end` option to make the range end exclusive when `include_end == false` in `DeleteFilesInRange()`.
* Add `CompactRangeOptions::allow_write_stall`, which makes `CompactRange` start working immediately, even if it causes user writes to stall. The default value is false, meaning we add delay to `CompactRange` calls until stalling can be avoided when possible. Note this delay is not present in previous RocksDB versions.
* Creating checkpoint with empty directory now returns `Status::InvalidArgument`; previously, it returned `Status::IOError`.
* Adds a BlockBasedTableOption to turn off index block compression.
* Close() method now returns a status when closing a db.
### New Features
* Improve the performance of iterators doing long range scans by using readahead.
* Add new function `DeleteFilesInRanges()` to delete files in multiple ranges at once for better performance.
* FreeBSD build support for RocksDB and RocksJava.
* Improved performance of long range scans with readahead.
* Updated to and now continuously tested in Visual Studio 2017.
### Bug Fixes
* Fix `DisableFileDeletions()` followed by `GetSortedWalFiles()` to not return obsolete WAL files that `PurgeObsoleteFiles()` is going to delete.
* Fix Handle error return from WriteBuffer() during WAL file close and DB close.
* Fix advance reservation of arena block addresses.
* Fix handling of empty string as checkpoint directory.2018-04-03T23:47:31+00:00rocksdb v5.12.4rocksdb v5.12.42018-04-23T18:47:41+00:00## 5.12.4 (4/23/2018)
### Bug Fixes
* Fix memory leak in two_level_iterator
## 5.12.3 (4/23/2018)
### Bug Fixes
* Fix memory leak when pin_l0_filter_and_index_blocks_in_cache is used with partitioned filters
## 5.12.2 (3/23/2018)
### Bug Fixes
* Fsync after writing global seq number to the ingestion file in ExternalSstFileIngestionJob.
### Java API Changes
* Add `BlockBasedTableConfig.setBlockCache` to allow sharing a block cache across DB instances.
## 5.12.1 (3/16/2018)
### Public API Change
* RocksDBOptionsParser::Parse()'s `ignore_unknown_options` argument will only be effective if the option file shows it is generated using a higher version of RocksDB than the current version.
### New Features
* Avoid unnecessarily flushing in `CompactRange()` when the range specified by the user does not overlap unflushed memtables.
### Bug Fixes
* Fix WAL corruption caused by race condition between user write thread and backup/checkpoint thread.
## 5.12.0 (2/14/2018)
### Public API Change
* Iterator::SeekForPrev is now a pure virtual method. This is to prevent user who implement the Iterator interface fail to implement SeekForPrev by mistake.
* Add `include_end` option to make the range end exclusive when `include_end == false` in `DeleteFilesInRange()`.
* Add `CompactRangeOptions::allow_write_stall`, which makes `CompactRange` start working immediately, even if it causes user writes to stall. The default value is false, meaning we add delay to `CompactRange` calls until stalling can be avoided when possible. Note this delay is not present in previous RocksDB versions.
* Creating checkpoint with empty directory now returns `Status::InvalidArgument`; previously, it returned `Status::IOError`.
* Adds a BlockBasedTableOption to turn off index block compression.
* Close() method now returns a status when closing a db.
### New Features
* Improve the performance of iterators doing long range scans by using readahead.
* Add new function `DeleteFilesInRanges()` to delete files in multiple ranges at once for better performance.
* FreeBSD build support for RocksDB and RocksJava.
* Improved performance of long range scans with readahead.
* Updated to and now continuously tested in Visual Studio 2017.
### Bug Fixes
* Fix `DisableFileDeletions()` followed by `GetSortedWalFiles()` to not return obsolete WAL files that `PurgeObsoleteFiles()` is going to delete.
* Fix Handle error return from WriteBuffer() during WAL file close and DB close.
* Fix advance reservation of arena block addresses.
* Fix handling of empty string as checkpoint directory.2018-04-23T18:47:41+00:00rocksdb v5.13.1rocksdb v5.13.12018-05-14T19:16:00+00:00## 5.13.1 (4/30/2018)
### New Features
* Add `Env::LowerThreadPoolCPUPriority(Priority)` method, which lowers the CPU priority of background (esp. compaction) threads to minimize interference with foreground tasks.
* Eliminate use of temporary directories in BackupEngine to improve reliability on distributed file systems.
## 5.13.0 (3/20/2018)
### Public API Change
* RocksDBOptionsParser::Parse()'s `ignore_unknown_options` argument will only be effective if the option file shows it is generated using a higher version of RocksDB than the current version.
* Remove CompactionEventListener.
### New Features
* SstFileManager now can cancel compactions if they will result in max space errors. SstFileManager users can also use SetCompactionBufferSize to specify how much space must be leftover during a compaction for auxiliary file functions such as logging and flushing.
* Avoid unnecessarily flushing in `CompactRange()` when the range specified by the user does not overlap unflushed memtables.
* If `ColumnFamilyOptions::max_subcompactions` is set greater than one, we now parallelize large manual level-based compactions.
* Add "rocksdb.live-sst-files-size" DB property to return total bytes of all SST files belong to the latest LSM tree.
### Bug Fixes
* Fix a leak in prepared_section_completed_ where the zeroed entries would not removed from the map.
* Fix WAL corruption caused by race condition between user write thread and backup/checkpoint thread.
* Fsync after writing global seq number to the ingestion file in ExternalSstFileIngestionJob.
* Fix memory leak when pin_l0_filter_and_index_blocks_in_cache is used with partitioned filters
### Java API Changes
* Add `BlockBasedTableConfig.setBlockCache` to allow sharing a block cache across DB instances.
2018-05-14T19:16:00+00:00rocksdb v5.13.2rocksdb v5.13.22018-05-25T23:43:54+00:00## 5.13.2 (5/25/2018)
### Public API Change
* Introduced `CompressionOptions::kDefaultCompressionLevel`, which is a generic way to tell RocksDB to use the compression library's default level. It is now the default value for `CompressionOptions::level`. Previously the level defaulted to -1, which gave poor compression ratios in ZSTD.
### Bug Fixes
* Fix segfault caused by object premature destruction (PR #3898)
* Fix an issue with unnecessary capture in lambda expressions (PR #3904)2018-05-25T23:43:54+00:00rocksdb v5.13.3rocksdb v5.13.32018-06-07T17:27:00+00:00## 5.13.3 (6/6/2018)
### Bug Fixes
* Fix assertion when reading bloom filter of SST files containing range deletions but no data
2018-06-07T17:27:00+00:00rocksdb v5.12.5rocksdb v5.12.52018-06-18T17:11:15+00:00### Bug Fixes
* Fix regression bug of Prev() with ReadOptions.iterate_upper_bound.2018-06-18T17:11:15+00:00rocksdb v5.13.4rocksdb v5.13.42018-06-18T17:15:14+00:00### Bug Fixes
* Fix regression bug of Prev() with ReadOptions.iterate_upper_bound.2018-06-18T17:15:14+00:00rocksdb v5.14.2rocksdb v5.14.22018-07-04T17:06:35+00:00## 5.14.2 (7/3/2018)
### Bug Fixes
* Change default value of `bytes_max_delete_chunk` to 0 in NewSstFileManager() as it doesn't work well with checkpoints.
* Set DEBUG_LEVEL=0 for RocksJava Mac Release build.
## 5.14.1 (6/20/2018)
### Bug Fixes
* Fix block-based table reader pinning blocks throughout its lifetime, causing memory usage increase.
* Fix bug with prefix search in partition filters where a shared prefix would be ignored from the later partitions. The bug could report an eixstent key as missing. The bug could be triggered if prefix_extractor is set and partition filters is enabled.
## 5.14.0 (5/16/2018)
### Public API Change
* Add a BlockBasedTableOption to align uncompressed data blocks on the smaller of block size or page size boundary, to reduce flash reads by avoiding reads spanning 4K pages.
* The background thread naming convention changed (on supporting platforms) to "rocksdb:<thread pool priority><thread number>", e.g., "rocksdb:low0".
* Add a new ticker stat rocksdb.number.multiget.keys.found to count number of keys successfully read in MultiGet calls
* Touch-up to write-related counters in PerfContext. New counters added: write_scheduling_flushes_compactions_time, write_thread_wait_nanos. Counters whose behavior was fixed or modified: write_memtable_time, write_pre_and_post_process_time, write_delay_time.
* Posix Env's NewRandomRWFile() will fail if the file doesn't exist.
* Now, `DBOptions::use_direct_io_for_flush_and_compaction` only applies to background writes, and `DBOptions::use_direct_reads` applies to both user reads and background reads. This conforms with Linux's `open(2)` manpage, which advises against simultaneously reading a file in buffered and direct modes, due to possibly undefined behavior and degraded performance.
* Iterator::Valid() always returns false if !status().ok(). So, now when doing a Seek() followed by some Next()s, there's no need to check status() after every operation.
* Iterator::Seek()/SeekForPrev()/SeekToFirst()/SeekToLast() always resets status().
### New Features
* Introduce TTL for level compaction so that all files older than ttl go through the compaction process to get rid of old data.
* TransactionDBOptions::write_policy can be configured to enable WritePrepared 2PC transactions. Read more about them in the wiki.
* Add DB properties "rocksdb.block-cache-capacity", "rocksdb.block-cache-usage", "rocksdb.block-cache-pinned-usage" to show block cache usage.
* Add `Env::LowerThreadPoolCPUPriority(Priority)` method, which lowers the CPU priority of background (esp. compaction) threads to minimize interference with foreground tasks.
* Fsync parent directory after deleting a file in delete scheduler.
* In level-based compaction, if bottom-pri thread pool was setup via `Env::SetBackgroundThreads()`, compactions to the bottom level will be delegated to that thread pool.
### Bug Fixes
* Fsync after writing global seq number to the ingestion file in ExternalSstFileIngestionJob.
* Fix WAL corruption caused by race condition between user write thread and FlushWAL when two_write_queue is not set.
* Fix `BackupableDBOptions::max_valid_backups_to_open` to not delete backup files when refcount cannot be accurately determined.
* Fix memory leak when pin_l0_filter_and_index_blocks_in_cache is used with partitioned filters
* Disable rollback of merge operands in WritePrepared transactions to work around an issue in MyRocks. It can be enabled back by setting TransactionDBOptions::rollback_merge_operands to true.
* Fix bug with prefix search in partition filters where a shared prefix would be ignored from the later partitions. The bug could report an eixstent key as missing. The bug could be triggered if prefix_extractor is set and partition filters is enabled.
### Java API Changes
* Add `BlockBasedTableConfig.setBlockCache` to allow sharing a block cache across DB instances.
* Added SstFileManager to the Java API to allow managing SST files across DB instances.
2018-07-04T17:06:35+00:00rocksdb rocksdb-5.14.3rocksdb rocksdb-5.14.32018-08-22T00:37:35+00:00## 5.14.3 (8/21/2018)
### Public API Change
* The merge operands are passed to `MergeOperator::ShouldMerge` in the reversed order relative to how they were merged (passed to FullMerge or FullMergeV2) for performance reasons
### Bug Fixes
* Fixes DBImpl::FindObsoleteFiles() calling GetChildren() on the same path2018-08-22T00:37:35+00:00rocksdb v5.14.3rocksdb v5.14.32018-08-26T20:33:52+00:00## 5.14.3 (8/21/2018)
### Public API Change
* The merge operands are passed to `MergeOperator::ShouldMerge` in the reversed order relative to how they were merged (passed to FullMerge or FullMergeV2) for performance reasons
### Bug Fixes
* Fixes DBImpl::FindObsoleteFiles() calling GetChildren() on the same path2018-08-26T20:33:52+00:00rocksdb v5.15.10rocksdb v5.15.102018-09-14T17:21:43+00:00# Rocksdb Change Log
### 5.15.10 (9/13/2018)
### Bug Fixes
* Fix RocksDB Java build and tests.
### 5.15.9 (9/4/2018)
### Bug Fixes
* Fix compilation errors on OS X clang due to '-Wsuggest-override'.
## 5.15.8 (8/31/2018)
### Bug Fixes
* Further avoid creating empty SSTs and subsequently deleting them during compaction.
## 5.15.7 (8/24/2018)
### Bug Fixes
* Avoid creating empty SSTs and subsequently deleting them in certain cases during compaction.
## 5.15.6 (8/21/2018)
### Public API Change
* The merge operands are passed to `MergeOperator::ShouldMerge` in the reversed order relative to how they were merged (passed to FullMerge or FullMergeV2) for performance reasons
## 5.15.5 (8/16/2018)
### Bug Fixes
* Fix VerifyChecksum() API not preserving options
## 5.15.4 (8/11/2018)
### Bug Fixes
* Fix a bug caused by not generating OnTableFileCreated() notification for a 0-byte SST.
## 5.15.3 (8/10/2018)
### Bug Fixes
* Fix a bug in misreporting the estimated partition index size in properties block.
## 5.15.2 (8/9/2018)
### Bug Fixes
* Return correct usable_size for BlockContents.
## 5.15.1 (8/1/2018)
### Bug Fixes
* Prevent dereferencing invalid STL iterators when there are range tombstones in ingested files.
## 5.15.0 (7/17/2018)
### Public API Change
* Remove managed iterator. ReadOptions.managed is not effective anymore.
* For bottommost_compression, a compatible CompressionOptions is added via `bottommost_compression_opts`. To keep backward compatible, a new boolean `enabled` is added to CompressionOptions. For compression_opts, it will be always used no matter what value of `enabled` is. For bottommost_compression_opts, it will only be used when user set `enabled=true`, otherwise, compression_opts will be used for bottommost_compression as default.
* With LRUCache, when high_pri_pool_ratio > 0, midpoint insertion strategy will be enabled to put low-pri items to the tail of low-pri list (the midpoint) when they first inserted into the cache. This is to make cache entries never get hit age out faster, improving cache efficiency when large background scan presents.
* For users of `Statistics` objects created via `CreateDBStatistics()`, the format of the string returned by its `ToString()` method has changed.
* The "rocksdb.num.entries" table property no longer counts range deletion tombstones as entries.
### New Features
* Changes the format of index blocks by storing the key in their raw form rather than converting them to InternalKey. This saves 8 bytes per index key. The feature is backward compatbile but not forward compatible. It is disabled by default unless format_version 3 or above is used.
* Avoid memcpy when reading mmap files with OpenReadOnly and max_open_files==-1.
* Support dynamically changing `ColumnFamilyOptions::ttl` via `SetOptions()`.
* Add a new table property, "rocksdb.num.range-deletions", which counts the number of range deletion tombstones in the table.
* Improve the performance of iterators doing long range scans by using readahead, when using direct IO.
* pin_top_level_index_and_filter (default true) in BlockBasedTableOptions can be used in combination with cache_index_and_filter_blocks to prefetch and pin the top-level index of partitioned index and filter blocks in cache. It has no impact when cache_index_and_filter_blocks is false.
### Bug Fixes
* Fix deadlock with enable_pipelined_write=true and max_successive_merges > 0
* Check conflict at output level in CompactFiles.
* Fix corruption in non-iterator reads when mmap is used for file reads
* Fix bug with prefix search in partition filters where a shared prefix would be ignored from the later partitions. The bug could report an eixstent key as missing. The bug could be triggered if prefix_extractor is set and partition filters is enabled.
* Change default value of `bytes_max_delete_chunk` to 0 in NewSstFileManager() as it doesn't work well with checkpoints.
* Fix a bug caused by not copying the block trailer with compressed SST file, direct IO, prefetcher and no compressed block cache.
* Fix write can stuck indefinitely if enable_pipelined_write=true. The issue exists since pipelined write was introduced in 5.5.0.2018-09-14T17:21:43+00:00rocksdb v5.16.6rocksdb v5.16.62018-11-12T21:13:27+00:00# Rocksdb Change Log
# 5.16.6 (10/24/2018)
### Bug Fixes
* Fix the bug that WriteBatchWithIndex's SeekForPrev() doesn't see the entries with the same key.
## 5.16.5 (10/16/2018)
### Bug Fixes
* Fix slow flush/compaction when DB contains many snapshots. The problem became noticeable to us in DBs with 100,000+ snapshots, though it will affect others at different thresholds.
* Properly set the stop key for a truncated manual CompactRange
## 5.16.4 (10/10/2018)
### Bug Fixes
* Fix corner case where a write group leader blocked due to write stall blocks other writers in queue with WriteOptions::no_slowdown set.
## 5.16.3 (10/1/2018)
### Bug Fixes
* Fix crash caused when `CompactFiles` run with `CompactionOptions::compression == CompressionType::kDisableCompressionOption`. Now that setting causes the compression type to be chosen according to the column family-wide compression options.
## 5.16.2 (9/21/2018)
### Bug Fixes
* Fix bug in partition filters with format_version=4.
## 5.16.1 (9/17/2018)
### Bug Fixes
* Remove trace_analyzer_tool from rocksdb_lib target in TARGETS file.
* Fix RocksDB Java build and tests.
* Remove sync point in Block destructor.
## 5.16.0 (8/21/2018)
### Public API Change
* `OnTableFileCreated` will now be called for empty files generated during compaction. In that case, `TableFileCreationInfo::file_path` will be "(nil)" and `TableFileCreationInfo::file_size` will be zero.
* Add `FlushOptions::allow_write_stall`, which controls whether Flush calls start working immediately, even if it causes user writes to stall, or will wait until flush can be performed without causing write stall (similar to `CompactRangeOptions::allow_write_stall`). Note that the default value is false, meaning we add delay to Flush calls until stalling can be avoided when possible. This is behavior change compared to previous RocksDB versions, where Flush calls didn't check if they might cause stall or not.
* The merge operands are passed to `MergeOperator::ShouldMerge` in the reversed order relative to how they were merged (passed to FullMerge or FullMergeV2) for performance reasons
* GetAllKeyVersions() to take an extra argument of `max_num_ikeys`.
### New Features
* Changes the format of index blocks by delta encoding the index values, which are the block handles. This saves the encoding of BlockHandle::offset of the non-head index entries in each restart interval. The feature is backward compatible but not forward compatible. It is disabled by default unless format_version 4 or above is used.
* Add a new tool: trace_analyzer. Trace_analyzer analyzes the trace file generated by using trace_replay API. It can convert the binary format trace file to a human readable txt file, output the statistics of the analyzed query types such as access statistics and size statistics, combining the dumped whole key space file to analyze, support query correlation analyzing, and etc. Current supported query types are: Get, Put, Delete, SingleDelete, DeleteRange, Merge, Iterator (Seek, SeekForPrev only).
* Add hash index support to data blocks, which helps reducing the cpu utilization of point-lookup operations. This feature is backward compatible with the data block created without the hash index. It is disabled by default unless BlockBasedTableOptions::data_block_index_type is set to data_block_index_type = kDataBlockBinaryAndHash.
### Bug Fixes
* Fix a bug in misreporting the estimated partition index size in properties block.
* Avoid creating empty SSTs and subsequently deleting them in certain cases during compaction.2018-11-12T21:13:27+00:00rocksdb v5.17.2rocksdb v5.17.22018-11-12T21:14:07+00:00# Rocksdb Change Log
# 5.17.2 (10/24/2018)
### Bug Fixes
* Fix the bug that WriteBatchWithIndex's SeekForPrev() doesn't see the entries with the same key.
# 5.17.1 (10/16/2018)
### Bug Fixes
* Fix slow flush/compaction when DB contains many snapshots. The problem became noticeable to us in DBs with 100,000+ snapshots, though it will affect others at different thresholds.
* Properly set the stop key for a truncated manual CompactRange
* Fix corner case where a write group leader blocked due to write stall blocks other writers in queue with WriteOptions::no_slowdown set.
### New Features
* Introduced CacheAllocator, which lets the user specify custom allocator for memory in block cache.
## 5.17.0 (10/05/2018)
### Public API Change
* `OnTableFileCreated` will now be called for empty files generated during compaction. In that case, `TableFileCreationInfo::file_path` will be "(nil)" and `TableFileCreationInfo::file_size` will be zero.
* Add `FlushOptions::allow_write_stall`, which controls whether Flush calls start working immediately, even if it causes user writes to stall, or will wait until flush can be performed without causing write stall (similar to `CompactRangeOptions::allow_write_stall`). Note that the default value is false, meaning we add delay to Flush calls until stalling can be avoided when possible. This is behavior change compared to previous RocksDB versions, where Flush calls didn't check if they might cause stall or not.
* Application using PessimisticTransactionDB is expected to rollback/commit recovered transactions before starting new ones. This assumption is used to skip concurrency control during recovery.2018-11-12T21:14:07+00:00rocksdb v5.18.3rocksdb v5.18.32019-02-28T18:09:30+00:00# Rocksdb Change Log
## 5.18.3 (2/11/2019)
### Bug Fixes
* Fix possible LSM corruption when both range deletions and subcompactions are used. The symptom of this corruption is L1+ files overlapping in the user key space.
## 5.18.2 (01/31/2019)
### Public API Change
* Change time resolution in FileOperationInfo.
* Deleting Blob files also go through SStFileManager.
## 5.18.0 (11/30/2018)
### New Features
* Introduced `JemallocNodumpAllocator` memory allocator. When being use, block cache will be excluded from core dump.
* Introduced `PerfContextByLevel` as part of `PerfContext` which allows storing perf context at each level. Also replaced `__thread` with `thread_local` keyword for perf_context. Added per-level perf context for bloom filter and `Get` query.
* With level_compaction_dynamic_level_bytes = true, level multiplier may be adjusted automatically when Level 0 to 1 compaction is lagged behind.
* Introduced DB option `atomic_flush`. If true, RocksDB supports flushing multiple column families and atomically committing the result to MANIFEST. Useful when WAL is disabled.
* Added `num_deletions` and `num_merge_operands` members to `TableProperties`.
* Added "rocksdb.min-obsolete-sst-number-to-keep" DB property that reports the lower bound on SST file numbers that are being kept from deletion, even if the SSTs are obsolete.
* Add xxhash64 checksum support
* Introduced `MemoryAllocator`, which lets the user specify custom memory allocator for block based table.
* Improved `DeleteRange` to prevent read performance degradation. The feature is no longer marked as experimental.
* Enabled checkpoint on readonly db (DBImplReadOnly).
### Public API Change
* `DBOptions::use_direct_reads` now affects reads issued by `BackupEngine` on the database's SSTs.
* `NO_ITERATORS` is divided into two counters `NO_ITERATOR_CREATED` and `NO_ITERATOR_DELETE`. Both of them are only increasing now, just as other counters.
### Bug Fixes
* Fix corner case where a write group leader blocked due to write stall blocks other writers in queue with WriteOptions::no_slowdown set.
* Fix in-memory range tombstone truncation to avoid erroneously covering newer keys at a lower level, and include range tombstones in compacted files whose largest key is the range tombstone's start key.
* Properly set the stop key for a truncated manual CompactRange
* Fix slow flush/compaction when DB contains many snapshots. The problem became noticeable to us in DBs with 100,000+ snapshots, though it will affect others at different thresholds.
* Fix the bug that WriteBatchWithIndex's SeekForPrev() doesn't see the entries with the same key.
* Fix the bug where user comparator was sometimes fed with InternalKey instead of the user key. The bug manifests when during GenerateBottommostFiles.
* Fix a bug in WritePrepared txns where if the number of old snapshots goes beyond the snapshot cache size (128 default) the rest will not be checked when evicting a commit entry from the commit cache.
* Fixed Get correctness bug in the presence of range tombstones where merge operands covered by a range tombstone always result in NotFound.
* Start populating `NO_FILE_CLOSES` ticker statistic, which was always zero previously.
* The default value of NewBloomFilterPolicy()'s argument use_block_based_builder is changed to false. Note that this new default may cause large temp memory usage when building very large SST files.
* Fix a deadlock caused by compaction and file ingestion waiting for each other in the event of write stalls.
* Make DB ignore dropped column families while committing results of atomic flush.
2019-02-28T18:09:30+00:00rocksdb v6.0.1rocksdb v6.0.12019-04-16T20:28:42+00:00# Rocksdb Change Log
## 6.0.1 (3/26/2019)
### New Features
### Public API Change
* Added many new features to the Java API to bring it closer to the C++ API.
### Bug Fixes
* Make BlobDB wait for all background tasks on shutdown.
* Fixed a BlobDB issue where some trash files are not tracked causing them to remain forever.
## 6.0.0 (2/19/2019)
### New Features
* Enabled checkpoint on readonly db (DBImplReadOnly).
* Make DB ignore dropped column families while committing results of atomic flush.
* RocksDB may choose to preopen some files even if options.max_open_files != -1. This may make DB open slightly longer.
* For users of dictionary compression with ZSTD v0.7.0+, we now reuse the same digested dictionary when compressing each of an SST file's data blocks for faster compression speeds.
* For all users of dictionary compression who set `cache_index_and_filter_blocks == true`, we now store dictionary data used for decompression in the block cache for better control over memory usage. For users of ZSTD v1.1.4+ who compile with -DZSTD_STATIC_LINKING_ONLY, this includes a digested dictionary, which is used to increase decompression speed.
* Add support for block checksums verification for external SST files before ingestion.
* Introduce stats history which periodically saves Statistics snapshots and added `GetStatsHistory` API to retrieve these snapshots.
* Add a place holder in manifest which indicate a record from future that can be safely ignored.
* Add support for trace sampling.
* Enable properties block checksum verification for block-based tables.
* For all users of dictionary compression, we now generate a separate dictionary for compressing each bottom-level SST file. Previously we reused a single dictionary for a whole compaction to bottom level. The new approach achieves better compression ratios; however, it uses more memory and CPU for buffering/sampling data blocks and training dictionaries.
* Add whole key bloom filter support in memtable.
* Files written by `SstFileWriter` will now use dictionary compression if it is configured in the file writer's `CompressionOptions`.
### Public API Change
* Disallow CompactionFilter::IgnoreSnapshots() = false, because it is not very useful and the behavior is confusing. The filter will filter everything if there is no snapshot declared by the time the compaction starts. However, users can define a snapshot after the compaction starts and before it finishes and this new snapshot won't be repeatable, because after the compaction finishes, some keys may be dropped.
* CompactionPri = kMinOverlappingRatio also uses compensated file size, which boosts file with lots of tombstones to be compacted first.
* Transaction::GetForUpdate is extended with a do_validate parameter with default value of true. If false it skips validating the snapshot before doing the read. Similarly ::Merge, ::Put, ::Delete, and ::SingleDelete are extended with assume_tracked with default value of false. If true it indicates that call is assumed to be after a ::GetForUpdate.
* `TableProperties::num_entries` and `TableProperties::num_deletions` now also account for number of range tombstones.
* Remove geodb, spatial_db, document_db, json_document, date_tiered_db, and redis_lists.
* With "ldb ----try_load_options", when wal_dir specified by the option file doesn't exist, ignore it.
* Change time resolution in FileOperationInfo.
* Deleting Blob files also go through SStFileManager.
* Remove CuckooHash memtable.
* The counter stat `number.block.not_compressed` now also counts blocks not compressed due to poor compression ratio.
* Remove ttl option from `CompactionOptionsFIFO`. The option has been deprecated and ttl in `ColumnFamilyOptions` is used instead.
* Support SST file ingestion across multiple column families via DB::IngestExternalFiles. See the function's comment about atomicity.
* Remove Lua compaction filter.
### Bug Fixes
* Fix a deadlock caused by compaction and file ingestion waiting for each other in the event of write stalls.
* Fix a memory leak when files with range tombstones are read in mmap mode and block cache is enabled
* Fix handling of corrupt range tombstone blocks such that corruptions cannot cause deleted keys to reappear
* Lock free MultiGet
* Fix incorrect `NotFound` point lookup result when querying the endpoint of a file that has been extended by a range tombstone.
* Fix with pipelined write, write leaders's callback failure lead to the whole write group fail.
### Change Default Options
* Change options.compaction_pri's default to kMinOverlappingRatio2019-04-16T20:28:42+00:00rocksdb v6.0.2rocksdb v6.0.22019-04-23T22:22:29+00:00## 6.0.2 (4/23/2019)
## Bug Fixes needed for Java users
* Fix build failures due to missing JEMALLOC_CXX_THROW macro (#5053)
* Fix compilation on db_bench_tool.cc on Windows (#5227)2019-04-23T22:22:29+00:00rocksdb v6.1.1rocksdb v6.1.12019-06-03T21:24:47+00:00# Rocksdb Change Log
## 6.1.1 (4/9/2019)
### New Features
* When reading from option file/string/map, customized comparators and/or merge operators can be filled according to object registry.
### Public API Change
### Bug Fixes
* Fix a bug in 2PC where a sequence of txn prepare, memtable flush, and crash could result in losing the prepared transaction.
* Fix a bug in Encryption Env which could cause encrypted files to be read beyond file boundaries.
## 6.1.0 (3/27/2019)
### New Features
* Introduce two more stats levels, kExceptHistogramOrTimers and kExceptTimers.
* Added a feature to perform data-block sampling for compressibility, and report stats to user.
* Add support for trace filtering.
* Add DBOptions.avoid_unnecessary_blocking_io. If true, we avoid file deletion when destorying ColumnFamilyHandle and Iterator. Instead, a job is scheduled to delete the files in background.
### Public API Change
* Remove bundled fbson library.
* statistics.stats_level_ becomes atomic. It is preferred to use statistics.set_stats_level() and statistics.get_stats_level() to access it.
* Introduce a new IOError subcode, PathNotFound, to indicate trying to open a nonexistent file or directory for read.
* Add initial support for multiple db instances sharing the same data in single-writer, multi-reader mode.
* Removed some "using std::xxx" from public headers.
### Bug Fixes
* Fix JEMALLOC_CXX_THROW macro missing from older Jemalloc versions, causing build failures on some platforms.
* Fix SstFileReader not able to open file ingested with write_glbal_seqno=true.
2019-06-03T21:24:47+00:00rocksdb v6.1.2rocksdb v6.1.22019-06-04T20:41:57+00:00# Rocksdb Change Log
## 6.1.2 (6/4/2019)
### Bug Fixes
* Fix flush's/compaction's merge processing logic which allowed `Put`s covered by range tombstones to reappear. Note `Put`s may exist even if the user only ever called `Merge()` due to an internal conversion during compaction to the bottommost level.
2019-06-04T20:41:57+00:00rocksdb v6.2.2rocksdb v6.2.22019-08-02T17:51:45+00:00# Rocksdb Change Log
## 6.2.2 (6/7/2019)
### Bug Fixes
* Disable dynamic extension support by default for CMake.
## 6.2.1 (6/4/2019)
### Bug Fixes
* Fix flush's/compaction's merge processing logic which allowed `Put`s covered by range tombstones to reappear. Note `Put`s may exist even if the user only ever called `Merge()` due to an internal conversion during compaction to the bottommost level.
## 6.2.0 (4/30/2019)
### New Features
* Add an option `strict_bytes_per_sync` that causes a file-writing thread to block rather than exceed the limit on bytes pending writeback specified by `bytes_per_sync` or `wal_bytes_per_sync`.
* Improve range scan performance by avoiding per-key upper bound check in BlockBasedTableIterator.
* Introduce Periodic Compaction for Level style compaction. Files are re-compacted periodically and put in the same level.
* Block-based table index now contains exact highest key in the file, rather than an upper bound. This may improve Get() and iterator Seek() performance in some situations, especially when direct IO is enabled and block cache is disabled. A setting BlockBasedTableOptions::index_shortening is introduced to control this behavior. Set it to kShortenSeparatorsAndSuccessor to get the old behavior.
* When reading from option file/string/map, customized envs can be filled according to object registry.
* Add an option `snap_refresh_nanos` (default to 0.5s) to periodically refresh the snapshot list in compaction jobs. Assign to 0 to disable the feature.
* Improve range scan performance when using explicit user readahead by not creating new table readers for every iterator.
### Public API Change
* Change the behavior of OptimizeForPointLookup(): move away from hash-based block-based-table index, and use whole key memtable filtering.
* Change the behavior of OptimizeForSmallDb(): use a 16MB block cache, put index and filter blocks into it, and cost the memtable size to it. DBOptions.OptimizeForSmallDb() and ColumnFamilyOptions.OptimizeForSmallDb() start to take an optional cache object.
* Added BottommostLevelCompaction::kForceOptimized to avoid double compacting newly compacted files in the bottommost level compaction of manual compaction. Note this option may prohibit the manual compaction to produce a single file in the bottommost level.
### Bug Fixes
* Adjust WriteBufferManager's dummy entry size to block cache from 1MB to 256KB.
* Fix a race condition between WritePrepared::Get and ::Put with duplicate keys.
* Fix crash when memtable prefix bloom is enabled and read/write a key out of domain of prefix extractor.
* Close a WAL file before another thread deletes it.
* Fix an assertion failure `IsFlushPending() == true` caused by one bg thread releasing the db mutex in ~ColumnFamilyData and another thread clearing `flush_requested_` flag.
2019-08-02T17:51:45+00:00rocksdb v6.2.4rocksdb v6.2.42019-09-19T18:26:33+00:00# Rocksdb Change Log
## 6.2.4 (9/18/2019)
### Bug Fixes
* Disable snap_refresh_nanos by default. The feature is to be deprecated in the next release.
## 6.2.3 (9/3/2019)
### Bug Fixes
* Fix a bug in file ingestion caused by incorrect file number allocation when the number of column families involved in the ingestion exceeds 2.
2019-09-19T18:26:33+00:00rocksdb v6.3.6rocksdb v6.3.62019-10-07T17:29:09+00:00# Rocksdb Change Log
## 6.3.6 (10/1/2019)
* Revert the feature "Merging iterator to avoid child iterator reseek for some cases (#5286)" since it might cause strong results when reseek happens with a different iterator upper bound.
## 6.3.5 (9/17/2019)
* Fix a bug introduced 6.3 which could cause wrong results in a corner case when prefix bloom filter is used and the iterator is reseeked.
## 6.3.4 (9/3/2019)
### Bug Fixes
* Fix a bug in file ingestion caused by incorrect file number allocation when the number of column families involved in the ingestion exceeds 2.
## 6.3.3 (8/20/2019)
### Bug Fixes
* Fix a bug where the compaction snapshot refresh feature is not disabled as advertised when `snap_refresh_nanos` is set to 0..
## 6.3.2 (8/15/2019)
### Public API Change
* The semantics of the per-block-type block read counts in the performance context now match those of the generic block_read_count.
### Bug Fixes
* Fixed a regression where the fill_cache read option also affected index blocks.
* Fixed an issue where using cache_index_and_filter_blocks==false affected partitions of partitioned indexes as well.
## 6.3.1 (7/24/2019)
### Bug Fixes
* Fix auto rolling bug introduced in 6.3.0, which causes segfault if log file creation fails.
## 6.3.0 (6/18/2019)
### Public API Change
* Now DB::Close() will return Aborted() error when there is unreleased snapshot. Users can retry after all snapshots are released.
* Index blocks are now handled similarly to data blocks with regards to the block cache: instead of storing objects in the cache, only the blocks themselves are cached. In addition, index blocks no longer get evicted from the cache when a table is closed, can now use the compressed block cache (if any), and can be shared among multiple table readers.
* Partitions of partitioned indexes no longer affect the read amplification statistics.
* Due to the above refactoring, block cache eviction statistics for indexes are temporarily broken. We plan to reintroduce them in a later phase.
* options.keep_log_file_num will be enforced strictly all the time. File names of all log files will be tracked, which may take significantly amount of memory if options.keep_log_file_num is large and either of options.max_log_file_size or options.log_file_time_to_roll is set.
* Add initial support for Get/Put with user timestamps. Users can specify timestamps via ReadOptions and WriteOptions when calling DB::Get and DB::Put.
* Accessing a partition of a partitioned filter or index through a pinned reference is no longer considered a cache hit.
* Add C bindings for secondary instance, i.e. DBImplSecondary.
* Rate limited deletion of WALs is only enabled if DBOptions::wal_dir is not set, or explicitly set to db_name passed to DB::Open and DBOptions::db_paths is empty, or same as db_paths[0].path
### New Features
* Add an option `snap_refresh_nanos` (default to 0) to periodically refresh the snapshot list in compaction jobs. Assign to 0 to disable the feature.
* Add an option `unordered_write` which trades snapshot guarantees with higher write throughput. When used with WRITE_PREPARED transactions with two_write_queues=true, it offers higher throughput with however no compromise on guarantees.
* Allow DBImplSecondary to remove memtables with obsolete data after replaying MANIFEST and WAL.
* Add an option `failed_move_fall_back_to_copy` (default is true) for external SST ingestion. When `move_files` is true and hard link fails, ingestion falls back to copy if `failed_move_fall_back_to_copy` is true. Otherwise, ingestion reports an error.
### Performance Improvements
* Reduce binary search when iterator reseek into the same data block.
* DBIter::Next() can skip user key checking if previous entry's seqnum is 0.
* Merging iterator to avoid child iterator reseek for some cases
* Log Writer will flush after finishing the whole record, rather than a fragment.
* Lower MultiGet batching API latency by reading data blocks from disk in parallel
### General Improvements
* Added new status code kColumnFamilyDropped to distinguish between Column Family Dropped and DB Shutdown in progress.
* Improve ColumnFamilyOptions validation when creating a new column family.
### Bug Fixes
* Fix a bug in WAL replay of secondary instance by skipping write batches with older sequence numbers than the current last sequence number.
* Fix flush's/compaction's merge processing logic which allowed `Put`s covered by range tombstones to reappear. Note `Put`s may exist even if the user only ever called `Merge()` due to an internal conversion during compaction to the bottommost level.
* Fix/improve memtable earliest sequence assignment and WAL replay so that WAL entries of unflushed column families will not be skipped after replaying the MANIFEST and increasing db sequence due to another flushed/compacted column family.
* Fix a bug caused by secondary not skipping the beginning of new MANIFEST.
* On DB open, delete WAL trash files left behind in wal_dir
2019-10-07T17:29:09+00:00rocksdb v6.4.6rocksdb v6.4.62019-10-31T21:55:22+00:00# Rocksdb Change Log
## 6.4.6 (10/16/2019)
### Bug Fixes
* Fix a bug when partitioned filters and prefix search are used in conjunction, ::SeekForPrev could return invalid for an existing prefix. ::SeekForPrev might be called by the user, or internally on ::Prev, or within ::Seek if the return value involves Delete or a Merge operand.
## 6.4.5 (10/1/2019)
### Bug Fixes
* Revert the feature "Merging iterator to avoid child iterator reseek for some cases (#5286)" since it might cause strange results when reseek happens with a different iterator upper bound.
* Fix a bug in BlockBasedTableIterator that might return incorrect results when reseek happens with a different iterator upper bound.
## 6.4.4 (9/17/2019)
* Fix a bug introduced 6.3 which could cause wrong results in a corner case when prefix bloom filter is used and the iterator is reseeked.
## 6.4.2 (9/3/2019)
### Bug Fixes
* Fix a bug in file ingestion caused by incorrect file number allocation when the number of column families involved in the ingestion exceeds 2.
## 6.4.1 (8/20/2019)
### Bug Fixes
* Fix a bug where the compaction snapshot refresh feature is not disabled as advertised when `snap_refresh_nanos` is set to 0..
## 6.4.0 (7/30/2019)
### Default Option Change
* LRUCacheOptions.high_pri_pool_ratio is set to 0.5 (previously 0.0) by default, which means that by default midpoint insertion is enabled. The same change is made for the default value of high_pri_pool_ratio argument in NewLRUCache(). When block cache is not explictly created, the small block cache created by BlockBasedTable will still has this option to be 0.0.
* Change BlockBasedTableOptions.cache_index_and_filter_blocks_with_high_priority's default value from false to true.
### Public API Change
* Filter and compression dictionary blocks are now handled similarly to data blocks with regards to the block cache: instead of storing objects in the cache, only the blocks themselves are cached. In addition, filter and compression dictionary blocks (as well as filter partitions) no longer get evicted from the cache when a table is closed.
* Due to the above refactoring, block cache eviction statistics for filter and compression dictionary blocks are temporarily broken. We plan to reintroduce them in a later phase.
* The semantics of the per-block-type block read counts in the performance context now match those of the generic block_read_count.
* Errors related to the retrieval of the compression dictionary are now propagated to the user.
* db_bench adds a "benchmark" stats_history, which prints out the whole stats history.
* Overload GetAllKeyVersions() to support non-default column family.
* Added new APIs ExportColumnFamily() and CreateColumnFamilyWithImport() to support export and import of a Column Family. https://github.com/facebook/rocksdb/issues/3469
* ldb sometimes uses a string-append merge operator if no merge operator is passed in. This is to allow users to print keys from a DB with a merge operator.
* Replaces old Registra with ObjectRegistry to allow user to create custom object from string, also add LoadEnv() to Env.
* Added new overload of GetApproximateSizes which gets SizeApproximationOptions object and returns a Status. The older overloads are redirecting their calls to this new method and no longer assert if the include_flags doesn't have either of INCLUDE_MEMTABLES or INCLUDE_FILES bits set. It's recommended to use the new method only, as it is more type safe and returns a meaningful status in case of errors.
### New Features
* Add argument `--secondary_path` to ldb to open the database as the secondary instance. This would keep the original DB intact.
* Compression dictionary blocks are now prefetched and pinned in the cache (based on the customer's settings) the same way as index and filter blocks.
* Added DBOptions::log_readahead_size which specifies the number of bytes to prefetch when reading the log. This is mostly useful for reading a remotely located log, as it can save the number of round-trips. If 0 (default), then the prefetching is disabled.
* Support loading custom objects in unit tests. In the affected unit tests, RocksDB will create custom Env objects based on environment variable TEST_ENV_URI. Users need to make sure custom object types are properly registered. For example, a static library should expose a `RegisterCustomObjects` function. By linking the unit test binary with the static library, the unit test can execute this function.
### Performance Improvements
* Reduce iterator key comparision for upper/lower bound check.
* Improve performance of row_cache: make reads with newer snapshots than data in an SST file share the same cache key, except in some transaction cases.
* The compression dictionary is no longer copied to a new object upon retrieval.
### Bug Fixes
* Fix ingested file and directory not being fsync.
* Return TryAgain status in place of Corruption when new tail is not visible to TransactionLogIterator.
* Fixed a regression where the fill_cache read option also affected index blocks.
* Fixed an issue where using cache_index_and_filter_blocks==false affected partitions of partitioned indexes/filters as well.
2019-10-31T21:55:22+00:00rocksdb v6.5.2rocksdb v6.5.22019-12-12T22:08:53+00:00## 6.5.2 (11/15/2019)
### Bug Fixes
* Fix a assertion failure in MultiGe4t() when BlockBasedTableOptions::no_block_cache is true and there is no compressed block cache
* Fix a buffer overrun problem in BlockBasedTable::MultiGet() when compression is enabled and no compressed block cache is configured.
* If a call to BackupEngine::PurgeOldBackups or BackupEngine::DeleteBackup suffered a crash, power failure, or I/O error, files could be left over from old backups that could only be purged with a call to GarbageCollect. Any call to PurgeOldBackups, DeleteBackup, or GarbageCollect should now suffice to purge such files.
## 6.5.1 (10/16/2019)
### Bug Fixes
* Revert the feature "Merging iterator to avoid child iterator reseek for some cases (#5286)" since it might cause strange results when reseek happens with a different iterator upper bound.
* Fix a bug in BlockBasedTableIterator that might return incorrect results when reseek happens with a different iterator upper bound.
* Fix a bug when partitioned filters and prefix search are used in conjunction, ::SeekForPrev could return invalid for an existing prefix. ::SeekForPrev might be called by the user, or internally on ::Prev, or within ::Seek if the return value involves Delete or a Merge operand.
## 6.5.0 (9/13/2019)
### Bug Fixes
* Fixed a number of data races in BlobDB.
* Fix a bug where the compaction snapshot refresh feature is not disabled as advertised when `snap_refresh_nanos` is set to 0..
* Fix bloom filter lookups by the MultiGet batching API when BlockBasedTableOptions::whole_key_filtering is false, by checking that a key is in the perfix_extractor domain and extracting the prefix before looking up.
* Fix a bug in file ingestion caused by incorrect file number allocation when the number of column families involved in the ingestion exceeds 2.
### New Features
* Introduced DBOptions::max_write_batch_group_size_bytes to configure maximum limit on number of bytes that are written in a single batch of WAL or memtable write. It is followed when the leader write size is larger than 1/8 of this limit.
* VerifyChecksum() by default will issue readahead. Allow ReadOptions to be passed in to those functions to override the readhead size. For checksum verifying before external SST file ingestion, a new option IngestExternalFileOptions.verify_checksums_readahead_size, is added for this readahead setting.
* When user uses options.force_consistency_check in RocksDb, instead of crashing the process, we now pass the error back to the users without killing the process.
* Add an option `memtable_insert_hint_per_batch` to WriteOptions. If it is true, each WriteBatch will maintain its own insert hints for each memtable in concurrent write. See include/rocksdb/options.h for more details.
### Public API Change
* Added max_write_buffer_size_to_maintain option to better control memory usage of immutable memtables.
* Added a lightweight API GetCurrentWalFile() to get last live WAL filename and size. Meant to be used as a helper for backup/restore tooling in a larger ecosystem such as MySQL with a MyRocks storage engine.
* The MemTable Bloom filter, when enabled, now always uses cache locality. Options::bloom_locality now only affects the PlainTable SST format.
### Performance Improvements
* Improve the speed of the MemTable Bloom filter, reducing the write overhead of enabling it by 1/3 to 1/2, with similar benefit to read performance.
2019-12-12T22:08:53+00:00rocksdb v6.5.3rocksdb v6.5.32020-01-10T18:30:59+00:00# Rocksdb Change Log
## 6.5.3 (1/10/2020)
### Bug Fixes
* Fixed two performance issues related to memtable history trimming. First, a new SuperVersion is now created only if some memtables were actually trimmed. Second, trimming is only scheduled if there is at least one flushed memtable that is kept in memory for the purposes of transaction conflict checking.
2020-01-10T18:30:59+00:00rocksdb v6.6.3rocksdb v6.6.32020-01-28T22:07:40+00:00# Rocksdb Change Log
## 6.6.3 (01/24/2020)
### Bug Fixes
* Fix a bug that can cause write threads to hang when a slowdown/stall happens and there is a mix of writers with WriteOptions::no_slowdown set/unset.
## 6.6.2 (01/13/2020)
### Bug Fixes
* Fixed a bug where non-L0 compaction input files were not considered to compute the `creation_time` of new compaction outputs.
## 6.6.1 (01/02/2020)
### Bug Fixes
* Fix a bug in WriteBatchWithIndex::MultiGetFromBatchAndDB, which is called by Transaction::MultiGet, that causes due to stale pointer access when the number of keys is > 32
* Fixed two performance issues related to memtable history trimming. First, a new SuperVersion is now created only if some memtables were actually trimmed. Second, trimming is only scheduled if there is at least one flushed memtable that is kept in memory for the purposes of transaction conflict checking.
* BlobDB no longer updates the SST to blob file mapping upon failed compactions.
* Fix a bug in which a snapshot read through an iterator could be affected by a DeleteRange after the snapshot (#6062).
* Fixed a bug where BlobDB was comparing the `ColumnFamilyHandle` pointers themselves instead of only the column family IDs when checking whether an API call uses the default column family or not.
* Delete superversions in BackgroundCallPurge.
* Fix use-after-free and double-deleting files in BackgroundCallPurge().
## 6.6.0 (11/25/2019)
### Bug Fixes
* Fix data corruption casued by output of intra-L0 compaction on ingested file not being placed in correct order in L0.
* Fix a data race between Version::GetColumnFamilyMetaData() and Compaction::MarkFilesBeingCompacted() for access to being_compacted (#6056). The current fix acquires the db mutex during Version::GetColumnFamilyMetaData(), which may cause regression.
* Fix a bug in DBIter that is_blob_ state isn't updated when iterating backward using seek.
* Fix a bug when format_version=3, partitioned fitlers, and prefix search are used in conjunction. The bug could result into Seek::(prefix) returning NotFound for an existing prefix.
* Revert the feature "Merging iterator to avoid child iterator reseek for some cases (#5286)" since it might cause strong results when reseek happens with a different iterator upper bound.
* Fix a bug causing a crash during ingest external file when background compaction cause severe error (file not found).
* Fix a bug when partitioned filters and prefix search are used in conjunction, ::SeekForPrev could return invalid for an existing prefix. ::SeekForPrev might be called by the user, or internally on ::Prev, or within ::Seek if the return value involves Delete or a Merge operand.
* Fix OnFlushCompleted fired before flush result persisted in MANIFEST when there's concurrent flush job. The bug exists since OnFlushCompleted was introduced in rocksdb 3.8.
* Fixed an sst_dump crash on some plain table SST files.
* Fixed a memory leak in some error cases of opening plain table SST files.
* Fix a bug when a crash happens while calling WriteLevel0TableForRecovery for multiple column families, leading to a column family's log number greater than the first corrutped log number when the DB is being opened in PointInTime recovery mode during next recovery attempt (#5856).
### New Features
* Universal compaction to support options.periodic_compaction_seconds. A full compaction will be triggered if any file is over the threshold.
* `GetLiveFilesMetaData` and `GetColumnFamilyMetaData` now expose the file number of SST files as well as the oldest blob file referenced by each SST.
* A batched MultiGet API (DB::MultiGet()) that supports retrieving keys from multiple column families.
* Full and partitioned filters in the block-based table use an improved Bloom filter implementation, enabled with format_version 5 (or above) because previous releases cannot read this filter. This replacement is faster and more accurate, especially for high bits per key or millions of keys in a single (full) filter. For example, the new Bloom filter has the same false postive rate at 9.55 bits per key as the old one at 10 bits per key, and a lower false positive rate at 16 bits per key than the old one at 100 bits per key.
* Added AVX2 instructions to USE_SSE builds to accelerate the new Bloom filter and XXH3-based hash function on compatible x86_64 platforms (Haswell and later, ~2014).
* Support options.ttl or options.periodic_compaction_seconds with options.max_open_files = -1. File's oldest ancester time and file creation time will be written to manifest. If it is availalbe, this information will be used instead of creation_time and file_creation_time in table properties.
* Setting options.ttl for universal compaction now has the same meaning as setting periodic_compaction_seconds.
* SstFileMetaData also returns file creation time and oldest ancester time.
* The `sst_dump` command line tool `recompress` command now displays how many blocks were compressed and how many were not, in particular how many were not compressed because the compression ratio was not met (12.5% threshold for GoodCompressionRatio), as seen in the `number.block.not_compressed` counter stat since version 6.0.0.
* The block cache usage is now takes into account the overhead of metadata per each entry. This results into more accurate managment of memory. A side-effect of this feature is that less items are fit into the block cache of the same size, which would result to higher cache miss rates. This can be remedied by increasing the block cache size or passing kDontChargeCacheMetadata to its constuctor to restore the old behavior.
* When using BlobDB, a mapping is maintained and persisted in the MANIFEST between each SST file and the oldest non-TTL blob file it references.
* `db_bench` now supports and by default issues non-TTL Puts to BlobDB. TTL Puts can be enabled by specifying a non-zero value for the `blob_db_max_ttl_range` command line parameter explicitly.
* `sst_dump` now supports printing BlobDB blob indexes in a human-readable format. This can be enabled by specifying the `decode_blob_index` flag on the command line.
* A number of new information elements are now exposed through the EventListener interface. For flushes, the file numbers of the new SST file and the oldest blob file referenced by the SST are propagated. For compactions, the level, file number, and the oldest blob file referenced are passed to the client for each compaction input and output file.
### Public API Change
* RocksDB release 4.1 or older will not be able to open DB generated by the new release. 4.2 was released on Feb 23, 2016.
* TTL Compactions in Level compaction style now initiate successive cascading compactions on a key range so that it reaches the bottom level quickly on TTL expiry. `creation_time` table property for compaction output files is now set to the minimum of the creation times of all compaction inputs.
* With FIFO compaction style, options.periodic_compaction_seconds will have the same meaning as options.ttl. Whichever stricter will be used. With the default options.periodic_compaction_seconds value with options.ttl's default of 0, RocksDB will give a default of 30 days.
* Added an API GetCreationTimeOfOldestFile(uint64_t* creation_time) to get the file_creation_time of the oldest SST file in the DB.
* FilterPolicy now exposes additional API to make it possible to choose filter configurations based on context, such as table level and compaction style. See `LevelAndStyleCustomFilterPolicy` in db_bloom_filter_test.cc. While most existing custom implementations of FilterPolicy should continue to work as before, those wrapping the return of NewBloomFilterPolicy will require overriding new function `GetBuilderWithContext()`, because calling `GetFilterBitsBuilder()` on the FilterPolicy returned by NewBloomFilterPolicy is no longer supported.
* An unlikely usage of FilterPolicy is no longer supported. Calling GetFilterBitsBuilder() on the FilterPolicy returned by NewBloomFilterPolicy will now cause an assertion violation in debug builds, because RocksDB has internally migrated to a more elaborate interface that is expected to evolve further. Custom implementations of FilterPolicy should work as before, except those wrapping the return of NewBloomFilterPolicy, which will require a new override of a protected function in FilterPolicy.
* NewBloomFilterPolicy now takes bits_per_key as a double instead of an int. This permits finer control over the memory vs. accuracy trade-off in the new Bloom filter implementation and should not change source code compatibility.
* The option BackupableDBOptions::max_valid_backups_to_open is now only used when opening BackupEngineReadOnly. When opening a read/write BackupEngine, anything but the default value logs a warning and is treated as the default. This change ensures that backup deletion has proper accounting of shared files to ensure they are deleted when no longer referenced by a backup.
* Deprecate `snap_refresh_nanos` option.
* Added DisableManualCompaction/EnableManualCompaction to stop and resume manual compaction.
* Add TryCatchUpWithPrimary() to StackableDB in non-LITE mode.
* Add a new Env::LoadEnv() overloaded function to return a shared_ptr to Env.
* Flush sets file name to "(nil)" for OnTableFileCreationCompleted() if the flush does not produce any L0. This can happen if the file is empty thus delete by RocksDB.
### Default Option Changes
* Changed the default value of periodic_compaction_seconds to `UINT64_MAX - 1` which allows RocksDB to auto-tune periodic compaction scheduling. When using the default value, periodic compactions are now auto-enabled if a compaction filter is used. A value of `0` will turn off the feature completely.
* Changed the default value of ttl to `UINT64_MAX - 1` which allows RocksDB to auto-tune ttl value. When using the default value, TTL will be auto-enabled to 30 days, when the feature is supported. To revert the old behavior, you can explictly set it to 0.
### Performance Improvements
* For 64-bit hashing, RocksDB is standardizing on a slightly modified preview version of XXH3. This function is now used for many non-persisted hashes, along with fastrange64() in place of the modulus operator, and some benchmarks show a slight improvement.
* Level iterator to invlidate the iterator more often in prefix seek and the level is filtered out by prefix bloom.
2020-01-28T22:07:40+00:00rocksdb v6.6.4rocksdb v6.6.42020-01-31T21:05:10+00:00# Rocksdb Change Log
## 6.6.4 (1/31/2020)
### Bug Fixes
* Fixed issue #6316 that can cause a corruption of the MANIFEST file in the middle when writing to it fails due to no disk space.
2020-01-31T21:05:10+00:00rocksdb v5.18.4rocksdb v5.18.42020-02-11T22:09:41+00:00Special release for ARM. (Note: the originally tagged commit for this release was wrong but the tag has been updated a couple of times. You might need to delete your copy of the tag with `git tag -d v5.18.4` to get the new one. See https://git-scm.com/docs/git-tag#_on_re_tagging)2020-02-11T22:09:41+00:00rocksdb v6.7.3rocksdb v6.7.32020-03-19T01:53:59+00:00## 6.7.3 (2020-03-18)
### Bug Fixes
* Fix a data race that might cause crash when calling DB::GetCreationTimeOfOldestFile() by a small chance. The bug was introduced in 6.6 Release.
## 6.7.2 (2020-02-24)
### Bug Fixes
* Fixed a bug of IO Uring partial result handling introduced in 6.7.0.
## 6.7.1 (2020-02-13)
### Bug Fixes
* Fixed issue #6316 that can cause a corruption of the MANIFEST file in the middle when writing to it fails due to no disk space.
* Batched MultiGet() ignores IO errors while reading data blocks, causing it to potentially continue looking for a key and returning stale results.
## 6.7.0 (2020-01-21)
### Public API Change
* Added a rocksdb::FileSystem class in include/rocksdb/file_system.h to encapsulate file creation/read/write operations, and an option DBOptions::file_system to allow a user to pass in an instance of rocksdb::FileSystem. If its a non-null value, this will take precendence over DBOptions::env for file operations. A new API rocksdb::FileSystem::Default() returns a platform default object. The DBOptions::env option and Env::Default() API will continue to be used for threading and other OS related functions, and where DBOptions::file_system is not specified, for file operations. For storage developers who are accustomed to rocksdb::Env, the interface in rocksdb::FileSystem is new and will probably undergo some changes as more storage systems are ported to it from rocksdb::Env. As of now, no env other than Posix has been ported to the new interface.
* A new rocksdb::NewSstFileManager() API that allows the caller to pass in separate Env and FileSystem objects.
* Changed Java API for RocksDB.keyMayExist functions to use Holder<byte[]> instead of StringBuilder, so that retrieved values need not decode to Strings.
* A new `OptimisticTransactionDBOptions` Option that allows users to configure occ validation policy. The default policy changes from kValidateSerial to kValidateParallel to reduce mutex contention.
### Bug Fixes
* Fix a bug that can cause unnecessary bg thread to be scheduled(#6104).
* Fix crash caused by concurrent CF iterations and drops(#6147).
* Fix a race condition for cfd->log_number_ between manifest switch and memtable switch (PR 6249) when number of column families is greater than 1.
* Fix a bug on fractional cascading index when multiple files at the same level contain the same smallest user key, and those user keys are for merge operands. In this case, Get() the exact key may miss some merge operands.
* Delcare kHashSearch index type feature-incompatible with index_block_restart_interval larger than 1.
* Fixed an issue where the thread pools were not resized upon setting `max_background_jobs` dynamically through the `SetDBOptions` interface.
* Fix a bug that can cause write threads to hang when a slowdown/stall happens and there is a mix of writers with WriteOptions::no_slowdown set/unset.
* Fixed an issue where an incorrect "number of input records" value was used to compute the "records dropped" statistics for compactions.
### New Features
* It is now possible to enable periodic compactions for the base DB when using BlobDB.
* BlobDB now garbage collects non-TTL blobs when `enable_garbage_collection` is set to `true` in `BlobDBOptions`. Garbage collection is performed during compaction: any valid blobs located in the oldest N files (where N is the number of non-TTL blob files multiplied by the value of `BlobDBOptions::garbage_collection_cutoff`) encountered during compaction get relocated to new blob files, and old blob files are dropped once they are no longer needed. Note: we recommend enabling periodic compactions for the base DB when using this feature to deal with the case when some old blob files are kept alive by SSTs that otherwise do not get picked for compaction.
* `db_bench` now supports the `garbage_collection_cutoff` option for BlobDB.
* MultiGet() can use IO Uring to parallelize read from the same SST file. This featuer is by default disabled. It can be enabled with environment variable ROCKSDB_USE_IO_URING.
2020-03-19T01:53:59+00:00rocksdb v6.8.1rocksdb v6.8.12020-04-25T01:00:39+00:00## 6.8.1 (2020-03-30)
### Behavior changes
* Since RocksDB 6.8.0, ttl-based FIFO compaction can drop a file whose oldest key becomes older than options.ttl while others have not. This fix reverts this and makes ttl-based FIFO compaction use the file's flush time as the criterion. This fix also requires that max_open_files = -1 and compaction_options_fifo.allow_compaction = false to function properly.
## 6.8.0 (2020-02-24)
### Java API Changes
* Major breaking changes to Java comparators, toward standardizing on ByteBuffer for performant, locale-neutral operations on keys (#6252).
* Added overloads of common API methods using direct ByteBuffers for keys and values (#2283).
### Bug Fixes
* Fix incorrect results while block-based table uses kHashSearch, together with Prev()/SeekForPrev().
* Fix a bug that prevents opening a DB after two consecutive crash with TransactionDB, where the first crash recovers from a corrupted WAL with kPointInTimeRecovery but the second cannot.
* Fixed issue #6316 that can cause a corruption of the MANIFEST file in the middle when writing to it fails due to no disk space.
* Add DBOptions::skip_checking_sst_file_sizes_on_db_open. It disables potentially expensive checking of all sst file sizes in DB::Open().
* BlobDB now ignores trivially moved files when updating the mapping between blob files and SSTs. This should mitigate issue #6338 where out of order flush/compaction notifications could trigger an assertion with the earlier code.
* Batched MultiGet() ignores IO errors while reading data blocks, causing it to potentially continue looking for a key and returning stale results.
* `WriteBatchWithIndex::DeleteRange` returns `Status::NotSupported`. Previously it returned success even though reads on the batch did not account for range tombstones. The corresponding language bindings now cannot be used. In C, that includes `rocksdb_writebatch_wi_delete_range`, `rocksdb_writebatch_wi_delete_range_cf`, `rocksdb_writebatch_wi_delete_rangev`, and `rocksdb_writebatch_wi_delete_rangev_cf`. In Java, that includes `WriteBatchWithIndex::deleteRange`.
* Assign new MANIFEST file number when caller tries to create a new MANIFEST by calling LogAndApply(..., new_descriptor_log=true). This bug can cause MANIFEST being overwritten during recovery if options.write_dbid_to_manifest = true and there are WAL file(s).
### Performance Improvements
* Perfom readahead when reading from option files. Inside DB, options.log_readahead_size will be used as the readahead size. In other cases, a default 512KB is used.
### Public API Change
* The BlobDB garbage collector now emits the statistics `BLOB_DB_GC_NUM_FILES` (number of blob files obsoleted during GC), `BLOB_DB_GC_NUM_NEW_FILES` (number of new blob files generated during GC), `BLOB_DB_GC_FAILURES` (number of failed GC passes), `BLOB_DB_GC_NUM_KEYS_RELOCATED` (number of blobs relocated during GC), and `BLOB_DB_GC_BYTES_RELOCATED` (total size of blobs relocated during GC). On the other hand, the following statistics, which are not relevant for the new GC implementation, are now deprecated: `BLOB_DB_GC_NUM_KEYS_OVERWRITTEN`, `BLOB_DB_GC_NUM_KEYS_EXPIRED`, `BLOB_DB_GC_BYTES_OVERWRITTEN`, `BLOB_DB_GC_BYTES_EXPIRED`, and `BLOB_DB_GC_MICROS`.
* Disable recycle_log_file_num when an inconsistent recovery modes are requested: kPointInTimeRecovery and kAbsoluteConsistency
### New Features
* Added the checksum for each SST file generated by Flush or Compaction. Added sst_file_checksum_func to Options such that user can plugin their own SST file checksum function via override the FileChecksumFunc class. If user does not set the sst_file_checksum_func, SST file checksum calculation will not be enabled. The checksum information inlcuding uint32_t checksum value and a checksum function name (string). The checksum information is stored in FileMetadata in version store and also logged to MANIFEST. A new tool is added to LDB such that user can dump out a list of file checksum information from MANIFEST (stored in an unordered_map).
* `db_bench` now supports `value_size_distribution_type`, `value_size_min`, `value_size_max` options for generating random variable sized value. Added `blob_db_compression_type` option for BlobDB to enable blob compression.
* Replace RocksDB namespace "rocksdb" with flag "ROCKSDB_NAMESPACE" which if is not defined, defined as "rocksdb" in header file rocksdb_namespace.h.2020-04-25T01:00:39+00:00rocksdb v6.10.1rocksdb v6.10.12020-05-28T00:30:35+00:00# 6.10.1 (5/27/2020)
## Bug fix
* Remove "u''" in TARGETS file.
* Fix db_stress_lib target in buck.
# 6.10 (5/2/2020)
## Behavior Changes
* Disable delete triggered compaction (NewCompactOnDeletionCollectorFactory) in universal compaction mode and num_levels = 1 in order to avoid a corruption bug.
## Bug Fixes
* Fix wrong result being read from ingested file. May happen when a key in the file happen to be prefix of another key also in the file. The issue can further cause more data corruption. The issue exists with rocksdb >= 5.0.0 since DB::IngestExternalFile() was introduced.
* Finish implementation of BlockBasedTableOptions::IndexType::kBinarySearchWithFirstKey. It's now ready for use. Significantly reduces read amplification in some setups, especially for iterator seeks.
* Fix a bug by updating CURRENT file so that it points to the correct MANIFEST file after best-efforts recovery.
* Fixed a bug where ColumnFamilyHandle objects were not cleaned up in case an error happened during BlobDB's open after the base DB had been opened.
* Fix a potential undefined behavior caused by trying to dereference nullable pointer (timestamp argument) in DB::MultiGet.
* Fix a bug caused by not including user timestamp in MultiGet LookupKey construction. This can lead to wrong query result since the trailing bytes of a user key, if not shorter than timestamp, will be mistaken for user timestamp.
* Fix a bug caused by using wrong compare function when sorting the input keys of MultiGet with timestamps.
Upgraded version of bzip library (1.0.6 -> 1.0.8) used with RocksJava to address potential vulnerabilities if an attacker can manipulate compressed data saved and loaded by RocksDB (not normal). See issue #6703.
* Fix consistency checking error swallowing in some cases when options.force_consistency_checks = true.
* Fix possible false NotFound status from batched MultiGet using index type kHashSearch.
* Fix corruption caused by enabling delete triggered compaction (NewCompactOnDeletionCollectorFactory) in universal compaction mode, along with parallel compactions. The bug can result in two parallel compactions picking the same input files, resulting in the DB resurrecting older and deleted versions of some keys.
* Fix a use-after-free bug in best-efforts recovery. column_family_memtables_ needs to point to valid ColumnFamilySet.
* Let best-efforts recovery ignore corrupted files during table loading.
* Fix a bug when making options.bottommost_compression, options.compression_opts and options.bottommost_compression_opts dynamically changeable: the modified values are not written to option files or returned back to users when being queried.
* Fix a bug where index key comparisons were unaccounted in PerfContext::user_key_comparison_count for lookups in files written with format_version >= 3.
* Fix many bloom.filter statistics not being updated in batch MultiGet.
## Public API Change
* Add a ConfigOptions argument to the APIs dealing with converting options to and from strings and files. The ConfigOptions is meant to replace some of the options (such as input_strings_escaped and ignore_unknown_options) and allow for more parameters to be passed in the future without changing the function signature.
* Add NewFileChecksumGenCrc32cFactory to the file checksum public API, such that the builtin Crc32c based file checksum generator factory can be used by applications.
* Add IsDirectory to Env and FS to indicate if a path is a directory.
ldb now uses options.force_consistency_checks = true by default and "--disable_consistency_checks" is added to disable it.
* Add ReadOptions::deadline to allow users to specify a deadline for MultiGet requests
## New Features
* Added support for pipelined & parallel compression optimization for BlockBasedTableBuilder. This optimization makes block building, block compression and block appending a pipeline, and uses multiple threads to accelerate block compression. Users can set CompressionOptions::parallel_threads greater than 1 to enable compression parallelism. This feature is experimental for now.
* Provide an allocator for memkind to be used with block cache. This is to work with memory technologies (Intel DCPMM is one such technology currently available) that require different libraries for allocation and management (such as PMDK and memkind). The high capacities available make it possible to provision large caches (up to several TBs in size) beyond what is achievable with DRAM.
* Option max_background_flushes can be set dynamically using DB::SetDBOptions().
* Added functionality in sst_dump tool to check the compressed file size for different compression levels and print the time spent on compressing files with each compression type. Added arguments --compression_level_from and --compression_level_to to report size of all compression levels and one compression_type must be specified with it so that it will report compressed sizes of one compression type with different levels.
* Added statistics for redundant insertions into block cache: rocksdb.block.cache.*add.redundant. (There is currently no coordination to ensure that only one thread loads a table block when many threads are trying to access that same table block.)
## Performance Improvements
* Improve performance of batch MultiGet with partitioned filters, by sharing block cache lookups to applicable filter blocks.
* Reduced memory copies when fetching and uncompressing compressed blocks from sst files.
2020-05-28T00:30:35+00:00rocksdb v6.10.2rocksdb v6.10.22020-06-11T17:30:48+00:00# 6.10.2 (6/5/2020)
## Bug fix
* Fix false negative from the VerifyChecksum() API when there is a checksum mismatch in an index partition block in a BlockBasedTable format table file (index_type is kTwoLevelIndexSearch).2020-06-11T17:30:48+00:00rocksdb v6.11.4rocksdb v6.11.42020-07-20T05:37:52+00:00## 6.11.4 (7/15/2020)
### Bug Fixes
* Make compaction report InternalKey corruption while iterating over the input.
## 6.11.3 (7/9/2020)
### Bug Fixes
* Fix a bug when index_type == kTwoLevelIndexSearch in PartitionedIndexBuilder to update FlushPolicy to point to internal key partitioner when it changes from user-key mode to internal-key mode in index partition.
* Disable file deletion after MANIFEST write/sync failure until db re-open or Resume() so that subsequent re-open will not see MANIFEST referencing deleted SSTs.
## 6.11.1 (6/23/2020)
### Bug Fixes
* Best-efforts recovery ignores CURRENT file completely. If CURRENT file is missing during recovery, best-efforts recovery still proceeds with MANIFEST file(s).
* In best-efforts recovery, an error that is not Corruption or IOError::kNotFound or IOError::kPathNotFound will be overwritten silently. Fix this by checking all non-ok cases and return early.
* Compressed block cache was automatically disabled with read-only DBs by mistake. Now it is fixed: compressed block cache will be in effective with read-only DB too.
* Fail recovery and report once hitting a physical log record checksum mismatch, while reading MANIFEST. RocksDB should not continue processing the MANIFEST any further.
* Fix a bug of wrong iterator result if another thread finishes an update and a DB flush between two statement.
### Public API Change
* `DB::OpenForReadOnly()` now returns `Status::NotFound` when the specified DB directory does not exist. Previously the error returned depended on the underlying `Env`.
## 6.11 (6/12/2020)
### Bug Fixes
* Fix consistency checking error swallowing in some cases when options.force_consistency_checks = true.
* Fix possible false NotFound status from batched MultiGet using index type kHashSearch.
* Fix corruption caused by enabling delete triggered compaction (NewCompactOnDeletionCollectorFactory) in universal compaction mode, along with parallel compactions. The bug can result in two parallel compactions picking the same input files, resulting in the DB resurrecting older and deleted versions of some keys.
* Fix a use-after-free bug in best-efforts recovery. column_family_memtables_ needs to point to valid ColumnFamilySet.
* Let best-efforts recovery ignore corrupted files during table loading.
* Fix corrupt key read from ingested file when iterator direction switches from reverse to forward at a key that is a prefix of another key in the same file. It is only possible in files with a non-zero global seqno.
* Fix abnormally large estimate from GetApproximateSizes when a range starts near the end of one SST file and near the beginning of another. Now GetApproximateSizes consistently and fairly includes the size of SST metadata in addition to data blocks, attributing metadata proportionally among the data blocks based on their size.
* Fix potential file descriptor leakage in PosixEnv's IsDirectory() and NewRandomAccessFile().
* Fix false negative from the VerifyChecksum() API when there is a checksum mismatch in an index partition block in a BlockBasedTable format table file (index_type is kTwoLevelIndexSearch).
* Fix sst_dump to return non-zero exit code if the specified file is not a recognized SST file or fails requested checks.
* Fix incorrect results from batched MultiGet for duplicate keys, when the duplicate key matches the largest key of an SST file and the value type for the key in the file is a merge value.
### Public API Change
* Flush(..., column_family) may return Status::ColumnFamilyDropped() instead of Status::InvalidArgument() if column_family is dropped while processing the flush request.
* BlobDB now explicitly disallows using the default column family's storage directories as blob directory.
* DeleteRange now returns `Status::InvalidArgument` if the range's end key comes before its start key according to the user comparator. Previously the behavior was undefined.
* ldb now uses options.force_consistency_checks = true by default and "--disable_consistency_checks" is added to disable it.
* DB::OpenForReadOnly no longer creates files or directories if the named DB does not exist, unless create_if_missing is set to true.
* The consistency checks that validate LSM state changes (table file additions/deletions during flushes and compactions) are now stricter, more efficient, and no longer optional, i.e. they are performed even if `force_consistency_checks` is `false`.
* Disable delete triggered compaction (NewCompactOnDeletionCollectorFactory) in universal compaction mode and num_levels = 1 in order to avoid a corruption bug.
* `pin_l0_filter_and_index_blocks_in_cache` no longer applies to L0 files larger than `1.5 * write_buffer_size` to give more predictable memory usage. Such L0 files may exist due to intra-L0 compaction, external file ingestion, or user dynamically changing `write_buffer_size` (note, however, that files that are already pinned will continue being pinned, even after such a dynamic change).
* In point-in-time wal recovery mode, fail database recovery in case of IOError while reading the WAL to avoid data loss.
### New Features
* sst_dump to add a new --readahead_size argument. Users can specify read size when scanning the data. Sst_dump also tries to prefetch tail part of the SST files so usually some number of I/Os are saved there too.
* Generate file checksum in SstFileWriter if Options.file_checksum_gen_factory is set. The checksum and checksum function name are stored in ExternalSstFileInfo after the sst file write is finished.
* Add a value_size_soft_limit in read options which limits the cumulative value size of keys read in batches in MultiGet. Once the cumulative value size of found keys exceeds read_options.value_size_soft_limit, all the remaining keys are returned with status Abort without further finding their values. By default the value_size_soft_limit is std::numeric_limits<uint64_t>::max().
* Enable SST file ingestion with file checksum information when calling IngestExternalFiles(const std::vector<IngestExternalFileArg>& args). Added files_checksums and files_checksum_func_names to IngestExternalFileArg such that user can ingest the sst files with their file checksum information. Added verify_file_checksum to IngestExternalFileOptions (default is True). To be backward compatible, if DB does not enable file checksum or user does not provide checksum information (vectors of files_checksums and files_checksum_func_names are both empty), verification of file checksum is always sucessful. If DB enables file checksum, DB will always generate the checksum for each ingested SST file during Prepare stage of ingestion and store the checksum in Manifest, unless verify_file_checksum is False and checksum information is provided by the application. In this case, we only verify the checksum function name and directly store the ingested checksum in Manifest. If verify_file_checksum is set to True, DB will verify the ingested checksum and function name with the genrated ones. Any mismatch will fail the ingestion. Note that, if IngestExternalFileOptions::write_global_seqno is True, the seqno will be changed in the ingested file. Therefore, the checksum of the file will be changed. In this case, a new checksum will be generated after the seqno is updated and be stored in the Manifest.
### Performance Improvements
* Eliminate redundant key comparisons during random access in block-based tables.2020-07-20T05:37:52+00:00rocksdb v6.11.6rocksdb v6.11.62020-10-12T20:35:53+00:00## 6.11.6 (10/12/2020)
### Bug Fixes
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
## 6.11.5 (7/23/2020)
### Bug Fixes
* Memtable lookup should report unrecognized value_type as corruption (#7121).2020-10-12T20:35:53+00:00rocksdb v6.12.6rocksdb v6.12.62020-10-13T16:38:10+00:00## 6.12.6 (2020-10-13)
### Bug Fixes
* Fix false positive flush/compaction `Status::Corruption` failure when `paranoid_file_checks == true` and range tombstones were written to the compaction output files.
## 6.12.5 (2020-10-12)
### Bug Fixes
* Since 6.12, memtable lookup should report unrecognized value_type as corruption (#7121).
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
## 6.12.4 (2020-09-18)
### Public API Change
* Reworked `BackupableDBOptions::share_files_with_checksum_naming` (new in 6.12) with some minor improvements and to better support those who were extracting files sizes from backup file names.
## 6.12.3 (2020-09-16)
### Bug fixes
* Fixed a bug in size-amp-triggered and periodic-triggered universal compaction, where the compression settings for the first input level were used rather than the compression settings for the output (bottom) level.
## 6.12.2 (2020-09-14)
### Public API Change
* BlobDB now exposes the start of the expiration range of TTL blob files via the `GetLiveFilesMetaData` API.
## 6.12.1 (2020-08-20)
### Bug fixes
* BackupEngine::CreateNewBackup could fail intermittently with non-OK status when backing up a read-write DB configured with a DBOptions::file_checksum_gen_factory. This issue has been worked-around such that CreateNewBackup should succeed, but (until fully fixed) BackupEngine might not see all checksums available in the DB.
## 6.12 (2020-07-28)
### Public API Change
* Encryption file classes now exposed for inheritance in env_encryption.h
* File I/O listener is extended to cover more I/O operations. Now class `EventListener` in listener.h contains new callback functions: `OnFileFlushFinish()`, `OnFileSyncFinish()`, `OnFileRangeSyncFinish()`, `OnFileTruncateFinish()`, and ``OnFileCloseFinish()``.
* `FileOperationInfo` now reports `duration` measured by `std::chrono::steady_clock` and `start_ts` measured by `std::chrono::system_clock` instead of start and finish timestamps measured by `system_clock`. Note that `system_clock` is called before `steady_clock` in program order at operation starts.
* `DB::GetDbSessionId(std::string& session_id)` is added. `session_id` stores a unique identifier that gets reset every time the DB is opened. This DB session ID should be unique among all open DB instances on all hosts, and should be unique among re-openings of the same or other DBs. This identifier is recorded in the LOG file on the line starting with "DB Session ID:".
* `DB::OpenForReadOnly()` now returns `Status::NotFound` when the specified DB directory does not exist. Previously the error returned depended on the underlying `Env`. This change is available in all 6.11 releases as well.
* A parameter `verify_with_checksum` is added to `BackupEngine::VerifyBackup`, which is false by default. If it is ture, `BackupEngine::VerifyBackup` verifies checksums and file sizes of backup files. Pass `false` for `verify_with_checksum` to maintain the previous behavior and performance of `BackupEngine::VerifyBackup`, by only verifying sizes of backup files.
### Behavior Changes
* Best-efforts recovery ignores CURRENT file completely. If CURRENT file is missing during recovery, best-efforts recovery still proceeds with MANIFEST file(s).
* In best-efforts recovery, an error that is not Corruption or IOError::kNotFound or IOError::kPathNotFound will be overwritten silently. Fix this by checking all non-ok cases and return early.
* When `file_checksum_gen_factory` is set to `GetFileChecksumGenCrc32cFactory()`, BackupEngine will compare the crc32c checksums of table files computed when creating a backup to the expected checksums stored in the DB manifest, and will fail `CreateNewBackup()` on mismatch (corruption). If the `file_checksum_gen_factory` is not set or set to any other customized factory, there is no checksum verification to detect if SST files in a DB are corrupt when read, copied, and independently checksummed by BackupEngine.
* When a DB sets `stats_dump_period_sec > 0`, either as the initial value for DB open or as a dynamic option change, the first stats dump is staggered in the following X seconds, where X is an integer in `[0, stats_dump_period_sec)`. Subsequent stats dumps are still spaced `stats_dump_period_sec` seconds apart.
* When the paranoid_file_checks option is true, a hash is generated of all keys and values are generated when the SST file is written, and then the values are read back in to validate the file. A corruption is signaled if the two hashes do not match.
### Bug fixes
* Compressed block cache was automatically disabled with read-only DBs by mistake. Now it is fixed: compressed block cache will be in effective with read-only DB too.
* Fix a bug of wrong iterator result if another thread finishes an update and a DB flush between two statement.
* Disable file deletion after MANIFEST write/sync failure until db re-open or Resume() so that subsequent re-open will not see MANIFEST referencing deleted SSTs.
* Fix a bug when index_type == kTwoLevelIndexSearch in PartitionedIndexBuilder to update FlushPolicy to point to internal key partitioner when it changes from user-key mode to internal-key mode in index partition.
* Make compaction report InternalKey corruption while iterating over the input.
* Fix a bug which may cause MultiGet to be slow because it may read more data than requested, but this won't affect correctness. The bug was introduced in 6.10 release.
* Fail recovery and report once hitting a physical log record checksum mismatch, while reading MANIFEST. RocksDB should not continue processing the MANIFEST any further.
### New Features
* DB identity (`db_id`) and DB session identity (`db_session_id`) are added to table properties and stored in SST files. SST files generated from SstFileWriter and Repairer have DB identity “SST Writer” and “DB Repairer”, respectively. Their DB session IDs are generated in the same way as `DB::GetDbSessionId`. The session ID for SstFileWriter (resp., Repairer) resets every time `SstFileWriter::Open` (resp., `Repairer::Run`) is called.
* Added experimental option BlockBasedTableOptions::optimize_filters_for_memory for reducing allocated memory size of Bloom filters (~10% savings with Jemalloc) while preserving the same general accuracy. To have an effect, the option requires format_version=5 and malloc_usable_size. Enabling this option is forward and backward compatible with existing format_version=5.
* `BackupableDBOptions::share_files_with_checksum_naming` is added with new default behavior for naming backup files with `share_files_with_checksum`, to address performance and backup integrity issues. See API comments for details.
* Added auto resume function to automatically recover the DB from background Retryable IO Error. When retryable IOError happens during flush and WAL write, the error is mapped to Hard Error and DB will be in read mode. When retryable IO Error happens during compaction, the error will be mapped to Soft Error. DB is still in write/read mode. Autoresume function will create a thread for a DB to call DB->ResumeImpl() to try the recover for Retryable IO Error during flush and WAL write. Compaction will be rescheduled by itself if retryable IO Error happens. Auto resume may also cause other Retryable IO Error during the recovery, so the recovery will fail. Retry the auto resume may solve the issue, so we use max_bgerror_resume_count to decide how many resume cycles will be tried in total. If it is <=0, auto resume retryable IO Error is disabled. Default is INT_MAX, which will lead to a infinit auto resume. bgerror_resume_retry_interval decides the time interval between two auto resumes.
* Option `max_subcompactions` can be set dynamically using DB::SetDBOptions().
* Added experimental ColumnFamilyOptions::sst_partitioner_factory to define determine the partitioning of sst files. This helps compaction to split the files on interesting boundaries (key prefixes) to make propagation of sst files less write amplifying (covering the whole key space).
### Performance Improvements
* Eliminate key copies for internal comparisons while accessing ingested block-based tables.
* Reduce key comparisons during random access in all block-based tables.
* BackupEngine avoids unnecessary repeated checksum computation for backing up a table file to the `shared_checksum` directory when using `share_files_with_checksum_naming = kUseDbSessionId` (new default), except on SST files generated before this version of RocksDB, which fall back on using `kLegacyCrc32cAndFileSize`.2020-10-13T16:38:10+00:00rocksdb v6.13.2rocksdb v6.13.22020-10-13T16:44:50+00:00## 6.13.2 (10/13/2020)
### Bug Fixes
* Fix false positive flush/compaction `Status::Corruption` failure when `paranoid_file_checks == true` and range tombstones were written to the compaction output files.
## 6.13.1 (10/12/2020)
### Bug Fixes
* Since 6.12, memtable lookup should report unrecognized value_type as corruption (#7121).
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
## 6.13 (09/24/2020)
### Bug fixes
* Fix a performance regression introduced in 6.4 that makes a upper bound check for every Next() even if keys are within a data block that is within the upper bound.
* Fix a possible corruption to the LSM state (overlapping files within a level) when a `CompactRange()` for refitting levels (`CompactRangeOptions::change_level == true`) and another manual compaction are executed in parallel.
* Sanitize `recycle_log_file_num` to zero when the user attempts to enable it in combination with `WALRecoveryMode::kTolerateCorruptedTailRecords`. Previously the two features were allowed together, which compromised the user's configured crash-recovery guarantees.
* Fix a bug where a level refitting in CompactRange() might race with an automatic compaction that puts the data to the target level of the refitting. The bug has been there for years.
* Fixed a bug in version 6.12 in which BackupEngine::CreateNewBackup could fail intermittently with non-OK status when backing up a read-write DB configured with a DBOptions::file_checksum_gen_factory.
* Fix useless no-op compactions scheduled upon snapshot release when options.disable-auto-compactions = true.
* Fix a bug when max_write_buffer_size_to_maintain is set, immutable flushed memtable destruction is delayed until the next super version is installed. A memtable is not added to delete list because of its reference hold by super version and super version doesn't switch because of empt delete list. So memory usage keeps on increasing beyond write_buffer_size + max_write_buffer_size_to_maintain.
* Avoid converting MERGES to PUTS when allow_ingest_behind is true.
* Fix compression dictionary sampling together with `SstFileWriter`. Previously, the dictionary would be trained/finalized immediately with zero samples. Now, the whole `SstFileWriter` file is buffered in memory and then sampled.
* Fix a bug with `avoid_unnecessary_blocking_io=1` and creating backups (BackupEngine::CreateNewBackup) or checkpoints (Checkpoint::Create). With this setting and WAL enabled, these operations could randomly fail with non-OK status.
* Fix a bug in which bottommost compaction continues to advance the underlying InternalIterator to skip tombstones even after shutdown.
### New Features
* A new field `std::string requested_checksum_func_name` is added to `FileChecksumGenContext`, which enables the checksum factory to create generators for a suite of different functions.
* Added a new subcommand, `ldb unsafe_remove_sst_file`, which removes a lost or corrupt SST file from a DB's metadata. This command involves data loss and must not be used on a live DB.
### Performance Improvements
* Reduce thread number for multiple DB instances by re-using one global thread for statistics dumping and persisting.
* Reduce write-amp in heavy write bursts in `kCompactionStyleLevel` compaction style with `level_compaction_dynamic_level_bytes` set.
* BackupEngine incremental backups no longer read DB table files that are already saved to a shared part of the backup directory, unless `share_files_with_checksum` is used with `kLegacyCrc32cAndFileSize` naming (discouraged).
* For `share_files_with_checksum`, we are confident there is no regression (vs. pre-6.12) in detecting DB or backup corruption at backup creation time, mostly because the old design did not leverage this extra checksum computation for detecting inconsistencies at backup creation time.
* For `share_table_files` without "checksum" (not recommended), there is a regression in detecting fundamentally unsafe use of the option, greatly mitigated by file size checking (under "Behavior Changes"). Almost no reason to use `share_files_with_checksum=false` should remain.
* `DB::VerifyChecksum` and `BackupEngine::VerifyBackup` with checksum checking are still able to catch corruptions that `CreateNewBackup` does not.
### Public API Change
* Expose kTypeDeleteWithTimestamp in EntryType and update GetEntryType() accordingly.
* Added file_checksum and file_checksum_func_name to TableFileCreationInfo, which can pass the table file checksum information through the OnTableFileCreated callback during flush and compaction.
* A warning is added to `DB::DeleteFile()` API describing its known problems and deprecation plan.
* Add a new stats level, i.e. StatsLevel::kExceptTickers (PR7329) to exclude tickers even if application passes a non-null Statistics object.
* Added a new status code IOStatus::IOFenced() for the Env/FileSystem to indicate that writes from this instance are fenced off. Like any other background error, this error is returned to the user in Put/Merge/Delete/Flush calls and can be checked using Status::IsIOFenced().
### Behavior Changes
* File abstraction `FSRandomAccessFile.Prefetch()` default return status is changed from `OK` to `NotSupported`. If the user inherited file doesn't implement prefetch, RocksDB will create internal prefetch buffer to improve read performance.
* When retryable IO error happens during Flush (manifest write error is excluded) and WAL is disabled, originally it is mapped to kHardError. Now,it is mapped to soft error. So DB will not stall the writes unless the memtable is full. At the same time, when auto resume is triggered to recover the retryable IO error during Flush, SwitchMemtable is not called to avoid generating to many small immutable memtables. If WAL is enabled, no behavior changes.
* When considering whether a table file is already backed up in a shared part of backup directory, BackupEngine would already query the sizes of source (DB) and pre-existing destination (backup) files. BackupEngine now uses these file sizes to detect corruption, as at least one of (a) old backup, (b) backup in progress, or (c) current DB is corrupt if there's a size mismatch.
### Others
* Error in prefetching partitioned index blocks will not be swallowed. It will fail the query and return the IOError users.2020-10-13T16:44:50+00:00rocksdb v6.13.3rocksdb v6.13.32020-10-13T16:44:50+00:00## 6.13.3 (10/14/2020)
### Bug Fixes
* Fix a bug that could cause a stalled write to crash with mixed of slowdown and no_slowdown writes (`WriteOptions.no_slowdown=true`).
## 6.13.2 (10/13/2020)
### Bug Fixes
* Fix false positive flush/compaction `Status::Corruption` failure when `paranoid_file_checks == true` and range tombstones were written to the compaction output files.
## 6.13.1 (10/12/2020)
### Bug Fixes
* Since 6.12, memtable lookup should report unrecognized value_type as corruption (#7121).
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
## 6.13 (09/24/2020)
### Bug fixes
* Fix a performance regression introduced in 6.4 that makes a upper bound check for every Next() even if keys are within a data block that is within the upper bound.
* Fix a possible corruption to the LSM state (overlapping files within a level) when a `CompactRange()` for refitting levels (`CompactRangeOptions::change_level == true`) and another manual compaction are executed in parallel.
* Sanitize `recycle_log_file_num` to zero when the user attempts to enable it in combination with `WALRecoveryMode::kTolerateCorruptedTailRecords`. Previously the two features were allowed together, which compromised the user's configured crash-recovery guarantees.
* Fix a bug where a level refitting in CompactRange() might race with an automatic compaction that puts the data to the target level of the refitting. The bug has been there for years.
* Fixed a bug in version 6.12 in which BackupEngine::CreateNewBackup could fail intermittently with non-OK status when backing up a read-write DB configured with a DBOptions::file_checksum_gen_factory.
* Fix useless no-op compactions scheduled upon snapshot release when options.disable-auto-compactions = true.
* Fix a bug when max_write_buffer_size_to_maintain is set, immutable flushed memtable destruction is delayed until the next super version is installed. A memtable is not added to delete list because of its reference hold by super version and super version doesn't switch because of empt delete list. So memory usage keeps on increasing beyond write_buffer_size + max_write_buffer_size_to_maintain.
* Avoid converting MERGES to PUTS when allow_ingest_behind is true.
* Fix compression dictionary sampling together with `SstFileWriter`. Previously, the dictionary would be trained/finalized immediately with zero samples. Now, the whole `SstFileWriter` file is buffered in memory and then sampled.
* Fix a bug with `avoid_unnecessary_blocking_io=1` and creating backups (BackupEngine::CreateNewBackup) or checkpoints (Checkpoint::Create). With this setting and WAL enabled, these operations could randomly fail with non-OK status.
* Fix a bug in which bottommost compaction continues to advance the underlying InternalIterator to skip tombstones even after shutdown.
### New Features
* A new field `std::string requested_checksum_func_name` is added to `FileChecksumGenContext`, which enables the checksum factory to create generators for a suite of different functions.
* Added a new subcommand, `ldb unsafe_remove_sst_file`, which removes a lost or corrupt SST file from a DB's metadata. This command involves data loss and must not be used on a live DB.
### Performance Improvements
* Reduce thread number for multiple DB instances by re-using one global thread for statistics dumping and persisting.
* Reduce write-amp in heavy write bursts in `kCompactionStyleLevel` compaction style with `level_compaction_dynamic_level_bytes` set.
* BackupEngine incremental backups no longer read DB table files that are already saved to a shared part of the backup directory, unless `share_files_with_checksum` is used with `kLegacyCrc32cAndFileSize` naming (discouraged).
* For `share_files_with_checksum`, we are confident there is no regression (vs. pre-6.12) in detecting DB or backup corruption at backup creation time, mostly because the old design did not leverage this extra checksum computation for detecting inconsistencies at backup creation time.
* For `share_table_files` without "checksum" (not recommended), there is a regression in detecting fundamentally unsafe use of the option, greatly mitigated by file size checking (under "Behavior Changes"). Almost no reason to use `share_files_with_checksum=false` should remain.
* `DB::VerifyChecksum` and `BackupEngine::VerifyBackup` with checksum checking are still able to catch corruptions that `CreateNewBackup` does not.
### Public API Change
* Expose kTypeDeleteWithTimestamp in EntryType and update GetEntryType() accordingly.
* Added file_checksum and file_checksum_func_name to TableFileCreationInfo, which can pass the table file checksum information through the OnTableFileCreated callback during flush and compaction.
* A warning is added to `DB::DeleteFile()` API describing its known problems and deprecation plan.
* Add a new stats level, i.e. StatsLevel::kExceptTickers (PR7329) to exclude tickers even if application passes a non-null Statistics object.
* Added a new status code IOStatus::IOFenced() for the Env/FileSystem to indicate that writes from this instance are fenced off. Like any other background error, this error is returned to the user in Put/Merge/Delete/Flush calls and can be checked using Status::IsIOFenced().
### Behavior Changes
* File abstraction `FSRandomAccessFile.Prefetch()` default return status is changed from `OK` to `NotSupported`. If the user inherited file doesn't implement prefetch, RocksDB will create internal prefetch buffer to improve read performance.
* When retryable IO error happens during Flush (manifest write error is excluded) and WAL is disabled, originally it is mapped to kHardError. Now,it is mapped to soft error. So DB will not stall the writes unless the memtable is full. At the same time, when auto resume is triggered to recover the retryable IO error during Flush, SwitchMemtable is not called to avoid generating to many small immutable memtables. If WAL is enabled, no behavior changes.
* When considering whether a table file is already backed up in a shared part of backup directory, BackupEngine would already query the sizes of source (DB) and pre-existing destination (backup) files. BackupEngine now uses these file sizes to detect corruption, as at least one of (a) old backup, (b) backup in progress, or (c) current DB is corrupt if there's a size mismatch.
### Others
* Error in prefetching partitioned index blocks will not be swallowed. It will fail the query and return the IOError users.2020-10-13T16:44:50+00:00rocksdb v6.12.7rocksdb v6.12.72020-10-14T18:01:16+00:00## 6.12.7 (2020-10-14)
### Other
Fix build issue to enable RocksJava release for ppc64le2020-10-14T18:01:16+00:00rocksdb v6.14.5rocksdb v6.14.52020-11-17T00:21:35+00:00## 6.14.5 (11/15/2020)
### Bug Fixes
* Fix a bug of encoding and parsing BlockBasedTableOptions::read_amp_bytes_per_bit as a 64-bit integer.
## 6.14.4 (11/05/2020)
### Bug Fixes
Fixed a potential bug caused by evaluating `TableBuilder::NeedCompact()` before `TableBuilder::Finish()` in compaction job. For example, the `NeedCompact()` method of `CompactOnDeletionCollector` returned by built-in `CompactOnDeletionCollectorFactory` requires `BlockBasedTable::Finish()` to return the correct result. The bug can cause a compaction-generated file not to be marked for future compaction based on deletion ratio.
## 6.14.3 (10/30/2020)
### Bug Fixes
* Reverted a behavior change silently introduced in 6.14.2, in which the effects of the `ignore_unknown_options` flag (used in option parsing/loading functions) changed.
* Reverted a behavior change silently introduced in 6.14, in which options parsing/loading functions began returning `NotFound` instead of `InvalidArgument` for option names not available in the present version.
## 6.14.2 (10/21/2020)
### Bug Fixes
* Fixed a bug which causes hang in closing DB when refit level is set in opt build. It was because ContinueBackgroundWork() was called in assert statement which is a no op. It was introduced in 6.14.
## 6.14.1 (10/13/2020)
### Bug Fixes
* Since 6.12, memtable lookup should report unrecognized value_type as corruption (#7121).
* Since 6.14, fix false positive flush/compaction `Status::Corruption` failure when `paranoid_file_checks == true` and range tombstones were written to the compaction output files.
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
## 6.14 (10/09/2020)
### Bug fixes
* Fixed a bug after a `CompactRange()` with `CompactRangeOptions::change_level` set fails due to a conflict in the level change step, which caused all subsequent calls to `CompactRange()` with `CompactRangeOptions::change_level` set to incorrectly fail with a `Status::NotSupported("another thread is refitting")` error.
* Fixed a bug that the bottom most level compaction could still be a trivial move even if `BottommostLevelCompaction.kForce` or `kForceOptimized` is set.
### Public API Change
* The methods to create and manage EncrypedEnv have been changed. The EncryptionProvider is now passed to NewEncryptedEnv as a shared pointer, rather than a raw pointer. Comparably, the CTREncryptedProvider now takes a shared pointer, rather than a reference, to a BlockCipher. CreateFromString methods have been added to BlockCipher and EncryptionProvider to provide a single API by which different ciphers and providers can be created, respectively.
* The internal classes (CTREncryptionProvider, ROT13BlockCipher, CTRCipherStream) associated with the EncryptedEnv have been moved out of the public API. To create a CTREncryptionProvider, one can either use EncryptionProvider::NewCTRProvider, or EncryptionProvider::CreateFromString("CTR"). To create a new ROT13BlockCipher, one can either use BlockCipher::NewROT13Cipher or BlockCipher::CreateFromString("ROT13").
* The EncryptionProvider::AddCipher method has been added to allow keys to be added to an EncryptionProvider. This API will allow future providers to support multiple cipher keys.
* Add a new option "allow_data_in_errors". When this new option is set by users, it allows users to opt-in to get error messages containing corrupted keys/values. Corrupt keys, values will be logged in the messages, logs, status etc. that will help users with the useful information regarding affected data. By default value of this option is set false to prevent users data to be exposed in the messages so currently, data will be redacted from logs, messages, status by default.
* AdvancedColumnFamilyOptions::force_consistency_checks is now true by default, for more proactive DB corruption detection at virtually no cost (estimated two extra CPU cycles per million on a major production workload). Corruptions reported by these checks now mention "force_consistency_checks" in case a false positive corruption report is suspected and the option needs to be disabled (unlikely). Since existing column families have a saved setting for force_consistency_checks, only new column families will pick up the new default.
### General Improvements
* The settings of the DBOptions and ColumnFamilyOptions are now managed by Configurable objects (see New Features). The same convenience methods to configure these options still exist but the backend implementation has been unified under a common implementation.
### New Features
* Methods to configure serialize, and compare -- such as TableFactory -- are exposed directly through the Configurable base class (from which these objects inherit). This change will allow for better and more thorough configuration management and retrieval in the future. The options for a Configurable object can be set via the ConfigureFromMap, ConfigureFromString, or ConfigureOption method. The serialized version of the options of an object can be retrieved via the GetOptionString, ToString, or GetOption methods. The list of options supported by an object can be obtained via the GetOptionNames method. The "raw" object (such as the BlockBasedTableOption) for an option may be retrieved via the GetOptions method. Configurable options can be compared via the AreEquivalent method. The settings within a Configurable object may be validated via the ValidateOptions method. The object may be intialized (at which point only mutable options may be updated) via the PrepareOptions method.
* Introduce options.check_flush_compaction_key_order with default value to be true. With this option, during flush and compaction, key order will be checked when writing to each SST file. If the order is violated, the flush or compaction will fail.
* Added is_full_compaction to CompactionJobStats, so that the information is available through the EventListener interface.
* Add more stats for MultiGet in Histogram to get number of data blocks, index blocks, filter blocks and sst files read from file system per level.2020-11-17T00:21:35+00:00rocksdb v6.14.6rocksdb v6.14.62020-12-01T23:59:09+00:00## 6.14.6 (12/01/2020)
### Bug Fixes
* Truncated WALs ending in incomplete records can no longer produce gaps in the recovered data when `WALRecoveryMode::kPointInTimeRecovery` is used. Gaps are still possible when WALs are truncated exactly on record boundaries.2020-12-01T23:59:09+00:00rocksdb v6.15.2rocksdb v6.15.22020-12-30T00:20:27+00:00## 6.15.2 (12/22/2020)
### Bug Fixes
* Fix failing RocksJava test compilation and add CI jobs
* Fix jemalloc compilation issue on macOS
* Fix build issues - compatibility with older gcc, older jemalloc libraries, docker warning when building i686 binaries
## 6.15.1 (12/01/2020)
### Bug Fixes
* Truncated WALs ending in incomplete records can no longer produce gaps in the recovered data when `WALRecoveryMode::kPointInTimeRecovery` is used. Gaps are still possible when WALs are truncated exactly on record boundaries.
* Fix a bug where compressed blocks read by MultiGet are not inserted into the compressed block cache when use_direct_reads = true.
## 6.15.0 (11/13/2020)
### Bug Fixes
* Fixed a bug in the following combination of features: indexes with user keys (`format_version >= 3`), indexes are partitioned (`index_type == kTwoLevelIndexSearch`), and some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`). The bug could cause keys to be truncated when read from the index leading to wrong read results or other unexpected behavior.
* Fixed a bug when indexes are partitioned (`index_type == kTwoLevelIndexSearch`), some index partitions are pinned in memory (`BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache`), and partitions reads could be mixed between block cache and directly from the file (e.g., with `enable_index_compression == 1` and `mmap_read == 1`, partitions that were stored uncompressed due to poor compression ratio would be read directly from the file via mmap, while partitions that were stored compressed would be read from block cache). The bug could cause index partitions to be mistakenly considered empty during reads leading to wrong read results.
* Since 6.12, memtable lookup should report unrecognized value_type as corruption (#7121).
* Since 6.14, fix false positive flush/compaction `Status::Corruption` failure when `paranoid_file_checks == true` and range tombstones were written to the compaction output files.
* Since 6.14, fix a bug that could cause a stalled write to crash with mixed of slowdown and no_slowdown writes (`WriteOptions.no_slowdown=true`).
* Fixed a bug which causes hang in closing DB when refit level is set in opt build. It was because ContinueBackgroundWork() was called in assert statement which is a no op. It was introduced in 6.14.
* Fixed a bug which causes Get() to return incorrect result when a key's merge operand is applied twice. This can occur if the thread performing Get() runs concurrently with a background flush thread and another thread writing to the MANIFEST file (PR6069).
* Reverted a behavior change silently introduced in 6.14.2, in which the effects of the `ignore_unknown_options` flag (used in option parsing/loading functions) changed.
* Reverted a behavior change silently introduced in 6.14, in which options parsing/loading functions began returning `NotFound` instead of `InvalidArgument` for option names not available in the present version.
* Fixed MultiGet bugs it doesn't return valid data with user defined timestamp.
* Fixed a potential bug caused by evaluating `TableBuilder::NeedCompact()` before `TableBuilder::Finish()` in compaction job. For example, the `NeedCompact()` method of `CompactOnDeletionCollector` returned by built-in `CompactOnDeletionCollectorFactory` requires `BlockBasedTable::Finish()` to return the correct result. The bug can cause a compaction-generated file not to be marked for future compaction based on deletion ratio.
* Fixed a seek issue with prefix extractor and timestamp.
* Fixed a bug of encoding and parsing BlockBasedTableOptions::read_amp_bytes_per_bit as a 64-bit integer.
* Fixed the logic of populating native data structure for `read_amp_bytes_per_bit` during OPTIONS file parsing on big-endian architecture. Without this fix, original code introduced in PR7659, when running on big-endian machine, can mistakenly store read_amp_bytes_per_bit (an uint32) in little endian format. Future access to `read_amp_bytes_per_bit` will give wrong values. Little endian architecture is not affected.
### Public API Change
* Deprecate `BlockBasedTableOptions::pin_l0_filter_and_index_blocks_in_cache` and `BlockBasedTableOptions::pin_top_level_index_and_filter`. These options still take effect until users migrate to the replacement APIs in `BlockBasedTableOptions::metadata_cache_options`. Migration guidance can be found in the API comments on the deprecated options.
* Add new API `DB::VerifyFileChecksums` to verify SST file checksum with corresponding entries in the MANIFEST if present. Current implementation requires scanning and recomputing file checksums.
### Behavior Changes
* The dictionary compression settings specified in `ColumnFamilyOptions::compression_opts` now additionally affect files generated by flush and compaction to non-bottommost level. Previously those settings at most affected files generated by compaction to bottommost level, depending on whether `ColumnFamilyOptions::bottommost_compression_opts` overrode them. Users who relied on dictionary compression settings in `ColumnFamilyOptions::compression_opts` affecting only the bottommost level can keep the behavior by moving their dictionary settings to `ColumnFamilyOptions::bottommost_compression_opts` and setting its `enabled` flag.
* When the `enabled` flag is set in `ColumnFamilyOptions::bottommost_compression_opts`, those compression options now take effect regardless of the value in `ColumnFamilyOptions::bottommost_compression`. Previously, those compression options only took effect when `ColumnFamilyOptions::bottommost_compression != kDisableCompressionOption`. Now, they additionally take effect when `ColumnFamilyOptions::bottommost_compression == kDisableCompressionOption` (such a setting causes bottommost compression type to fall back to `ColumnFamilyOptions::compression_per_level` if configured, and otherwise fall back to `ColumnFamilyOptions::compression`).
### New Features
* An EXPERIMENTAL new Bloom alternative that saves about 30% space compared to Bloom filters, with about 3-4x construction time and similar query times is available using NewExperimentalRibbonFilterPolicy.
2020-12-30T00:20:27+00:00rocksdb v6.15.4rocksdb v6.15.42021-01-21T20:44:58+00:00## 6.15.4 (01/21/2021)
### Bug Fixes
* Fix a race condition between DB startups and shutdowns in managing the periodic background worker threads. One effect of this race condition could be the process being terminated.
## 6.15.3 (01/07/2021)
### Bug Fixes
* For Java builds, fix errors due to missing compression library includes.2021-01-21T20:44:58+00:00rocksdb v6.15.5rocksdb v6.15.52021-02-06T01:23:01+00:00## 6.15.5 (02/05/2021)
### Bug Fixes
* Since 6.15.0, `TransactionDB` returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees. There are certain cases where range deletion can still be used on such DBs; see the API doc on `TransactionDB::DeleteRange()` for details.
* `OptimisticTransactionDB` now returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees.2021-02-06T01:23:01+00:00rocksdb v6.16.3rocksdb v6.16.32021-03-14T19:32:17+00:00## 6.16.3 (2021-02-05)
### Bug Fixes
* Since 6.15.0, `TransactionDB` returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees. There are certain cases where range deletion can still be used on such DBs; see the API doc on `TransactionDB::DeleteRange()` for details.
* `OptimisticTransactionDB` now returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees.
## 6.16.2 (2021-01-21)
### Bug Fixes
* Fix a race condition between DB startups and shutdowns in managing the periodic background worker threads. One effect of this race condition could be the process being terminated.
## 6.16.1 (2021-01-20)
### Bug Fixes
* Version older than 6.15 cannot decode VersionEdits `WalAddition` and `WalDeletion`, fixed this by changing the encoded format of them to be ignorable by older versions.
## 6.16.0 (2020-12-18)
### Behavior Changes
* Attempting to write a merge operand without explicitly configuring `merge_operator` now fails immediately, causing the DB to enter read-only mode. Previously, failure was deferred until the `merge_operator` was needed by a user read or a background operation.
* Since RocksDB does not continue write the same file if a file write fails for any reason, the file scope write IO error is treated the same as retryable IO error. More information about error handling of file scope IO error is included in `ErrorHandler::SetBGError`.
### Bug Fixes
* Truncated WALs ending in incomplete records can no longer produce gaps in the recovered data when `WALRecoveryMode::kPointInTimeRecovery` is used. Gaps are still possible when WALs are truncated exactly on record boundaries; for complete protection, users should enable `track_and_verify_wals_in_manifest`.
* Fix a bug where compressed blocks read by MultiGet are not inserted into the compressed block cache when use_direct_reads = true.
* Fixed the issue of full scanning on obsolete files when there are too many outstanding compactions with ConcurrentTaskLimiter enabled.
* Fixed the logic of populating native data structure for `read_amp_bytes_per_bit` during OPTIONS file parsing on big-endian architecture. Without this fix, original code introduced in PR7659, when running on big-endian machine, can mistakenly store read_amp_bytes_per_bit (an uint32) in little endian format. Future access to `read_amp_bytes_per_bit` will give wrong values. Little endian architecture is not affected.
* Fixed prefix extractor with timestamp issues.
* Fixed a bug in atomic flush: in two-phase commit mode, the minimum WAL log number to keep is incorrect.
* Fixed a bug related to checkpoint in PR7789: if there are multiple column families, and the checkpoint is not opened as read only, then in rare cases, data loss may happen in the checkpoint. Since backup engine relies on checkpoint, it may also be affected.
### New Features
* User defined timestamp feature supports `CompactRange` and `GetApproximateSizes`.
* Support getting aggregated table properties (kAggregatedTableProperties and kAggregatedTablePropertiesAtLevel) with DB::GetMapProperty, for easier access to the data in a structured format.
* Experimental option BlockBasedTableOptions::optimize_filters_for_memory now works with experimental Ribbon filter (as well as Bloom filter).
### Public API Change
* Deprecated public but rarely-used FilterBitsBuilder::CalculateNumEntry, which is replaced with ApproximateNumEntries taking a size_t parameter and returning size_t.
* Added a new option `track_and_verify_wals_in_manifest`. If `true`, the log numbers and sizes of the synced WALs are tracked in MANIFEST, then during DB recovery, if a synced WAL is missing from disk, or the WAL's size does not match the recorded size in MANIFEST, an error will be reported and the recovery will be aborted. Note that this option does not work with secondary instance.
2021-03-14T19:32:17+00:00rocksdb v6.17.3rocksdb v6.17.32021-03-14T19:35:30+00:00## 6.17.3 (2021-02-18)
### Bug Fixes
* Fix `WRITE_PREPARED`, `WRITE_UNPREPARED` TransactionDB `MultiGet()` may return uncommitted data with snapshot.
## 6.17.2 (2021-02-05)
### Bug Fixes
* Since 6.15.0, `TransactionDB` returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees. There are certain cases where range deletion can still be used on such DBs; see the API doc on `TransactionDB::DeleteRange()` for details.
* `OptimisticTransactionDB` now returns error `Status`es from calls to `DeleteRange()` and calls to `Write()` where the `WriteBatch` contains a range deletion. Previously such operations may have succeeded while not providing the expected transactional guarantees.
## 6.17.1 (2021-01-28)
### Behavior Changes
* When retryable IO error occurs during compaction, it is mapped to soft error and set the BG error. However, auto resume is not called to clean the soft error since compaction will reschedule by itself. In this change, When retryable IO error occurs during compaction, BG error is not set. User will be informed the error via EventHelper.
## 6.17.0 (2021-01-15)
### Behavior Changes
* When verifying full file checksum with `DB::VerifyFileChecksums()`, we now fail with `Status::InvalidArgument` if the name of the checksum generator used for verification does not match the name of the checksum generator used for protecting the file when it was created.
* Since RocksDB does not continue write the same file if a file write fails for any reason, the file scope write IO error is treated the same as retryable IO error. More information about error handling of file scope IO error is included in `ErrorHandler::SetBGError`.
### Bug Fixes
* Version older than 6.15 cannot decode VersionEdits `WalAddition` and `WalDeletion`, fixed this by changing the encoded format of them to be ignorable by older versions.
* Fix a race condition between DB startups and shutdowns in managing the periodic background worker threads. One effect of this race condition could be the process being terminated.
### Public API Change
* Add a public API WriteBufferManager::dummy_entries_in_cache_usage() which reports the size of dummy entries stored in cache (passed to WriteBufferManager). Dummy entries are used to account for DataBlocks.
2021-03-14T19:35:30+00:00rocksdb v6.16.4rocksdb v6.16.42021-03-30T22:59:25+00:00## 6.16.4 (2021-03-30)
### Bug Fixes
* Fix build on ppc64 and musl build.2021-03-30T22:59:25+00:00rocksdb v6.19.3rocksdb v6.19.32021-04-20T20:49:23+00:00## 6.19.3 (04/19/2021)
### Bug Fixes
* Fixed a bug in handling file rename error in distributed/network file systems when the server succeeds but client returns error. The bug can cause CURRENT file to point to non-existing MANIFEST file, thus DB cannot be opened.
## 6.19.2 (04/08/2021)
### Bug Fixes
* Fixed a backward iteration bug with partitioned filter enabled: not including the prefix of the last key of the previous filter partition in current filter partition can cause wrong iteration result.
## 6.19.1 (04/01/2021)
### Bug Fixes
* Fixed crash (divide by zero) when compression dictionary is applied to a file containing only range tombstones.
## 6.19.0 (03/21/2021)
### Bug Fixes
* Fixed the truncation error found in APIs/tools when dumping block-based SST files in a human-readable format. After fix, the block-based table can be fully dumped as a readable file.
* When hitting a write slowdown condition, no write delay (previously 1 millisecond) is imposed until `delayed_write_rate` is actually exceeded, with an initial burst allowance of 1 millisecond worth of bytes. Also, beyond the initial burst allowance, `delayed_write_rate` is now more strictly enforced, especially with multiple column families.
### Public API change
* Changed default `BackupableDBOptions::share_files_with_checksum` to `true` and deprecated `false` because of potential for data loss. Note that accepting this change in behavior can temporarily increase backup data usage because files are not shared between backups using the two different settings. Also removed obsolete option kFlagMatchInterimNaming.
* Add a new option BlockBasedTableOptions::max_auto_readahead_size. RocksDB does auto-readahead for iterators on noticing more than two reads for a table file if user doesn't provide readahead_size. The readahead starts at 8KB and doubles on every additional read upto max_auto_readahead_size and now max_auto_readahead_size can be configured dynamically as well. Found that 256 KB readahead size provides the best performance, based on experiments, for auto readahead. Experiment data is in PR #3282. If value is set 0 then no automatic prefetching will be done by rocksdb. Also changing the value will only affect files opened after the change.
* Add suppport to extend DB::VerifyFileChecksums API to also verify blob files checksum.
* When using the new BlobDB, the amount of data written by flushes/compactions is now broken down into table files and blob files in the compaction statistics; namely, Write(GB) denotes the amount of data written to table files, while Wblob(GB) means the amount of data written to blob files.
* New default BlockBasedTableOptions::format_version=5 to enable new Bloom filter implementation by default, compatible with RocksDB versions >= 6.6.0.
* Add new SetBufferSize API to WriteBufferManager to allow dynamic management of memory allotted to all write buffers. This allows user code to adjust memory monitoring provided by WriteBufferManager as process memory needs change datasets grow and shrink.
* Clarified the required semantics of Read() functions in FileSystem and Env APIs. Please ensure any custom implementations are compliant.
* For the new integrated BlobDB implementation, compaction statistics now include the amount of data read from blob files during compaction (due to garbage collection or compaction filters). Write amplification metrics have also been extended to account for data read from blob files.
* Add EqualWithoutTimestamp() to Comparator.
* Extend support to track blob files in SSTFileManager whenever a blob file is created/deleted. Blob files will be scheduled to delete via SSTFileManager and SStFileManager will now take blob files in account while calculating size and space limits along with SST files.
* Add new Append and PositionedAppend API with checksum handoff to legacy Env.
### New Features
* Support compaction filters for the new implementation of BlobDB. Add `FilterBlobByKey()` to `CompactionFilter`. Subclasses can override this method so that compaction filters can determine whether the actual blob value has to be read during compaction. Use a new `kUndetermined` in `CompactionFilter::Decision` to indicated that further action is necessary for compaction filter to make a decision.
* Add support to extend retrieval of checksums for blob files from the MANIFEST when checkpointing. During backup, rocksdb can detect corruption in blob files during file copies.
* Add new options for db_bench --benchmarks: flush, waitforcompaction, compact0, compact1.
* Add an option to BackupEngine::GetBackupInfo to include the name and size of each backed-up file. Especially in the presence of file sharing among backups, this offers detailed insight into backup space usage.
* Enable backward iteration on keys with user-defined timestamps.
* Add statistics and info log for error handler: counters for bg error, bg io error, bg retryable io error, auto resume count, auto resume total retry number, and auto resume sucess; Histogram for auto resume retry count in each recovery call. Note that, each auto resume attempt will have one or multiple retries.
### Behavior Changes
* During flush, only WAL sync retryable IO error is mapped to hard error, which will stall the writes. When WAL is used but only SST file write has retryable IO error, it will be mapped to soft error and write will not be affected.2021-04-20T20:49:23+00:00rocksdb v6.20.3rocksdb v6.20.32021-05-06T00:53:37+00:00## 6.20.3 (05/05/2021)
### Bug Fixes
* Fixed a bug where `GetLiveFiles()` output included a non-existent file called "OPTIONS-000000". Backups and checkpoints, which use `GetLiveFiles()`, failed on DBs impacted by this bug. Read-write DBs were impacted when the latest OPTIONS file failed to write and `fail_if_options_file_error == false`. Read-only DBs were impacted when no OPTIONS files existed.
## 6.20.2 (04/23/2021)
### Bug Fixes
* Fixed a bug in handling file rename error in distributed/network file systems when the server succeeds but client returns error. The bug can cause CURRENT file to point to non-existing MANIFEST file, thus DB cannot be opened.
* Fixed a bug where ingested files were written with incorrect boundary key metadata. In rare cases this could have led to a level's files being wrongly ordered and queries for the boundary keys returning wrong results.
* Fixed a data race between insertion into memtables and the retrieval of the DB properties `rocksdb.cur-size-active-mem-table`, `rocksdb.cur-size-all-mem-tables`, and `rocksdb.size-all-mem-tables`.
* Fixed the false-positive alert when recovering from the WAL file. Avoid reporting "SST file is ahead of WAL" on a newly created empty column family, if the previous WAL file is corrupted.
### Behavior Changes
* Due to the fix of false-postive alert of "SST file is ahead of WAL", all the CFs with no SST file (CF empty) will bypass the consistency check. We fixed a false-positive, but introduced a very rare true-negative which will be triggered in the following conditions: A CF with some delete operations in the last a few queries which will result in an empty CF (those are flushed to SST file and a compaction triggered which combines this file and all other SST files and generates an empty CF, or there is another reason to write a manifest entry for this CF after a flush that generates no SST file from an empty CF). The deletion entries are logged in a WAL and this WAL was corrupted, while the CF's log number points to the next WAL (due to the flush). Therefore, the DB can only recover to the point without these trailing deletions and cause the inconsistent DB status.
## 6.20.0 (04/16/2021)
### Behavior Changes
* `ColumnFamilyOptions::sample_for_compression` now takes effect for creation of all block-based tables. Previously it only took effect for block-based tables created by flush.
* `CompactFiles()` can no longer compact files from lower level to up level, which has the risk to corrupt DB (details: #8063). The validation is also added to all compactions.
* Fixed some cases in which DB::OpenForReadOnly() could write to the filesystem. If you want a Logger with a read-only DB, you must now set DBOptions::info_log yourself, such as using CreateLoggerFromOptions().
* get_iostats_context() will never return nullptr. If thread-local support is not available, and user does not opt-out iostats context, then compilation will fail. The same applies to perf context as well.
### Bug Fixes
* Use thread-safe `strerror_r()` to get error messages.
* Fixed a potential hang in shutdown for a DB whose `Env` has high-pri thread pool disabled (`Env::GetBackgroundThreads(Env::Priority::HIGH) == 0`)
* Made BackupEngine thread-safe and added documentation comments to clarify what is safe for multiple BackupEngine objects accessing the same backup directory.
* Fixed crash (divide by zero) when compression dictionary is applied to a file containing only range tombstones.
* Fixed a backward iteration bug with partitioned filter enabled: not including the prefix of the last key of the previous filter partition in current filter partition can cause wrong iteration result.
* Fixed a bug that allowed `DBOptions::max_open_files` to be set with a non-negative integer with `ColumnFamilyOptions::compaction_style = kCompactionStyleFIFO`.
* Fixed a bug in handling file rename error in distributed/network file systems when the server succeeds but client returns error. The bug can cause CURRENT file to point to non-existing MANIFEST file, thus DB cannot be opened.
* Fixed a data race between insertion into memtables and the retrieval of the DB properties `rocksdb.cur-size-active-mem-table`, `rocksdb.cur-size-all-mem-tables`, and `rocksdb.size-all-mem-tables`.
### Performance Improvements
* On ARM platform, use `yield` instead of `wfe` to relax cpu to gain better performance.
### Public API change
* Added `TableProperties::slow_compression_estimated_data_size` and `TableProperties::fast_compression_estimated_data_size`. When `ColumnFamilyOptions::sample_for_compression > 0`, they estimate what `TableProperties::data_size` would have been if the "fast" or "slow" (see `ColumnFamilyOptions::sample_for_compression` API doc for definitions) compression had been used instead.
* Update DB::StartIOTrace and remove Env object from the arguments as its redundant and DB already has Env object that is passed down to IOTracer::StartIOTrace
* Added `FlushReason::kWalFull`, which is reported when a memtable is flushed due to the WAL reaching its size limit; those flushes were previously reported as `FlushReason::kWriteBufferManager`. Also, changed the reason for flushes triggered by the write buffer manager to `FlushReason::kWriteBufferManager`; they were previously reported as `FlushReason::kWriteBufferFull`.
* Extend file_checksum_dump ldb command and DB::GetLiveFilesChecksumInfo API for IntegratedBlobDB and get checksum of blob files along with SST files.
### New Features
* Added the ability to open BackupEngine backups as read-only DBs, using BackupInfo::name_for_open and env_for_open provided by BackupEngine::GetBackupInfo() with include_file_details=true.
* Added BackupEngine support for integrated BlobDB, with blob files shared between backups when table files are shared. Because of current limitations, blob files always use the kLegacyCrc32cAndFileSize naming scheme, and incremental backups must read and checksum all blob files in a DB, even for files that are already backed up.
* Added an optional output parameter to BackupEngine::CreateNewBackup(WithMetadata) to return the BackupID of the new backup.
* Added BackupEngine::GetBackupInfo / GetLatestBackupInfo for querying individual backups.
* Made the Ribbon filter a long-term supported feature in terms of the SST schema(compatible with version >= 6.15.0) though the API for enabling it is expected to change.
2021-05-06T00:53:37+00:00rocksdb v6.22.1rocksdb v6.22.12021-07-12T20:49:10+00:00## 6.22.1 (2021-06-25)
### Bug Fixes
* `GetLiveFilesMetaData()` now populates the `temperature`, `oldest_ancester_time`, and `file_creation_time` fields of its `LiveFileMetaData` results when the information is available. Previously these fields always contained zero indicating unknown.
## 6.22.0 (2021-06-18)
### Behavior Changes
* Added two additional tickers, MEMTABLE_PAYLOAD_BYTES_AT_FLUSH and MEMTABLE_GARBAGE_BYTES_AT_FLUSH. These stats can be used to estimate the ratio of "garbage" (outdated) bytes in the memtable that are discarded at flush time.
* Added API comments clarifying safe usage of Disable/EnableManualCompaction and EventListener callbacks for compaction.
### Bug Fixes
* fs_posix.cc GetFreeSpace() always report disk space available to root even when running as non-root. Linux defaults often have disk mounts with 5 to 10 percent of total space reserved only for root. Out of space could result for non-root users.
* Subcompactions are now disabled when user-defined timestamps are used, since the subcompaction boundary picking logic is currently not timestamp-aware, which could lead to incorrect results when different subcompactions process keys that only differ by timestamp.
* Fix an issue that `DeleteFilesInRange()` may cause ongoing compaction reports corruption exception, or ASSERT for debug build. There's no actual data loss or corruption that we find.
* Fixed confusingly duplicated output in LOG for periodic stats ("DUMPING STATS"), including "Compaction Stats" and "File Read Latency Histogram By Level".
* Fixed performance bugs in background gathering of block cache entry statistics, that could consume a lot of CPU when there are many column families with a shared block cache.
### New Features
* Marked the Ribbon filter and optimize_filters_for_memory features as production-ready, each enabling memory savings for Bloom-like filters. Use `NewRibbonFilterPolicy` in place of `NewBloomFilterPolicy` to use Ribbon filters instead of Bloom, or `ribbonfilter` in place of `bloomfilter` in configuration string.
* Allow `DBWithTTL` to use `DeleteRange` api just like other DBs. `DeleteRangeCF()` which executes `WriteBatchInternal::DeleteRange()` has been added to the handler in `DBWithTTLImpl::Write()` to implement it.
* Add BlockBasedTableOptions.prepopulate_block_cache. If enabled, it prepopulate warm/hot data blocks which are already in memory into block cache at the time of flush. On a flush, the data block that is in memory (in memtables) get flushed to the device. If using Direct IO, additional IO is incurred to read this data back into memory again, which is avoided by enabling this option and it also helps with Distributed FileSystem. More details in include/rocksdb/table.h.
* Added a `cancel` field to `CompactRangeOptions`, allowing individual in-process manual range compactions to be cancelled.2021-07-12T20:49:10+00:00rocksdb v6.23.3rocksdb v6.23.32021-10-13T22:57:24+00:00## 6.23.3 (2021-08-09)
### Bug Fixes
* Removed a call to `RenameFile()` on a non-existent info log file ("LOG") when opening a new DB. Such a call was guaranteed to fail though did not impact applications since we swallowed the error. Now we also stopped swallowing errors in renaming "LOG" file.
* Fixed a bug affecting the batched `MultiGet` API when used with keys spanning multiple column families and `sorted_input == false`.
## 6.23.2 (2021-08-04)
### Bug Fixes
* Fixed a race related to the destruction of `ColumnFamilyData` objects. The earlier logic unlocked the DB mutex before destroying the thread-local `SuperVersion` pointers, which could result in a process crash if another thread managed to get a reference to the `ColumnFamilyData` object.
* Fixed an issue where `OnFlushCompleted` was not called for atomic flush.
## 6.23.1 (2021-07-22)
### Bug Fixes
* Fix a race condition during multiple DB instances opening.
## 6.23.0 (2021-07-16)
### Behavior Changes
* Obsolete keys in the bottommost level that were preserved for a snapshot will now be cleaned upon snapshot release in all cases. This form of compaction (snapshot release triggered compaction) previously had an artificial limitation that multiple tombstones needed to be present.
### Bug Fixes
* Blob file checksums are now printed in hexadecimal format when using the `manifest_dump` `ldb` command.
* `GetLiveFilesMetaData()` now populates the `temperature`, `oldest_ancester_time`, and `file_creation_time` fields of its `LiveFileMetaData` results when the information is available. Previously these fields always contained zero indicating unknown.
* Fix mismatches of OnCompaction{Begin,Completed} in case of DisableManualCompaction().
* Fix continuous logging of an existing background error on every user write
* Fix a bug that `Get()` return Status::OK() and an empty value for non-existent key when `read_options.read_tier = kBlockCacheTier`.
* Fix a bug that stat in `get_context` didn't accumulate to statistics when query is failed.
### New Features
* ldb has a new feature, `list_live_files_metadata`, that shows the live SST files, as well as their LSM storage level and the column family they belong to.
* The new BlobDB implementation now tracks the amount of garbage in each blob file in the MANIFEST.
* Integrated BlobDB now supports Merge with base values (Put/Delete etc.).
* RemoteCompaction supports sub-compaction, the job_id in the user interface is changed from `int` to `uint64_t` to support sub-compaction id.
* Expose statistics option in RemoteCompaction worker.
### Public API change
* Added APIs to the Customizable class to allow developers to create their own Customizable classes. Created the utilities/customizable_util.h file to contain helper methods for developing new Customizable classes.
* Change signature of SecondaryCache::Name(). Make SecondaryCache customizable and add SecondaryCache::CreateFromString method.
2021-10-13T22:57:24+00:00rocksdb v6.24.2rocksdb v6.24.22021-10-13T23:22:17+00:00## 6.24.2 (2021-09-16)
### Bug Fixes
* Add checks for validity of the IO uring completion queue entries, and fail the BlockBasedTableReader MultiGet sub-batch if there's an invalid completion
## 6.24.1 (2021-08-31)
### Bug Fixes
* Fix a race in item ref counting in LRUCache when promoting an item from the SecondaryCache.
## 6.24.0 (2021-08-20)
### Bug Fixes
* If the primary's CURRENT file is missing or inaccessible, the secondary instance should not hang repeatedly trying to switch to a new MANIFEST. It should instead return the error code encountered while accessing the file.
* Restoring backups with BackupEngine is now a logically atomic operation, so that if a restore operation is interrupted, DB::Open on it will fail. Using BackupEngineOptions::sync (default) ensures atomicity even in case of power loss or OS crash.
* Fixed a race related to the destruction of `ColumnFamilyData` objects. The earlier logic unlocked the DB mutex before destroying the thread-local `SuperVersion` pointers, which could result in a process crash if another thread managed to get a reference to the `ColumnFamilyData` object.
* Removed a call to `RenameFile()` on a non-existent info log file ("LOG") when opening a new DB. Such a call was guaranteed to fail though did not impact applications since we swallowed the error. Now we also stopped swallowing errors in renaming "LOG" file.
* Fixed an issue where `OnFlushCompleted` was not called for atomic flush.
* Fixed a bug affecting the batched `MultiGet` API when used with keys spanning multiple column families and `sorted_input == false`.
* Fixed a potential incorrect result in opt mode and assertion failures caused by releasing snapshot(s) during compaction.
* Fixed passing of BlobFileCompletionCallback to Compaction job and Atomic flush job which was default paramter (nullptr). BlobFileCompletitionCallback is internal callback that manages addition of blob files to SSTFileManager.
* Fixed MultiGet not updating the block_read_count and block_read_byte PerfContext counters
### New Features
* Made the EventListener extend the Customizable class.
* EventListeners that have a non-empty Name() and that are registered with the ObjectRegistry can now be serialized to/from the OPTIONS file.
* Insert warm blocks (data blocks, uncompressed dict blocks, index and filter blocks) in Block cache during flush under option BlockBasedTableOptions.prepopulate_block_cache. Previously it was enabled for only data blocks.
* BlockBasedTableOptions.prepopulate_block_cache can be dynamically configured using DB::SetOptions.
* Add CompactionOptionsFIFO.age_for_warm, which allows RocksDB to move old files to warm tier in FIFO compactions. Note that file temperature is still an experimental feature.
* Add a comment to suggest btrfs user to disable file preallocation by setting `options.allow_fallocate=false`.
* Fast forward option in Trace replay changed to double type to allow replaying at a lower speed, by settings the value between 0 and 1. This option can be set via `ReplayOptions` in `Replayer::Replay()`, or via `--trace_replay_fast_forward` in db_bench.
* Add property `LiveSstFilesSizeAtTemperature` to retrieve sst file size at different temperature.
* Added a stat rocksdb.secondary.cache.hits
* Added a PerfContext counter secondary_cache_hit_count
* The integrated BlobDB implementation now supports the tickers `BLOB_DB_BLOB_FILE_BYTES_READ`, `BLOB_DB_GC_NUM_KEYS_RELOCATED`, and `BLOB_DB_GC_BYTES_RELOCATED`, as well as the histograms `BLOB_DB_COMPRESSION_MICROS` and `BLOB_DB_DECOMPRESSION_MICROS`.
* Added hybrid configuration of Ribbon filter and Bloom filter where some LSM levels use Ribbon for memory space efficiency and some use Bloom for speed. See NewRibbonFilterPolicy. This also changes the default behavior of NewRibbonFilterPolicy to use Bloom for flushes under Leveled and Universal compaction and Ribbon otherwise. The C API function `rocksdb_filterpolicy_create_ribbon` is unchanged but adds new `rocksdb_filterpolicy_create_ribbon_hybrid`.
### Public API change
* Added APIs to decode and replay trace file via Replayer class. Added `DB::NewDefaultReplayer()` to create a default Replayer instance. Added `TraceReader::Reset()` to restart reading a trace file. Created trace_record.h, trace_record_result.h and utilities/replayer.h files to access the decoded Trace records, replay them, and query the actual operation results.
* Added Configurable::GetOptionsMap to the public API for use in creating new Customizable classes.
* Generalized bits_per_key parameters in C API from int to double for greater configurability. Although this is a compatible change for existing C source code, anything depending on C API signatures, such as foreign function interfaces, will need to be updated.
### Performance Improvements
* Try to avoid updating DBOptions if `SetDBOptions()` does not change any option value.
### Behavior Changes
* `StringAppendOperator` additionally accepts a string as the delimiter.
* BackupEngineOptions::sync (default true) now applies to restoring backups in addition to creating backups. This could slow down restores, but ensures they are fully persisted before returning OK. (Consider increasing max_background_operations to improve performance.)
2021-10-13T23:22:17+00:00rocksdb v6.25.1rocksdb v6.25.12021-10-13T23:31:48+00:00## 6.25.1 (2021-09-28)
### Bug Fixes
* Fixes a bug in directed IO mode when calling MultiGet() for blobs in the same blob file. The bug is caused by not sorting the blob read requests by file offsets.
## 6.25.0 (2021-09-20)
### Bug Fixes
* Allow secondary instance to refresh iterator. Assign read seq after referencing SuperVersion.
* Fixed a bug of secondary instance's last_sequence going backward, and reads on the secondary fail to see recent updates from the primary.
* Fixed a bug that could lead to duplicate DB ID or DB session ID in POSIX environments without /proc/sys/kernel/random/uuid.
* Fix a race in DumpStats() with column family destruction due to not taking a Ref on each entry while iterating the ColumnFamilySet.
* Fix a race in item ref counting in LRUCache when promoting an item from the SecondaryCache.
* Fix a race in BackupEngine if RateLimiter is reconfigured during concurrent Restore operations.
* Fix a bug on POSIX in which failure to create a lock file (e.g. out of space) can prevent future LockFile attempts in the same process on the same file from succeeding.
* Fix a bug that backup_rate_limiter and restore_rate_limiter in BackupEngine could not limit read rates.
* Fix the implementation of `prepopulate_block_cache = kFlushOnly` to only apply to flushes rather than to all generated files.
* Fix WAL log data corruption when using DBOptions.manual_wal_flush(true) and WriteOptions.sync(true) together. The sync WAL should work with locked log_write_mutex_.
* Add checks for validity of the IO uring completion queue entries, and fail the BlockBasedTableReader MultiGet sub-batch if there's an invalid completion
* Add an interface RocksDbIOUringEnable() that, if defined by the user, will allow them to enable/disable the use of IO uring by RocksDB
* Fix the bug that when direct I/O is used and MultiRead() returns a short result, RandomAccessFileReader::MultiRead() still returns full size buffer, with returned short value together with some data in original buffer. This bug is unlikely cause incorrect results, because (1) since FileSystem layer is expected to retry on short result, returning short results is only possible when asking more bytes in the end of the file, which RocksDB doesn't do when using MultiRead(); (2) checksum is unlikely to match.
### New Features
* RemoteCompaction's interface now includes `db_name`, `db_id`, `session_id`, which could help the user uniquely identify compaction job between db instances and sessions.
* Added a ticker statistic, "rocksdb.verify_checksum.read.bytes", reporting how many bytes were read from file to serve `VerifyChecksum()` and `VerifyFileChecksums()` queries.
* Added ticker statistics, "rocksdb.backup.read.bytes" and "rocksdb.backup.write.bytes", reporting how many bytes were read and written during backup.
* Added properties for BlobDB: `rocksdb.num-blob-files`, `rocksdb.blob-stats`, `rocksdb.total-blob-file-size`, and `rocksdb.live-blob-file-size`. The existing property `rocksdb.estimate_live-data-size` was also extended to include live bytes residing in blob files.
* Added two new RateLimiter IOPriorities: `Env::IO_USER`,`Env::IO_MID`. `Env::IO_USER` will have superior priority over all other RateLimiter IOPriorities without being subject to fair scheduling constraint.
* `SstFileWriter` now supports `Put`s and `Delete`s with user-defined timestamps. Note that the ingestion logic itself is not timestamp-aware yet.
* Allow a single write batch to include keys from multiple column families whose timestamps' formats can differ. For example, some column families may disable timestamp, while others enable timestamp.
* Add compaction priority information in RemoteCompaction, which can be used to schedule high priority job first.
* Added new callback APIs `OnBlobFileCreationStarted`,`OnBlobFileCreated`and `OnBlobFileDeleted` in `EventListener` class of listener.h. It notifies listeners during creation/deletion of individual blob files in Integrated BlobDB. It also log blob file creation finished event and deletion event in LOG file.
* Batch blob read requests for `DB::MultiGet` using `MultiRead`.
* Add support for fallback to local compaction, the user can return `CompactionServiceJobStatus::kUseLocal` to instruct RocksDB to run the compaction locally instead of waiting for the remote compaction result.
* Add built-in rate limiter's implementation of `RateLimiter::GetTotalPendingRequest(int64_t* total_pending_requests, const Env::IOPriority pri)` for the total number of requests that are pending for bytes in the rate limiter.
* Charge memory usage during data buffering, from which training samples are gathered for dictionary compression, to block cache. Unbuffering data can now be triggered if the block cache becomes full and `strict_capacity_limit=true` for the block cache, in addition to existing conditions that can trigger unbuffering.
### Public API change
* Remove obsolete implementation details FullKey and ParseFullKey from public API
* Change `SstFileMetaData::size` from `size_t` to `uint64_t`.
* Made Statistics extend the Customizable class and added a CreateFromString method. Implementations of Statistics need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method.
* Extended `FlushJobInfo` and `CompactionJobInfo` in listener.h to provide information about the blob files generated by a flush/compaction and garbage collected during compaction in Integrated BlobDB. Added struct members `blob_file_addition_infos` and `blob_file_garbage_infos` that contain this information.
* Extended parameter `output_file_names` of `CompactFiles` API to also include paths of the blob files generated by the compaction in Integrated BlobDB.
* Most `BackupEngine` functions now return `IOStatus` instead of `Status`. Most existing code should be compatible with this change but some calls might need to be updated.
2021-10-13T23:31:48+00:00rocksdb v6.25.3rocksdb v6.25.32021-10-15T21:13:42+00:00## 6.25.3 (2021-10-14)
### Bug Fixes
* Fixed bug in calls to `IngestExternalFiles()` with files for multiple column families. The bug could have introduced a delay in ingested file keys becoming visible after `IngestExternalFiles()` returned. Furthermore, mutations to ingested file keys while they were invisible could have been dropped (not necessarily immediately).
* Fixed a possible race condition impacting users of `WriteBufferManager` who constructed it with `allow_stall == true`. The race condition led to undefined behavior (in our experience, typically a process crash).
* Fixed a bug where stalled writes would remain stalled forever after the user calls `WriteBufferManager::SetBufferSize()` with `new_size == 0` to dynamically disable memory limiting.
## 6.25.2 (2021-10-11)
### Bug Fixes
* Fix `DisableManualCompaction()` to cancel compactions even when they are waiting on automatic compactions to drain due to `CompactRangeOptions::exclusive_manual_compactions == true`.
* Fix contract of `Env::ReopenWritableFile()` and `FileSystem::ReopenWritableFile()` to specify any existing file must not be deleted or truncated.2021-10-15T21:13:42+00:00rocksdb v6.26.0rocksdb v6.26.02021-11-10T18:08:50+00:00## 6.26.0 (2021-10-20)
### Bug Fixes
* Fixes a bug in directed IO mode when calling MultiGet() for blobs in the same blob file. The bug is caused by not sorting the blob read requests by file offsets.
* Fix the incorrect disabling of SST rate limited deletion when the WAL and DB are in different directories. Only WAL rate limited deletion should be disabled if its in a different directory.
* Fix `DisableManualCompaction()` to cancel compactions even when they are waiting on automatic compactions to drain due to `CompactRangeOptions::exclusive_manual_compactions == true`.
* Fix contract of `Env::ReopenWritableFile()` and `FileSystem::ReopenWritableFile()` to specify any existing file must not be deleted or truncated.
* Fixed bug in calls to `IngestExternalFiles()` with files for multiple column families. The bug could have introduced a delay in ingested file keys becoming visible after `IngestExternalFiles()` returned. Furthermore, mutations to ingested file keys while they were invisible could have been dropped (not necessarily immediately).
* Fixed a possible race condition impacting users of `WriteBufferManager` who constructed it with `allow_stall == true`. The race condition led to undefined behavior (in our experience, typically a process crash).
* Fixed a bug where stalled writes would remain stalled forever after the user calls `WriteBufferManager::SetBufferSize()` with `new_size == 0` to dynamically disable memory limiting.
* Make `DB::close()` thread-safe.
* Fix a bug in atomic flush where one bg flush thread will wait forever for a preceding bg flush thread to commit its result to MANIFEST but encounters an error which is mapped to a soft error (DB not stopped).
### New Features
* Print information about blob files when using "ldb list_live_files_metadata"
* Provided support for SingleDelete with user defined timestamp.
* Experimental new function DB::GetLiveFilesStorageInfo offers essentially a unified version of other functions like GetLiveFiles, GetLiveFilesChecksumInfo, and GetSortedWalFiles. Checkpoints and backups could show small behavioral changes and/or improved performance as they now use this new API.
* Add remote compaction read/write bytes statistics: `REMOTE_COMPACT_READ_BYTES`, `REMOTE_COMPACT_WRITE_BYTES`.
* Introduce an experimental feature to dump out the blocks from block cache and insert them to the secondary cache to reduce the cache warmup time (e.g., used while migrating DB instance). More information are in `class CacheDumper` and `CacheDumpedLoader` at `rocksdb/utilities/cache_dump_load.h` Note that, this feature is subject to the potential change in the future, it is still experimental.
* Introduced a new BlobDB configuration option `blob_garbage_collection_force_threshold`, which can be used to trigger compactions targeting the SST files which reference the oldest blob files when the ratio of garbage in those blob files meets or exceeds the specified threshold. This can reduce space amplification with skewed workloads where the affected SST files might not otherwise get picked up for compaction.
* Added EXPERIMENTAL support for table file (SST) unique identifiers that are stable and universally unique, available with new function `GetUniqueIdFromTableProperties`. Only SST files from RocksDB >= 6.24 support unique IDs.
* Added `GetMapProperty()` support for "rocksdb.dbstats" (`DB::Properties::kDBStats`). As a map property, it includes DB-level internal stats accumulated over the DB's lifetime, such as user write related stats and uptime.
### Public API change
* Made SystemClock extend the Customizable class and added a CreateFromString method. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method.
* Made SliceTransform extend the Customizable class and added a CreateFromString method. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method. The Capped and Prefixed transform classes return a short name (no length); use GetId for the fully qualified name.
* Made FileChecksumGenFactory, SstPartitionerFactory, TablePropertiesCollectorFactory, and WalFilter extend the Customizable class and added a CreateFromString method.
* Some fields of SstFileMetaData are deprecated for compatibility with new base class FileStorageInfo.
* Add `file_temperature` to `IngestExternalFileArg` such that when ingesting SST files, we are able to indicate the temperature of the this batch of files.
* If `DB::Close()` failed with a non aborted status, calling `DB::Close()` again will return the original status instead of Status::OK.
* Add CacheTier to advanced_options.h to describe the cache tier we used. Add a `lowest_used_cache_tier` option to `DBOptions` (immutable) and pass it to BlockBasedTableReader. By default it is `CacheTier::kNonVolatileBlockTier`, which means, we always use both block cache (kVolatileTier) and secondary cache (kNonVolatileBlockTier). By set it to `CacheTier::kVolatileTier`, the DB will not use the secondary cache.
* Even when options.max_compaction_bytes is hit, compaction output files are only cut when it aligns with grandparent files' boundaries. options.max_compaction_bytes could be slightly violated with the change, but the violation is no more than one target SST file size, which is usually much smaller.
### Performance Improvements
* Improved CPU efficiency of building block-based table (SST) files (#9039 and #9040).
### Java API Changes
* Add Java API bindings for new integrated BlobDB options
* `keyMayExist()` supports ByteBuffer.
* Fix multiget throwing Null Pointer Exception for num of keys > 70k (https://github.com/facebook/rocksdb/issues/8039).2021-11-10T18:08:50+00:00rocksdb v6.26.1rocksdb v6.26.12021-11-18T22:47:43+00:00## 6.26.1 (2021-11-18)
### Bug Fixes
* Fix builds for some platforms.
## 6.26.0 (2021-10-20)
### Bug Fixes
* Fixes a bug in directed IO mode when calling MultiGet() for blobs in the same blob file. The bug is caused by not sorting the blob read requests by file offsets.
* Fix the incorrect disabling of SST rate limited deletion when the WAL and DB are in different directories. Only WAL rate limited deletion should be disabled if its in a different directory.
* Fix `DisableManualCompaction()` to cancel compactions even when they are waiting on automatic compactions to drain due to `CompactRangeOptions::exclusive_manual_compactions == true`.
* Fix contract of `Env::ReopenWritableFile()` and `FileSystem::ReopenWritableFile()` to specify any existing file must not be deleted or truncated.
* Fixed bug in calls to `IngestExternalFiles()` with files for multiple column families. The bug could have introduced a delay in ingested file keys becoming visible after `IngestExternalFiles()` returned. Furthermore, mutations to ingested file keys while they were invisible could have been dropped (not necessarily immediately).
* Fixed a possible race condition impacting users of `WriteBufferManager` who constructed it with `allow_stall == true`. The race condition led to undefined behavior (in our experience, typically a process crash).
* Fixed a bug where stalled writes would remain stalled forever after the user calls `WriteBufferManager::SetBufferSize()` with `new_size == 0` to dynamically disable memory limiting.
* Make `DB::close()` thread-safe.
* Fix a bug in atomic flush where one bg flush thread will wait forever for a preceding bg flush thread to commit its result to MANIFEST but encounters an error which is mapped to a soft error (DB not stopped).
### New Features
* Print information about blob files when using "ldb list_live_files_metadata"
* Provided support for SingleDelete with user defined timestamp.
* Experimental new function DB::GetLiveFilesStorageInfo offers essentially a unified version of other functions like GetLiveFiles, GetLiveFilesChecksumInfo, and GetSortedWalFiles. Checkpoints and backups could show small behavioral changes and/or improved performance as they now use this new API.
* Add remote compaction read/write bytes statistics: `REMOTE_COMPACT_READ_BYTES`, `REMOTE_COMPACT_WRITE_BYTES`.
* Introduce an experimental feature to dump out the blocks from block cache and insert them to the secondary cache to reduce the cache warmup time (e.g., used while migrating DB instance). More information are in `class CacheDumper` and `CacheDumpedLoader` at `rocksdb/utilities/cache_dump_load.h` Note that, this feature is subject to the potential change in the future, it is still experimental.
* Introduced a new BlobDB configuration option `blob_garbage_collection_force_threshold`, which can be used to trigger compactions targeting the SST files which reference the oldest blob files when the ratio of garbage in those blob files meets or exceeds the specified threshold. This can reduce space amplification with skewed workloads where the affected SST files might not otherwise get picked up for compaction.
* Added EXPERIMENTAL support for table file (SST) unique identifiers that are stable and universally unique, available with new function `GetUniqueIdFromTableProperties`. Only SST files from RocksDB >= 6.24 support unique IDs.
* Added `GetMapProperty()` support for "rocksdb.dbstats" (`DB::Properties::kDBStats`). As a map property, it includes DB-level internal stats accumulated over the DB's lifetime, such as user write related stats and uptime.
### Public API change
* Made SystemClock extend the Customizable class and added a CreateFromString method. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method.
* Made SliceTransform extend the Customizable class and added a CreateFromString method. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method. The Capped and Prefixed transform classes return a short name (no length); use GetId for the fully qualified name.
* Made FileChecksumGenFactory, SstPartitionerFactory, TablePropertiesCollectorFactory, and WalFilter extend the Customizable class and added a CreateFromString method.
* Some fields of SstFileMetaData are deprecated for compatibility with new base class FileStorageInfo.
* Add `file_temperature` to `IngestExternalFileArg` such that when ingesting SST files, we are able to indicate the temperature of the this batch of files.
* If `DB::Close()` failed with a non aborted status, calling `DB::Close()` again will return the original status instead of Status::OK.
* Add CacheTier to advanced_options.h to describe the cache tier we used. Add a `lowest_used_cache_tier` option to `DBOptions` (immutable) and pass it to BlockBasedTableReader. By default it is `CacheTier::kNonVolatileBlockTier`, which means, we always use both block cache (kVolatileTier) and secondary cache (kNonVolatileBlockTier). By set it to `CacheTier::kVolatileTier`, the DB will not use the secondary cache.
* Even when options.max_compaction_bytes is hit, compaction output files are only cut when it aligns with grandparent files' boundaries. options.max_compaction_bytes could be slightly violated with the change, but the violation is no more than one target SST file size, which is usually much smaller.
### Performance Improvements
* Improved CPU efficiency of building block-based table (SST) files (#9039 and #9040).
### Java API Changes
* Add Java API bindings for new integrated BlobDB options
* `keyMayExist()` supports ByteBuffer.
* Fix multiget throwing Null Pointer Exception for num of keys > 70k (https://github.com/facebook/rocksdb/issues/8039).2021-11-18T22:47:43+00:00rocksdb v6.27.3rocksdb v6.27.32021-12-20T18:59:42+00:00## 6.27.3 (2021-12-10)
### Bug Fixes
* Fixed a bug in TableOptions.prepopulate_block_cache which causes segmentation fault when used with TableOptions.partition_filters = true and TableOptions.cache_index_and_filter_blocks = true.
* Fixed a bug affecting custom memtable factories which are not registered with the `ObjectRegistry`. The bug could result in failure to save the OPTIONS file.
## 6.27.2 (2021-12-01)
### Bug Fixes
* Fixed a bug in rocksdb automatic implicit prefetching which got broken because of new feature adaptive_readahead and internal prefetching got disabled when iterator moves from one file to next.
## 6.27.1 (2021-11-29)
### Bug Fixes
* Fixed a bug that could, with WAL enabled, cause backups, checkpoints, and `GetSortedWalFiles()` to fail randomly with an error like `IO error: 001234.log: No such file or directory`
## 6.27.0 (2021-11-19)
### New Features
* Added new ChecksumType kXXH3 which is faster than kCRC32c on almost all x86\_64 hardware.
* Added a new online consistency check for BlobDB which validates that the number/total size of garbage blobs does not exceed the number/total size of all blobs in any given blob file.
* Provided support for tracking per-sst user-defined timestamp information in MANIFEST.
* Added new option "adaptive_readahead" in ReadOptions. For iterators, RocksDB does auto-readahead on noticing sequential reads and by enabling this option, readahead_size of current file (if reads are sequential) will be carried forward to next file instead of starting from the scratch at each level (except L0 level files). If reads are not sequential it will fall back to 8KB. This option is applicable only for RocksDB internal prefetch buffer and isn't supported with underlying file system prefetching.
* Added the read count and read bytes related stats to Statistics for tiered storage hot, warm, and cold file reads.
* Added an option to dynamically charge an updating estimated memory usage of block-based table building to block cache if block cache available. It currently only includes charging memory usage of constructing (new) Bloom Filter and Ribbon Filter to block cache. To enable this feature, set `BlockBasedTableOptions::reserve_table_builder_memory = true`.
* Add a new API OnIOError in listener.h that notifies listeners when an IO error occurs during FileSystem operation along with filename, status etc.
* Added compaction readahead support for blob files to the integrated BlobDB implementation, which can improve compaction performance when the database resides on higher-latency storage like HDDs or remote filesystems. Readahead can be configured using the column family option `blob_compaction_readahead_size`.
### Bug Fixes
* Prevent a `CompactRange()` with `CompactRangeOptions::change_level == true` from possibly causing corruption to the LSM state (overlapping files within a level) when run in parallel with another manual compaction. Note that setting `force_consistency_checks == true` (the default) would cause the DB to enter read-only mode in this scenario and return `Status::Corruption`, rather than committing any corruption.
* Fixed a bug in CompactionIterator when write-prepared transaction is used. A released earliest write conflict snapshot may cause assertion failure in dbg mode and unexpected key in opt mode.
* Fix ticker WRITE_WITH_WAL("rocksdb.write.wal"), this bug is caused by a bad extra `RecordTick(stats_, WRITE_WITH_WAL)` (at 2 place), this fix remove the extra `RecordTick`s and fix the corresponding test case.
* EventListener::OnTableFileCreated was previously called with OK status and file_size==0 in cases of no SST file contents written (because there was no content to add) and the empty file deleted before calling the listener. Now the status is Aborted.
* Fixed a bug in CompactionIterator when write-preared transaction is used. Releasing earliest_snapshot during compaction may cause a SingleDelete to be output after a PUT of the same user key whose seq has been zeroed.
* Added input sanitization on negative bytes passed into `GenericRateLimiter::Request`.
* Fixed an assertion failure in CompactionIterator when write-prepared transaction is used. We prove that certain operations can lead to a Delete being followed by a SingleDelete (same user key). We can drop the SingleDelete.
* Fixed a bug of timestamp-based GC which can cause all versions of a key under full_history_ts_low to be dropped. This bug will be triggered when some of the ikeys' timestamps are lower than full_history_ts_low, while others are newer.
* In some cases outside of the DB read and compaction paths, SST block checksums are now checked where they were not before.
* Explicitly check for and disallow the `BlockBasedTableOptions` if insertion into one of {`block_cache`, `block_cache_compressed`, `persistent_cache`} can show up in another of these. (RocksDB expects to be able to use the same key for different physical data among tiers.)
* Users who configured a dedicated thread pool for bottommost compactions by explicitly adding threads to the `Env::Priority::BOTTOM` pool will no longer see RocksDB schedule automatic compactions exceeding the DB's compaction concurrency limit. For details on per-DB compaction concurrency limit, see API docs of `max_background_compactions` and `max_background_jobs`.
* Fixed a bug of background flush thread picking more memtables to flush and prematurely advancing column family's log_number.
* Fixed an assertion failure in ManifestTailer.
### Behavior Changes
* `NUM_FILES_IN_SINGLE_COMPACTION` was only counting the first input level files, now it's including all input files.
* `TransactionUtil::CheckKeyForConflicts` can also perform conflict-checking based on user-defined timestamps in addition to sequence numbers.
* Removed `GenericRateLimiter`'s minimum refill bytes per period previously enforced.
### Public API change
* When options.ttl is used with leveled compaction with compactinon priority kMinOverlappingRatio, files exceeding half of TTL value will be prioritized more, so that by the time TTL is reached, fewer extra compactions will be scheduled to clear them up. At the same time, when compacting files with data older than half of TTL, output files may be cut off based on those files' boundaries, in order for the early TTL compaction to work properly.
* Made FileSystem extend the Customizable class and added a CreateFromString method. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method.
* Clarified in API comments that RocksDB is not exception safe for callbacks and custom extensions. An exception propagating into RocksDB can lead to undefined behavior, including data loss, unreported corruption, deadlocks, and more.
* Marked `WriteBufferManager` as `final` because it is not intended for extension.
* Removed unimportant implementation details from table_properties.h
* Add API `FSDirectory::FsyncWithDirOptions()`, which provides extra information like directory fsync reason in `DirFsyncOptions`. File system like btrfs is using that to skip directory fsync for creating a new file, or when renaming a file, fsync the target file instead of the directory, which improves the `DB::Open()` speed by ~20%.
* `DB::Open()` is not going be blocked by obsolete file purge if `DBOptions::avoid_unnecessary_blocking_io` is set to true.
* In builds where glibc provides `gettid()`, info log ("LOG" file) lines now print a system-wide thread ID from `gettid()` instead of the process-local `pthread_self()`. For all users, the thread ID format is changed from hexadecimal to decimal integer.
* In builds where glibc provides `pthread_setname_np()`, the background thread names no longer contain an ID suffix. For example, "rocksdb:bottom7" (and all other threads in the `Env::Priority::BOTTOM` pool) are now named "rocksdb:bottom". Previously large thread pools could breach the name size limit (e.g., naming "rocksdb:bottom10" would fail).
* Deprecating `ReadOptions::iter_start_seqnum` and `DBOptions::preserve_deletes`, please try using user defined timestamp feature instead. The options will be removed in a future release, currently it logs a warning message when using.
### Performance Improvements
* Released some memory related to filter construction earlier in `BlockBasedTableBuilder` for `FullFilter` and `PartitionedFilter` case (#9070)2021-12-20T18:59:42+00:00rocksdb v6.28.2rocksdb v6.28.22022-02-02T17:56:55+00:00## 6.28.2 (2022-01-31)
### Bug Fixes
* Fixed a major bug in which batched MultiGet could return old values for keys deleted by DeleteRange when memtable Bloom filter is enabled (memtable_prefix_bloom_size_ratio > 0). (The fix includes a substantial MultiGet performance improvement in the unusual case of both memtable_whole_key_filtering and prefix_extractor.)
## 6.28.1 (2022-01-10)
### Bug Fixes
* Fixed compilation errors on newer compiler, e.g. clang-12
## 6.28.0 (2021-12-17)
### New Features
* Introduced 'CommitWithTimestamp' as a new tag. Currently, there is no API for user to trigger a write with this tag to the WAL. This is part of the efforts to support write-commited transactions with user-defined timestamps.
### Bug Fixes
* Fixed a bug in rocksdb automatic implicit prefetching which got broken because of new feature adaptive_readahead and internal prefetching got disabled when iterator moves from one file to next.
* Fixed a bug in TableOptions.prepopulate_block_cache which causes segmentation fault when used with TableOptions.partition_filters = true and TableOptions.cache_index_and_filter_blocks = true.
* Fixed a bug affecting custom memtable factories which are not registered with the `ObjectRegistry`. The bug could result in failure to save the OPTIONS file.
* Fixed a bug causing two duplicate entries to be appended to a file opened in non-direct mode and tracked by `FaultInjectionTestFS`.
* Fixed a bug in TableOptions.prepopulate_block_cache to support block-based filters also.
* Block cache keys no longer use `FSRandomAccessFile::GetUniqueId()` (previously used when available), so a filesystem recycling unique ids can no longer lead to incorrect result or crash (#7405). For files generated by RocksDB >= 6.24, the cache keys are stable across DB::Open and DB directory move / copy / import / export / migration, etc. Although collisions are still theoretically possible, they are (a) impossible in many common cases, (b) not dependent on environmental factors, and (c) much less likely than a CPU miscalculation while executing RocksDB.
### Behavior Changes
* MemTableList::TrimHistory now use allocated bytes when max_write_buffer_size_to_maintain > 0(default in TrasactionDB, introduced in PR#5022) Fix #8371.
### Public API change
* Extend WriteBatch::AssignTimestamp and AssignTimestamps API so that both functions can accept an optional `checker` argument that performs additional checking on timestamp sizes.
* Introduce a new EventListener callback that will be called upon the end of automatic error recovery.
### Performance Improvements
* Replaced map property `TableProperties::properties_offsets` with uint64_t property `external_sst_file_global_seqno_offset` to save table properties's memory.
* Block cache accesses are faster by RocksDB using cache keys of fixed size (16 bytes).
### Java API Changes
* Removed Java API `TableProperties.getPropertiesOffsets()` as it exposed internal details to external users.2022-02-02T17:56:55+00:00rocksdb v6.29.3rocksdb v6.29.32022-02-18T21:04:08+00:00# Rocksdb Change Log
## 6.29.3 (02/17/2022)
### Bug Fixes
* Fix a data loss bug for 2PC write-committed transaction caused by concurrent transaction commit and memtable switch (#9571).
## 6.29.2 (02/15/2022)
### Performance Improvements
* DisableManualCompaction() doesn't have to wait scheduled manual compaction to be executed in thread-pool to cancel the job.
## 6.29.1 (01/31/2022)
### Bug Fixes
* Fixed a major bug in which batched MultiGet could return old values for keys deleted by DeleteRange when memtable Bloom filter is enabled (memtable_prefix_bloom_size_ratio > 0). (The fix includes a substantial MultiGet performance improvement in the unusual case of both memtable_whole_key_filtering and prefix_extractor.)
## 6.29.0 (01/21/2022)
Note: The next release will be major release 7.0. See https://github.com/facebook/rocksdb/issues/9390 for more info.
### Public API change
* Added values to `TraceFilterType`: `kTraceFilterIteratorSeek`, `kTraceFilterIteratorSeekForPrev`, and `kTraceFilterMultiGet`. They can be set in `TraceOptions` to filter out the operation types after which they are named.
* Added `TraceOptions::preserve_write_order`. When enabled it guarantees write records are traced in the same order they are logged to WAL and applied to the DB. By default it is disabled (false) to match the legacy behavior and prevent regression.
* Made the Env class extend the Customizable class. Implementations need to be registered with the ObjectRegistry and to implement a Name() method in order to be created via this method.
* `Options::OldDefaults` is marked deprecated, as it is no longer maintained.
* Add ObjectLibrary::AddFactory and ObjectLibrary::PatternEntry classes. This method and associated class are the preferred mechanism for registering factories with the ObjectLibrary going forward. The ObjectLibrary::Register method, which uses regular expressions and may be problematic, is deprecated and will be in a future release.
* Changed `BlockBasedTableOptions::block_size` from `size_t` to `uint64_t`.
* Added API warning against using `Iterator::Refresh()` together with `DB::DeleteRange()`, which are incompatible and have always risked causing the refreshed iterator to return incorrect results.
### Behavior Changes
* `DB::DestroyColumnFamilyHandle()` will return Status::InvalidArgument() if called with `DB::DefaultColumnFamily()`.
* On 32-bit platforms, mmap reads are no longer quietly disabled, just discouraged.
### New Features
* Added `Options::DisableExtraChecks()` that can be used to improve peak write performance by disabling checks that should not be necessary in the absence of software logic errors or CPU+memory hardware errors. (Default options are slowly moving toward some performance overheads for extra correctness checking.)
### Performance Improvements
* Improved read performance when a prefix extractor is used (Seek, Get, MultiGet), even compared to version 6.25 baseline (see bug fix below), by optimizing the common case of prefix extractor compatible with table file and unchanging.
### Bug Fixes
* Fix a bug that FlushMemTable may return ok even flush not succeed.
* Fixed a bug of Sync() and Fsync() not using `fcntl(F_FULLFSYNC)` on OS X and iOS.
* Fixed a significant performance regression in version 6.26 when a prefix extractor is used on the read path (Seek, Get, MultiGet). (Excessive time was spent in SliceTransform::AsString().)
### New Features
* Added RocksJava support for MacOS universal binary (ARM+x86)2022-02-18T21:04:08+00:00rocksdb v7.0.1rocksdb v7.0.12022-03-12T00:02:48+00:00# Rocksdb Change Log
## 7.0.1 (03/02/2022)
### Bug Fixes
* Fix a race condition when cancel manual compaction with `DisableManualCompaction`. Also DB close can cancel the manual compaction thread.
* Fixed a data race on `versions_` between `DBImpl::ResumeImpl()` and threads waiting for recovery to complete (#9496)
* Fixed a bug caused by race among flush, incoming writes and taking snapshots. Queries to snapshots created with these race condition can return incorrect result, e.g. resurfacing deleted data.
## 7.0.0 (02/20/2022)
### Bug Fixes
* Fixed a major bug in which batched MultiGet could return old values for keys deleted by DeleteRange when memtable Bloom filter is enabled (memtable_prefix_bloom_size_ratio > 0). (The fix includes a substantial MultiGet performance improvement in the unusual case of both memtable_whole_key_filtering and prefix_extractor.)
* Fixed more cases of EventListener::OnTableFileCreated called with OK status, file_size==0, and no SST file kept. Now the status is Aborted.
* Fixed a read-after-free bug in `DB::GetMergeOperands()`.
* Fix a data loss bug for 2PC write-committed transaction caused by concurrent transaction commit and memtable switch (#9571).
* Fixed NUM_INDEX_AND_FILTER_BLOCKS_READ_PER_LEVEL, NUM_DATA_BLOCKS_READ_PER_LEVEL, and NUM_SST_READ_PER_LEVEL stats to be reported once per MultiGet batch per level.
### Performance Improvements
* Mitigated the overhead of building the file location hash table used by the online LSM tree consistency checks, which can improve performance for certain workloads (see #9351).
* Switched to using a sorted `std::vector` instead of `std::map` for storing the metadata objects for blob files, which can improve performance for certain workloads, especially when the number of blob files is high.
* DisableManualCompaction() doesn't have to wait scheduled manual compaction to be executed in thread-pool to cancel the job.
### Public API changes
* Require C++17 compatible compiler (GCC >= 7, Clang >= 5, Visual Studio >= 2017) for compiling RocksDB and any code using RocksDB headers. See #9388.
* Added `ReadOptions::rate_limiter_priority`. When set to something other than `Env::IO_TOTAL`, the internal rate limiter (`DBOptions::rate_limiter`) will be charged at the specified priority for file reads associated with the API to which the `ReadOptions` was provided.
* Remove HDFS support from main repo.
* Remove librados support from main repo.
* Remove obsolete backupable_db.h and type alias `BackupableDBOptions`. Use backup_engine.h and `BackupEngineOptions`. Similar renamings are in the C and Java APIs.
* Removed obsolete utility_db.h and `UtilityDB::OpenTtlDB`. Use db_ttl.h and `DBWithTTL::Open`.
* Remove deprecated API DB::AddFile from main repo.
* Remove deprecated API ObjectLibrary::Register() and the (now obsolete) Regex public API. Use ObjectLibrary::AddFactory() with PatternEntry instead.
* Remove deprecated option DBOption::table_cache_remove_scan_count_limit.
* Remove deprecated API AdvancedColumnFamilyOptions::soft_rate_limit.
* Remove deprecated API AdvancedColumnFamilyOptions::hard_rate_limit.
* Remove deprecated API DBOption::base_background_compactions.
* Remove deprecated API DBOptions::purge_redundant_kvs_while_flush.
* Remove deprecated overloads of API DB::CompactRange.
* Remove deprecated option DBOptions::skip_log_error_on_recovery.
* Remove ReadOptions::iter_start_seqnum which has been deprecated.
* Remove DBOptions::preserved_deletes and DB::SetPreserveDeletesSequenceNumber().
* Remove deprecated API AdvancedColumnFamilyOptions::rate_limit_delay_max_milliseconds.
* Removed timestamp from WriteOptions. Accordingly, added to DB APIs Put, Delete, SingleDelete, etc. accepting an additional argument 'timestamp'. Added Put, Delete, SingleDelete, etc to WriteBatch accepting an additional argument 'timestamp'. Removed WriteBatch::AssignTimestamps(vector<Slice>) API. Renamed WriteBatch::AssignTimestamp() to WriteBatch::UpdateTimestamps() with clarified comments.
* Changed type of cache buffer passed to `Cache::CreateCallback` from `void*` to `const void*`.
* Significant updates to FilterPolicy-related APIs and configuration:
* Remove public API support for deprecated, inefficient block-based filter (use_block_based_builder=true).
* Old code and configuration strings that would enable it now quietly enable full filters instead, though any built-in FilterPolicy can still read block-based filters. This includes changing the longstanding default behavior of the Java API.
* Remove deprecated FilterPolicy::CreateFilter() and FilterPolicy::KeyMayMatch()
* Remove `rocksdb_filterpolicy_create()` from C API, as the only C API support for custom filter policies is now obsolete.
* If temporary memory usage in full filter creation is a problem, consider using partitioned filters, smaller SST files, or setting reserve_table_builder_memory=true.
* Remove support for "filter_policy=experimental_ribbon" configuration
string. Use something like "filter_policy=ribbonfilter:10" instead.
* Allow configuration string like "filter_policy=bloomfilter:10" without
bool, to minimize acknowledgement of obsolete block-based filter.
* Made FilterPolicy Customizable. Configuration of filter_policy is now accurately saved in OPTIONS file and can be loaded with LoadOptionsFromFile. (Loading an OPTIONS file generated by a previous version only enables reading and using existing filters, not generating new filters. Previously, no filter_policy would be configured from a saved OPTIONS file.)
* Change meaning of nullptr return from GetBuilderWithContext() from "use
block-based filter" to "generate no filter in this case."
* Also, when user specifies bits_per_key < 0.5, we now round this down
to "no filter" because we expect a filter with >= 80% FP rate is
unlikely to be worth the CPU cost of accessing it (esp with
cache_index_and_filter_blocks=1 or partition_filters=1).
* bits_per_key >= 0.5 and < 1.0 is still rounded up to 1.0 (for 62% FP
rate)
* Remove class definitions for FilterBitsBuilder and FilterBitsReader from
public API, so these can evolve more easily as implementation details.
Custom FilterPolicy can still decide what kind of built-in filter to use
under what conditions.
* Also removed deprecated functions
* FilterPolicy::GetFilterBitsBuilder()
* NewExperimentalRibbonFilterPolicy()
* Remove default implementations of
* FilterPolicy::GetBuilderWithContext()
* Remove default implementation of Name() from FileSystemWrapper.
* Rename `SizeApproximationOptions.include_memtabtles` to `SizeApproximationOptions.include_memtables`.
* Remove deprecated option DBOptions::max_mem_compaction_level.
* Return Status::InvalidArgument from ObjectRegistry::NewObject if a factory exists but the object ould not be created (returns NotFound if the factory is missing).
* Remove deprecated overloads of API DB::GetApproximateSizes.
* Remove deprecated option DBOptions::new_table_reader_for_compaction_inputs.
* Add Transaction::SetReadTimestampForValidation() and Transaction::SetCommitTimestamp(). Default impl returns NotSupported().
* Add support for decimal patterns to ObjectLibrary::PatternEntry
* Remove deprecated remote compaction APIs `CompactionService::Start()` and `CompactionService::WaitForComplete()`. Please use `CompactionService::StartV2()`, `CompactionService::WaitForCompleteV2()` instead, which provides the same information plus extra data like priority, db_id, etc.
* `ColumnFamilyOptions::OldDefaults` and `DBOptions::OldDefaults` are marked deprecated, as they are no longer maintained.
* Add subcompaction callback APIs: `OnSubcompactionBegin()` and `OnSubcompactionCompleted()`.
* Add file Temperature information to `FileOperationInfo` in event listener API.
* Change the type of SizeApproximationFlags from enum to enum class. Also update the signature of DB::GetApproximateSizes API from uint8_t to SizeApproximationFlags.
* Add Temperature hints information from RocksDB in API `NewSequentialFile()`. backup and checkpoint operations need to open the source files with `NewSequentialFile()`, which will have the temperature hints. Other operations are not covered.
### Behavior Changes
* Disallow the combination of DBOptions.use_direct_io_for_flush_and_compaction == true and DBOptions.writable_file_max_buffer_size == 0. This combination can cause WritableFileWriter::Append() to loop forever, and it does not make much sense in direct IO.
* `ReadOptions::total_order_seek` no longer affects `DB::Get()`. The original motivation for this interaction has been obsolete since RocksDB has been able to detect whether the current prefix extractor is compatible with that used to generate table files, probably RocksDB 5.14.0.
## New Features
* Introduced an option `BlockBasedTableOptions::detect_filter_construct_corruption` for detecting corruption during Bloom Filter (format_version >= 5) and Ribbon Filter construction.
* Improved the SstDumpTool to read the comparator from table properties and use it to read the SST File.
* Extended the column family statistics in the info log so the total amount of garbage in the blob files and the blob file space amplification factor are also logged. Also exposed the blob file space amp via the `rocksdb.blob-stats` DB property.
* Introduced the API rocksdb_create_dir_if_missing in c.h that calls underlying file system's CreateDirIfMissing API to create the directory.
* Added last level and non-last level read statistics: `LAST_LEVEL_READ_*`, `NON_LAST_LEVEL_READ_*`.
* Experimental: Add support for new APIs ReadAsync in FSRandomAccessFile that reads the data asynchronously and Poll API in FileSystem that checks if requested read request has completed or not. ReadAsync takes a callback function. Poll API checks for completion of read IO requests and should call callback functions to indicate completion of read requests.2022-03-12T00:02:48+00:00rocksdb v7.0.2rocksdb v7.0.22022-03-14T16:45:01+00:00# Rocksdb Change Log
## 7.0.2 (03/12/2022)
* Fixed a bug that DisableManualCompaction may assert when disable an unscheduled manual compaction.2022-03-14T16:45:01+00:00rocksdb v6.29.4rocksdb v6.29.42022-03-23T01:24:02+00:00## 6.29.4 (03/22/2022)
### Bug Fixes
* Fixed a bug caused by race among flush, incoming writes and taking snapshots. Queries to snapshots created with these race condition can return incorrect result, e.g. resurfacing deleted data.
* Fixed a bug that DisableManualCompaction may assert when disable an unscheduled manual compaction.
* Fixed a bug that `Iterator::Refresh()` reads stale keys after DeleteRange() performed.
* Fixed a race condition when disable and re-enable manual compaction.
* Fix a race condition when cancel manual compaction with `DisableManualCompaction`. Also DB close can cancel the manual compaction thread.
* Fixed a data race on `versions_` between `DBImpl::ResumeImpl()` and threads waiting for recovery to complete (#9496)
* Fixed a read-after-free bug in `DB::GetMergeOperands()`.
* Fixed NUM_INDEX_AND_FILTER_BLOCKS_READ_PER_LEVEL, NUM_DATA_BLOCKS_READ_PER_LEVEL, and NUM_SST_READ_PER_LEVEL stats to be reported once per MultiGet batch per level.2022-03-23T01:24:02+00:00rocksdb v7.0.3rocksdb v7.0.32022-03-25T17:00:11+00:00### Bug Fixes
* Fixed a major performance bug in which Bloom filters generated by pre-7.0 releases are not read by early 7.0.x releases (and vice-versa) due to changes to FilterPolicy::Name() in #9590. This can severely impact read performance and read I/O on upgrade or downgrade with existing DB, but not data correctness.
* Fixed a bug that `Iterator::Refresh()` reads stale keys after DeleteRange() performed.
### Public API changes
* Added pure virtual FilterPolicy::CompatibilityName(), which is needed for fixing major performance bug involving FilterPolicy naming in SST metadata without affecting Customizable aspect of FilterPolicy. For source code, this change only affects those with their own custom or wrapper FilterPolicy classes, but does break compiled library binary compatibility in a patch release.
2022-03-25T17:00:11+00:00rocksdb v6.29.5rocksdb v6.29.52022-03-29T20:30:03+00:00## 6.29.5 (03/29/2022)
### Bug Fixes
* Fixed a race condition for `alive_log_files_` in non-two-write-queues mode. The race is between the write_thread_ in WriteToWAL() and another thread executing `FindObsoleteFiles()`. The race condition will be caught if `__glibcxx_requires_nonempty` is enabled.
* Fixed a race condition when mmaping a WritableFile on POSIX.
* Fixed a race condition when 2PC is disabled and WAL tracking in the MANIFEST is enabled. The race condition is between two background flush threads trying to install flush results, causing a WAL deletion not tracked in the MANIFEST. A future DB open may fail.
* Fixed a heap use-after-free race with DropColumnFamily.
* Fixed a bug that `rocksdb.read.block.compaction.micros` cannot track compaction stats (#9722).2022-03-29T20:30:03+00:00rocksdb v7.0.4rocksdb v7.0.42022-03-29T20:31:07+00:00## 7.0.4 (03/29/2022)
### Bug Fixes
* Fixed a race condition when disable and re-enable manual compaction.
* Fixed a race condition for `alive_log_files_` in non-two-write-queues mode. The race is between the write_thread_ in WriteToWAL() and another thread executing `FindObsoleteFiles()`. The race condition will be caught if `__glibcxx_requires_nonempty` is enabled.
* Fixed a race condition when mmaping a WritableFile on POSIX.
* Fixed a race condition when 2PC is disabled and WAL tracking in the MANIFEST is enabled. The race condition is between two background flush threads trying to install flush results, causing a WAL deletion not tracked in the MANIFEST. A future DB open may fail.
* Fixed a heap use-after-free race with DropColumnFamily.
* Fixed a bug that `rocksdb.read.block.compaction.micros` cannot track compaction stats (#9722).2022-03-29T20:31:07+00:00rocksdb v7.1.1rocksdb v7.1.12022-04-13T21:20:40+00:00## 7.1.1 (04/07/2022)
### Bug Fixes
* Fix segfault in FilePrefetchBuffer with async_io as it doesn't wait for pending jobs to complete on destruction.
## 7.1.0 (03/23/2022)
### New Features
* Allow WriteBatchWithIndex to index a WriteBatch that includes keys with user-defined timestamps. The index itself does not have timestamp.
* Add support for user-defined timestamps to write-committed transaction without API change. The `TransactionDB` layer APIs do not allow timestamps because we require that all user-defined-timestamps-aware operations go through the `Transaction` APIs.
* Added BlobDB options to `ldb`
* `BlockBasedTableOptions::detect_filter_construct_corruption` can now be dynamically configured using `DB::SetOptions`.
* Automatically recover from retryable read IO errors during backgorund flush/compaction.
* Experimental support for preserving file Temperatures through backup and restore, and for updating DB metadata for outside changes to file Temperature (`UpdateManifestForFilesState` or `ldb update_manifest --update_temperatures`).
* Experimental support for async_io in ReadOptions which is used by FilePrefetchBuffer to prefetch some of the data asynchronously, if reads are sequential and auto readahead is enabled by rocksdb internally.
### Bug Fixes
* Fixed a major performance bug in which Bloom filters generated by pre-7.0 releases are not read by early 7.0.x releases (and vice-versa) due to changes to FilterPolicy::Name() in #9590. This can severely impact read performance and read I/O on upgrade or downgrade with existing DB, but not data correctness.
* Fixed a data race on `versions_` between `DBImpl::ResumeImpl()` and threads waiting for recovery to complete (#9496)
* Fixed a bug caused by race among flush, incoming writes and taking snapshots. Queries to snapshots created with these race condition can return incorrect result, e.g. resurfacing deleted data.
* Fixed a bug that DB flush uses `options.compression` even `options.compression_per_level` is set.
* Fixed a bug that DisableManualCompaction may assert when disable an unscheduled manual compaction.
* Fix a race condition when cancel manual compaction with `DisableManualCompaction`. Also DB close can cancel the manual compaction thread.
* Fixed a potential timer crash when open close DB concurrently.
* Fixed a race condition for `alive_log_files_` in non-two-write-queues mode. The race is between the write_thread_ in WriteToWAL() and another thread executing `FindObsoleteFiles()`. The race condition will be caught if `__glibcxx_requires_nonempty` is enabled.
* Fixed a bug that `Iterator::Refresh()` reads stale keys after DeleteRange() performed.
* Fixed a race condition when disable and re-enable manual compaction.
* Fixed automatic error recovery failure in atomic flush.
* Fixed a race condition when mmaping a WritableFile on POSIX.
### Public API changes
* Added pure virtual FilterPolicy::CompatibilityName(), which is needed for fixing major performance bug involving FilterPolicy naming in SST metadata without affecting Customizable aspect of FilterPolicy. This change only affects those with their own custom or wrapper FilterPolicy classes.
* `options.compression_per_level` is dynamically changeable with `SetOptions()`.
* Added `WriteOptions::rate_limiter_priority`. When set to something other than `Env::IO_TOTAL`, the internal rate limiter (`DBOptions::rate_limiter`) will be charged at the specified priority for writes associated with the API to which the `WriteOptions` was provided. Currently the support covers automatic WAL flushes, which happen during live updates (`Put()`, `Write()`, `Delete()`, etc.) when `WriteOptions::disableWAL == false` and `DBOptions::manual_wal_flush == false`.
* Add DB::OpenAndTrimHistory API. This API will open DB and trim data to the timestamp specified by trim_ts (The data with timestamp larger than specified trim bound will be removed). This API should only be used at a timestamp-enabled column families recovery. If the column family doesn't have timestamp enabled, this API won't trim any data on that column family. This API is not compatible with avoid_flush_during_recovery option.
* Remove BlockBasedTableOptions.hash_index_allow_collision which already takes no effect.2022-04-13T21:20:40+00:00rocksdb v7.1.2rocksdb v7.1.22022-04-20T01:48:15+00:00## 7.1.2 (04/19/2022)
### Bug Fixes
* Fixed bug which caused rocksdb failure in the situation when rocksdb was accessible using UNC path
* Fixed a race condition when 2PC is disabled and WAL tracking in the MANIFEST is enabled. The race condition is between two background flush threads trying to install flush results, causing a WAL deletion not tracked in the MANIFEST. A future DB open may fail.
* Fixed a heap use-after-free race with DropColumnFamily.
* Fixed a bug that `rocksdb.read.block.compaction.micros` cannot track compaction stats (#9722).
* Fixed `file_type`, `relative_filename` and `directory` fields returned by `GetLiveFilesMetaData()`, which were added in inheriting from `FileStorageInfo`.
* Fixed a bug affecting `track_and_verify_wals_in_manifest`. Without the fix, application may see "open error: Corruption: Missing WAL with log number" while trying to open the db. The corruption is a false alarm but prevents DB open (#9766).2022-04-20T01:48:15+00:00rocksdb v7.2.2rocksdb v7.2.22022-05-05T22:33:28+00:00## 7.2.2 (2022-04-28)
### Bug Fixes
* Fixed a bug in async_io path where incorrect length of data is read by FilePrefetchBuffer if data is consumed from two populated buffers and request for more data is sent.
## 7.2.1 (2022-04-26)
### Bug Fixes
* Fixed a bug where RocksDB could corrupt DBs with `avoid_flush_during_recovery == true` by removing valid WALs, leading to `Status::Corruption` with message like "SST file is ahead of WALs" when attempting to reopen.
* RocksDB calls FileSystem::Poll API during FilePrefetchBuffer destruction which impacts performance as it waits for read requets completion which is not needed anymore. Calling FileSystem::AbortIO to abort those requests instead fixes that performance issue.
## 7.2.0 (2022-04-15)
### Bug Fixes
* Fixed bug which caused rocksdb failure in the situation when rocksdb was accessible using UNC path
* Fixed a race condition when 2PC is disabled and WAL tracking in the MANIFEST is enabled. The race condition is between two background flush threads trying to install flush results, causing a WAL deletion not tracked in the MANIFEST. A future DB open may fail.
* Fixed a heap use-after-free race with DropColumnFamily.
* Fixed a bug that `rocksdb.read.block.compaction.micros` cannot track compaction stats (#9722).
* Fixed `file_type`, `relative_filename` and `directory` fields returned by `GetLiveFilesMetaData()`, which were added in inheriting from `FileStorageInfo`.
* Fixed a bug affecting `track_and_verify_wals_in_manifest`. Without the fix, application may see "open error: Corruption: Missing WAL with log number" while trying to open the db. The corruption is a false alarm but prevents DB open (#9766).
* Fix segfault in FilePrefetchBuffer with async_io as it doesn't wait for pending jobs to complete on destruction.
* Fix ERROR_HANDLER_AUTORESUME_RETRY_COUNT stat whose value was set wrong in portal.h
* Fixed a bug for non-TransactionDB with avoid_flush_during_recovery = true and TransactionDB where in case of crash, min_log_number_to_keep may not change on recovery and persisting a new MANIFEST with advanced log_numbers for some column families, results in "column family inconsistency" error on second recovery. As a solution the corrupted WALs whose numbers are larger than the corrupted wal and smaller than the new WAL will be moved to archive folder.
* Fixed a bug in RocksDB DB::Open() which may creates and writes to two new MANIFEST files even before recovery succeeds. Now writes to MANIFEST are persisted only after recovery is successful.
### New Features
* For db_bench when --seed=0 or --seed is not set then it uses the current time as the seed value. Previously it used the value 1000.
* For db_bench when --benchmark lists multiple tests and each test uses a seed for a RNG then the seeds across tests will no longer be repeated.
* Added an option to dynamically charge an updating estimated memory usage of block-based table reader to block cache if block cache available. To enable this feature, set `BlockBasedTableOptions::reserve_table_reader_memory = true`.
* Add new stat ASYNC_READ_BYTES that calculates number of bytes read during async read call and users can check if async code path is being called by RocksDB internal automatic prefetching for sequential reads.
* Enable async prefetching if ReadOptions.readahead_size is set along with ReadOptions.async_io in FilePrefetchBuffer.
* Add event listener support on remote compaction compactor side.
* Added a dedicated integer DB property `rocksdb.live-blob-file-garbage-size` that exposes the total amount of garbage in the blob files in the current version.
* RocksDB does internal auto prefetching if it notices sequential reads. It starts with readahead size `initial_auto_readahead_size` which now can be configured through BlockBasedTableOptions.
* Add a merge operator that allows users to register specific aggregation function so that they can does aggregation using different aggregation types for different keys. See comments in include/rocksdb/utilities/agg_merge.h for actual usage. The feature is experimental and the format is subject to change and we won't provide a migration tool.
* Meta-internal / Experimental: Improve CPU performance by replacing many uses of std::unordered_map with folly::F14FastMap when RocksDB is compiled together with Folly.
* Experimental: Add CompressedSecondaryCache, a concrete implementation of rocksdb::SecondaryCache, that integrates with compression libraries (e.g. LZ4) to hold compressed blocks.
### Behavior changes
* Disallow usage of commit-time-write-batch for write-prepared/write-unprepared transactions if TransactionOptions::use_only_the_last_commit_time_batch_for_recovery is false to prevent two (or more) uncommitted versions of the same key in the database. Otherwise, bottommost compaction may violate the internal key uniqueness invariant of SSTs if the sequence numbers of both internal keys are zeroed out (#9794).
* Make DB::GetUpdatesSince() return NotSupported early for write-prepared/write-unprepared transactions, as the API contract indicates.
### Public API changes
* Exposed APIs to examine results of block cache stats collections in a structured way. In particular, users of `GetMapProperty()` with property `kBlockCacheEntryStats` can now use the functions in `BlockCacheEntryStatsMapKeys` to find stats in the map.
* Add `fail_if_not_bottommost_level` to IngestExternalFileOptions so that ingestion will fail if the file(s) cannot be ingested to the bottommost level.
* Add output parameter `is_in_sec_cache` to `SecondaryCache::Lookup()`. It is to indicate whether the handle is possibly erased from the secondary cache after the Lookup.
2022-05-05T22:33:28+00:00rocksdb v7.3.1rocksdb v7.3.12022-06-10T23:08:05+00:00## 7.3.1 (06/08/2022)
### Bug Fixes
* Fix a bug in WAL tracking. Before this PR (#10087), calling `SyncWAL()` on the only WAL file of the db will not log the event in MANIFEST, thus allowing a subsequent `DB::Open` even if the WAL file is missing or corrupted.
* Fixed a bug for non-TransactionDB with avoid_flush_during_recovery = true and TransactionDB where in case of crash, min_log_number_to_keep may not change on recovery and persisting a new MANIFEST with advanced log_numbers for some column families, results in "column family inconsistency" error on second recovery. As a solution, RocksDB will persist the new MANIFEST after successfully syncing the new WAL. If a future recovery starts from the new MANIFEST, then it means the new WAL is successfully synced. Due to the sentinel empty write batch at the beginning, kPointInTimeRecovery of WAL is guaranteed to go after this point. If future recovery starts from the old MANIFEST, it means the writing the new MANIFEST failed. We won't have the "SST ahead of WAL" error.
* Fixed a bug where RocksDB DB::Open() may creates and writes to two new MANIFEST files even before recovery succeeds. Now writes to MANIFEST are persisted only after recovery is successful.
## 7.3.0 (05/20/2022)
### Bug Fixes
* Fixed a bug where manual flush would block forever even though flush options had wait=false.
* Fixed a bug where RocksDB could corrupt DBs with `avoid_flush_during_recovery == true` by removing valid WALs, leading to `Status::Corruption` with message like "SST file is ahead of WALs" when attempting to reopen.
* Fixed a bug in async_io path where incorrect length of data is read by FilePrefetchBuffer if data is consumed from two populated buffers and request for more data is sent.
* Fixed a CompactionFilter bug. Compaction filter used to use `Delete` to remove keys, even if the keys should be removed with `SingleDelete`. Mixing `Delete` and `SingleDelete` may cause undefined behavior.
* Fixed a bug in `WritableFileWriter::WriteDirect` and `WritableFileWriter::WriteDirectWithChecksum`. The rate_limiter_priority specified in ReadOptions was not passed to the RateLimiter when requesting a token.
* Fixed a bug which might cause process crash when I/O error happens when reading an index block in MultiGet().
### New Features
* DB::GetLiveFilesStorageInfo is ready for production use.
* Add new stats PREFETCHED_BYTES_DISCARDED which records number of prefetched bytes discarded by RocksDB FilePrefetchBuffer on destruction and POLL_WAIT_MICROS records wait time for FS::Poll API completion.
* RemoteCompaction supports table_properties_collector_factories override on compaction worker.
* Start tracking SST unique id in MANIFEST, which will be used to verify with SST properties during DB open to make sure the SST file is not overwritten or misplaced. A db option `verify_sst_unique_id_in_manifest` is introduced to enable/disable the verification, if enabled all SST files will be opened during DB-open to verify the unique id (default is false), so it's recommended to use it with `max_open_files = -1` to pre-open the files.
* Added the ability to concurrently read data blocks from multiple files in a level in batched MultiGet. This can be enabled by setting the async_io option in ReadOptions. Using this feature requires a FileSystem that supports ReadAsync (PosixFileSystem is not supported yet for this), and for RocksDB to be compiled with folly and c++20.
* Add FileSystem::ReadAsync API in io_tracing.
### Public API changes
* Add rollback_deletion_type_callback to TransactionDBOptions so that write-prepared transactions know whether to issue a Delete or SingleDelete to cancel a previous key written during prior prepare phase. The PR aims to prevent mixing SingleDeletes and Deletes for the same key that can lead to undefined behaviors for write-prepared transactions.
* EXPERIMENTAL: Add new API AbortIO in file_system to abort the read requests submitted asynchronously.
* CompactionFilter::Decision has a new value: kRemoveWithSingleDelete. If CompactionFilter returns this decision, then CompactionIterator will use `SingleDelete` to mark a key as removed.
* Renamed CompactionFilter::Decision::kRemoveWithSingleDelete to kPurge since the latter sounds more general and hides the implementation details of how compaction iterator handles keys.
* Added ability to specify functions for Prepare and Validate to OptionsTypeInfo. Added methods to OptionTypeInfo to set the functions via an API. These methods are intended for RocksDB plugin developers for configuration management.
* Added a new immutable db options, enforce_single_del_contracts. If set to false (default is true), compaction will NOT fail due to a single delete followed by a delete for the same key. The purpose of this temporay option is to help existing use cases migrate.
* Introduce `BlockBasedTableOptions::cache_usage_options` and use that to replace `BlockBasedTableOptions::reserve_table_builder_memory` and `BlockBasedTableOptions::reserve_table_reader_memory`.
* Changed `GetUniqueIdFromTableProperties` to return a 128-bit unique identifier, which will be the standard size now. The old functionality (192-bit) is available from `GetExtendedUniqueIdFromTableProperties`. Both functions are no longer "experimental" and are ready for production use.
* In IOOptions, mark `prio` as deprecated for future removal.
* In `file_system.h`, mark `IOPriority` as deprecated for future removal.
* Add an option, `CompressionOptions::use_zstd_dict_trainer`, to indicate whether zstd dictionary trainer should be used for generating zstd compression dictionaries. The default value of this option is true for backward compatibility. When this option is set to false, zstd API `ZDICT_finalizeDictionary` is used to generate compression dictionaries.
* Seek API which positions itself every LevelIterator on the correct data block in the correct SST file which can be parallelized if ReadOptions.async_io option is enabled.
* Add new stat number_async_seek in PerfContext that indicates number of async calls made by seek to prefetch data.
### Bug Fixes
* RocksDB calls FileSystem::Poll API during FilePrefetchBuffer destruction which impacts performance as it waits for read requets completion which is not needed anymore. Calling FileSystem::AbortIO to abort those requests instead fixes that performance issue.
* Fixed unnecessary block cache contention when queries within a MultiGet batch and across parallel batches access the same data block, which previously could cause severely degraded performance in this unusual case. (In more typical MultiGet cases, this fix is expected to yield a small or negligible performance improvement.)
### Behavior changes
* Enforce the existing contract of SingleDelete so that SingleDelete cannot be mixed with Delete because it leads to undefined behavior. Fix a number of unit tests that violate the contract but happen to pass.
* ldb `--try_load_options` default to true if `--db` is specified and not creating a new DB, the user can still explicitly disable that by `--try_load_options=false` (or explicitly enable that by `--try_load_options`).
* During Flush write or Compaction write/read, the WriteController is used to determine whether DB writes are stalled or slowed down. The priority (Env::IOPriority) can then be determined accordingly and be passed in IOOptions to the file system.
2022-06-10T23:08:05+00:00rocksdb v7.4.3rocksdb v7.4.32022-07-18T15:18:20+00:00## 7.4.3 (07/13/2022)
### Behavior Changes
* For track_and_verify_wals_in_manifest, revert to the original behavior before #10087: syncing of live WAL file is not tracked, and we track only the synced sizes of **closed** WALs. (PR #10330).
## 7.4.2 (06/30/2022)
### Bug Fixes
* Fix a bug in Logger where if dbname and db_log_dir are on different filesystems, dbname creation would fail wrt to db_log_dir path returning an error and fails to open the DB.
## 7.4.1 (06/28/2022)
### Bug Fixes
* Pass `rate_limiter_priority` through filter block reader functions to `FileSystem`.
## 7.4.0 (06/19/2022)
### Bug Fixes
* Fixed a bug in calculating key-value integrity protection for users of in-place memtable updates. In particular, the affected users would be those who configure `protection_bytes_per_key > 0` on `WriteBatch` or `WriteOptions`, and configure `inplace_callback != nullptr`.
* Fixed a bug where a snapshot taken during SST file ingestion would be unstable.
* Fixed a bug for non-TransactionDB with avoid_flush_during_recovery = true and TransactionDB where in case of crash, min_log_number_to_keep may not change on recovery and persisting a new MANIFEST with advanced log_numbers for some column families, results in "column family inconsistency" error on second recovery. As a solution, RocksDB will persist the new MANIFEST after successfully syncing the new WAL. If a future recovery starts from the new MANIFEST, then it means the new WAL is successfully synced. Due to the sentinel empty write batch at the beginning, kPointInTimeRecovery of WAL is guaranteed to go after this point. If future recovery starts from the old MANIFEST, it means the writing the new MANIFEST failed. We won't have the "SST ahead of WAL" error.
* Fixed a bug where RocksDB DB::Open() may creates and writes to two new MANIFEST files even before recovery succeeds. Now writes to MANIFEST are persisted only after recovery is successful.
* Fix a race condition in WAL size tracking which is caused by an unsafe iterator access after container is changed.
* Fix unprotected concurrent accesses to `WritableFileWriter::filesize_` by `DB::SyncWAL()` and `DB::Put()` in two write queue mode.
* Fix a bug in WAL tracking. Before this PR (#10087), calling `SyncWAL()` on the only WAL file of the db will not log the event in MANIFEST, thus allowing a subsequent `DB::Open` even if the WAL file is missing or corrupted.
* Fix a bug that could return wrong results with `index_type=kHashSearch` and using `SetOptions` to change the `prefix_extractor`.
* Fixed a bug in WAL tracking with wal_compression. WAL compression writes a kSetCompressionType record which is not associated with any sequence number. As result, WalManager::GetSortedWalsOfType() will skip these WALs and not return them to caller, e.g. Checkpoint, Backup, causing the operations to fail.
* Avoid a crash if the IDENTITY file is accidentally truncated to empty. A new DB ID will be written and generated on Open.
* Fixed a possible corruption for users of `manual_wal_flush` and/or `FlushWAL(true /* sync */)`, together with `track_and_verify_wals_in_manifest == true`. For those users, losing unsynced data (e.g., due to power loss) could make future DB opens fail with a `Status::Corruption` complaining about missing WAL data.
* Fixed a bug in `WriteBatchInternal::Append()` where WAL termination point in write batch was not considered and the function appends an incorrect number of checksums.
* Fixed a crash bug introduced in 7.3.0 affecting users of MultiGet with `kDataBlockBinaryAndHash`.
* Add some fixes in async_io which was doing extra prefetching in shorter scans.
### Public API changes
* Add new API GetUnixTime in Snapshot class which returns the unix time at which Snapshot is taken.
* Add transaction `get_pinned` and `multi_get` to C API.
* Add two-phase commit support to C API.
* Add `rocksdb_transaction_get_writebatch_wi` and `rocksdb_transaction_rebuild_from_writebatch` to C API.
* Add `rocksdb_options_get_blob_file_starting_level` and `rocksdb_options_set_blob_file_starting_level` to C API.
* Add `blobFileStartingLevel` and `setBlobFileStartingLevel` to Java API.
* Add SingleDelete for DB in C API
* Add User Defined Timestamp in C API.
* `rocksdb_comparator_with_ts_create` to create timestamp aware comparator
* Put, Get, Delete, SingleDelete, MultiGet APIs has corresponding timestamp aware APIs with suffix `with_ts`
* And Add C API's for Transaction, SstFileWriter, Compaction as mentioned [here](https://github.com/facebook/rocksdb/wiki/User-defined-Timestamp-(Experimental))
* The contract for implementations of Comparator::IsSameLengthImmediateSuccessor has been updated to work around a design bug in `auto_prefix_mode`.
* The API documentation for `auto_prefix_mode` now notes some corner cases in which it returns different results than `total_order_seek`, due to design bugs that are not easily fixed. Users using built-in comparators and keys at least the size of a fixed prefix length are not affected.
* Obsoleted the NUM_DATA_BLOCKS_READ_PER_LEVEL stat and introduced the NUM_LEVEL_READ_PER_MULTIGET and MULTIGET_COROUTINE_COUNT stats
* Introduced `WriteOptions::protection_bytes_per_key`, which can be used to enable key-value integrity protection for live updates.
### New Features
* Add FileSystem::ReadAsync API in io_tracing
* Add blob garbage collection parameters `blob_garbage_collection_policy` and `blob_garbage_collection_age_cutoff` to both force-enable and force-disable GC, as well as selectively override age cutoff when using CompactRange.
* Add an extra sanity check in `GetSortedWalFiles()` (also used by `GetLiveFilesStorageInfo()`, `BackupEngine`, and `Checkpoint`) to reduce risk of successfully created backup or checkpoint failing to open because of missing WAL file.
* Add a new column family option `blob_file_starting_level` to enable writing blob files during flushes and compactions starting from the specified LSM tree level.
* Add support for timestamped snapshots (#9879)
* Provide support for AbortIO in posix to cancel submitted asynchronous requests using io_uring.
* Add support for rate-limiting batched `MultiGet()` APIs
### Behavior changes
* DB::Open(), DB::OpenAsSecondary() will fail if a Logger cannot be created (#9984)
* Removed support for reading Bloom filters using obsolete block-based filter format. (Support for writing such filters was dropped in 7.0.) For good read performance on old DBs using these filters, a full compaction is required.
* Per KV checksum in write batch is verified before a write batch is written to WAL to detect any corruption to the write batch (#10114).
### Performance Improvements
* When compiled with folly (Meta-internal integration; experimental in open source build), improve the locking performance (CPU efficiency) of LRUCache by using folly DistributedMutex in place of standard mutex.
2022-07-18T15:18:20+00:00rocksdb v7.4.4rocksdb v7.4.42022-07-28T18:34:26+00:00## 7.4.4 (07/19/2022)
### Public API changes
* Removed Customizable support for RateLimiter and removed its CreateFromString() and Type() functions.
### Bug Fixes
* Fix a bug where `GenericRateLimiter` could revert the bandwidth set dynamically using `SetBytesPerSecond()` when a user configures a structure enclosing it, e.g., using `GetOptionsFromString()` to configure an `Options` that references an existing `RateLimiter` object.2022-07-28T18:34:26+00:00rocksdb v7.4.5rocksdb v7.4.52022-08-02T23:17:54+00:00## 7.4.5 (08/02/2022)
### Bug Fixes
* Fix a bug starting in 7.4.0 in which some fsync operations might be skipped in a DB after any DropColumnFamily on that DB, until it is re-opened. This can lead to data loss on power loss. (For custom FileSystem implementations, this could lead to `FSDirectory::Fsync` or `FSDirectory::Close` after the first `FSDirectory::Close`; Also, valgrind could report call to `close()` with `fd=-1`.)2022-08-02T23:17:54+00:00rocksdb v7.5.3rocksdb v7.5.32022-08-24T22:39:19+00:00## 7.5.2 (08/02/2022)
### Bug Fixes
* Fix a bug starting in 7.4.0 in which some fsync operations might be skipped in a DB after any DropColumnFamily on that DB, until it is re-opened. This can lead to data loss on power loss. (For custom FileSystem implementations, this could lead to `FSDirectory::Fsync` or `FSDirectory::Close` after the first `FSDirectory::Close`; Also, valgrind could report call to `close()` with `fd=-1`.)
## 7.5.1 (08/01/2022)
### Bug Fixes
* Fix a bug where rate_limiter_parameter is not passed into `PartitionedFilterBlockReader::GetFilterPartitionBlock`.
## 7.5.0 (07/15/2022)
### New Features
* Mempurge option flag `experimental_mempurge_threshold` is now a ColumnFamilyOptions and can now be dynamically configured using `SetOptions()`.
* Support backward iteration when `ReadOptions::iter_start_ts` is set.
* Provide support for ReadOptions.async_io with direct_io to improve Seek latency by using async IO to parallelize child iterator seek and doing asynchronous prefetching on sequential scans.
* Added support for blob caching in order to cache frequently used blobs for BlobDB.
* User can configure the new ColumnFamilyOptions `blob_cache` to enable/disable blob caching.
* Either sharing the backend cache with the block cache or using a completely separate cache is supported.
* A new abstraction interface called `BlobSource` for blob read logic gives all users access to blobs, whether they are in the blob cache, secondary cache, or (remote) storage. Blobs can be potentially read both while handling user reads (`Get`, `MultiGet`, or iterator) and during compaction (while dealing with compaction filters, Merges, or garbage collection) but eventually all blob reads go through `Version::GetBlob` or, for MultiGet, `Version::MultiGetBlob` (and then get dispatched to the interface -- `BlobSource`).
* Add experimental tiered compaction feature `AdvancedColumnFamilyOptions::preclude_last_level_data_seconds`, which makes sure the new data inserted within preclude_last_level_data_seconds won't be placed on cold tier (the feature is not complete).
### Public API changes
* Add metadata related structs and functions in C API, including
* `rocksdb_get_column_family_metadata()` and `rocksdb_get_column_family_metadata_cf()` to obtain `rocksdb_column_family_metadata_t`.
* `rocksdb_column_family_metadata_t` and its get functions & destroy function.
* `rocksdb_level_metadata_t` and its and its get functions & destroy function.
* `rocksdb_file_metadata_t` and its and get functions & destroy functions.
* Add suggest_compact_range() and suggest_compact_range_cf() to C API.
* When using block cache strict capacity limit (`LRUCache` with `strict_capacity_limit=true`), DB operations now fail with Status code `kAborted` subcode `kMemoryLimit` (`IsMemoryLimit()`) instead of `kIncomplete` (`IsIncomplete()`) when the capacity limit is reached, because Incomplete can mean other specific things for some operations. In more detail, `Cache::Insert()` now returns the updated Status code and this usually propagates through RocksDB to the user on failure.
* NewClockCache calls temporarily return an LRUCache (with similar characteristics as the desired ClockCache). This is because ClockCache is being replaced by a new version (the old one had unknown bugs) but this is still under development.
* Add two functions `int ReserveThreads(int threads_to_be_reserved)` and `int ReleaseThreads(threads_to_be_released)` into `Env` class. In the default implementation, both return 0. Newly added `xxxEnv` class that inherits `Env` should implement these two functions for thread reservation/releasing features.
* Removed Customizable support for RateLimiter and removed its CreateFromString() and Type() functions.
### Bug Fixes
* Fix a bug in which backup/checkpoint can include a WAL deleted by RocksDB.
* Fix a bug where concurrent compactions might cause unnecessary further write stalling. In some cases, this might cause write rate to drop to minimum.
* Fix a bug in Logger where if dbname and db_log_dir are on different filesystems, dbname creation would fail wrt to db_log_dir path returning an error and fails to open the DB.
* Fix a CPU and memory efficiency issue introduce by https://github.com/facebook/rocksdb/pull/8336 which made InternalKeyComparator configurable as an unintended side effect
* Fix a bug where `GenericRateLimiter` could revert the bandwidth set dynamically using `SetBytesPerSecond()` when a user configures a structure enclosing it, e.g., using `GetOptionsFromString()` to configure an `Options` that references an existing `RateLimiter` object.
## Behavior Change
* In leveled compaction with dynamic levelling, level multiplier is not anymore adjusted due to oversized L0. Instead, compaction score is adjusted by increasing size level target by adding incoming bytes from upper levels. This would deprioritize compactions from upper levels if more data from L0 is coming. This is to fix some unnecessary full stalling due to drastic change of level targets, while not wasting write bandwidth for compaction while writes are overloaded.
* For track_and_verify_wals_in_manifest, revert to the original behavior before #10087: syncing of live WAL file is not tracked, and we track only the synced sizes of **closed** WALs. (PR #10330).
* WAL compression now computes/verifies checksum during compression/decompression.
### Performance Improvements
* Rather than doing total sort against all files in a level, SortFileByOverlappingRatio() to only find the top 50 files based on score. This can improve write throughput for the use cases where data is loaded in increasing key order and there are a lot of files in one LSM-tree, where applying compaction results is the bottleneck.
* In leveled compaction, L0->L1 trivial move will allow more than one file to be moved in one compaction. This would allow L0 files to be moved down faster when data is loaded in sequential order, making slowdown or stop condition harder to hit. Also seek L0->L1 trivial move when only some files qualify.
* In leveled compaction, try to trivial move more than one files if possible, up to 4 files or max_compaction_bytes. This is to allow higher write throughput for some use cases where data is loaded in sequential order, where appying compaction results is the bottleneck.2022-08-24T22:39:19+00:00rocksdb v7.6.0rocksdb v7.6.02022-09-20T19:20:37+00:00### New Features
* Added `prepopulate_blob_cache` to ColumnFamilyOptions. If enabled, prepopulate warm/hot blobs which are already in memory into blob cache at the time of flush. On a flush, the blob that is in memory (in memtables) get flushed to the device. If using Direct IO, additional IO is incurred to read this blob back into memory again, which is avoided by enabling this option. This further helps if the workload exhibits high temporal locality, where most of the reads go to recently written data. This also helps in case of the remote file system since it involves network traffic and higher latencies.
* Support using secondary cache with the blob cache. When creating a blob cache, the user can set a secondary blob cache by configuring `secondary_cache` in LRUCacheOptions.
* Charge memory usage of blob cache when the backing cache of the blob cache and the block cache are different. If an operation reserving memory for blob cache exceeds the avaible space left in the block cache at some point (i.e, causing a cache full under `LRUCacheOptions::strict_capacity_limit` = true), creation will fail with `Status::MemoryLimit()`. To opt in this feature, enable charging `CacheEntryRole::kBlobCache` in `BlockBasedTableOptions::cache_usage_options`.
* Improve subcompaction range partition so that it is likely to be more even. More evenly distribution of subcompaction will improve compaction throughput for some workloads. All input files' index blocks to sample some anchor key points from which we pick positions to partition the input range. This would introduce some CPU overhead in compaction preparation phase, if subcompaction is enabled, but it should be a small fraction of the CPU usage of the whole compaction process. This also brings a behavier change: subcompaction number is much more likely to maxed out than before.
* Add CompactionPri::kRoundRobin, a compaction picking mode that cycles through all the files with a compact cursor in a round-robin manner. This feature is available since 7.5.
* Provide support for subcompactions for user_defined_timestamp.
* Added an option `memtable_protection_bytes_per_key` that turns on memtable per key-value checksum protection. Each memtable entry will be suffixed by a checksum that is computed during writes, and verified in reads/compaction. Detected corruption will be logged and with corruption status returned to user.
* Added a blob-specific cache priority level - bottom level. Blobs are typically lower-value targets for caching than data blocks, since 1) with BlobDB, data blocks containing blob references conceptually form an index structure which has to be consulted before we can read the blob value, and 2) cached blobs represent only a single key-value, while cached data blocks generally contain multiple KVs. The user can specify the new option `low_pri_pool_ratio` in `LRUCacheOptions` to configure the ratio of capacity reserved for low priority cache entries (and therefore the remaining ratio is the space reserved for the bottom level), or configuring the new argument `low_pri_pool_ratio` in `NewLRUCache()` to achieve the same effect.
### Public API changes
* Removed Customizable support for RateLimiter and removed its CreateFromString() and Type() functions.
* `CompactRangeOptions::exclusive_manual_compaction` is now false by default. This ensures RocksDB does not introduce artificial parallelism limitations by default.
* Tiered Storage: change `bottommost_temperture` to `last_level_temperture`. The old option name is kept only for migration, please use the new option. The behavior is changed to apply temperature for the `last_level` SST files only.
* Added a new experimental ReadOption flag called optimize_multiget_for_io, which when set attempts to reduce MultiGet latency by spawning coroutines for keys in multiple levels.
### Bug Fixes
* Fix a bug starting in 7.4.0 in which some fsync operations might be skipped in a DB after any DropColumnFamily on that DB, until it is re-opened. This can lead to data loss on power loss. (For custom FileSystem implementations, this could lead to `FSDirectory::Fsync` or `FSDirectory::Close` after the first `FSDirectory::Close`; Also, valgrind could report call to `close()` with `fd=-1`.)
* Fix a bug where `GenericRateLimiter` could revert the bandwidth set dynamically using `SetBytesPerSecond()` when a user configures a structure enclosing it, e.g., using `GetOptionsFromString()` to configure an `Options` that references an existing `RateLimiter` object.
* Fix race conditions in `GenericRateLimiter`.
* Fix a bug in `FIFOCompactionPicker::PickTTLCompaction` where total_size calculating might cause underflow
* Fix data race bug in hash linked list memtable. With this bug, read request might temporarily miss an old record in the memtable in a race condition to the hash bucket.
* Fix a bug that `best_efforts_recovery` may fail to open the db with mmap read.
* Fixed a bug where blobs read during compaction would pollute the cache.
* Fixed a data race in LRUCache when used with a secondary_cache.
* Fixed a bug where blobs read by iterators would be inserted into the cache even with the `fill_cache` read option set to false.
* Fixed the segfault caused by `AllocateData()` in `CompressedSecondaryCache::SplitValueIntoChunks()` and `MergeChunksIntoValueTest`.
* Fixed a bug in BlobDB where a mix of inlined and blob values could result in an incorrect value being passed to the compaction filter (see #10391).
* Fixed a memory leak bug in stress tests caused by `FaultInjectionSecondaryCache`.
### Behavior Change
* Added checksum handshake during the copying of decompressed WAL fragment. This together with #9875, #10037, #10212, #10114 and #10319 provides end-to-end integrity protection for write batch during recovery.
* To minimize the internal fragmentation caused by the variable size of the compressed blocks in `CompressedSecondaryCache`, the original block is split according to the jemalloc bin size in `Insert()` and then merged back in `Lookup()`.
* PosixLogger is removed and by default EnvLogger will be used for info logging. The behavior of the two loggers should be very similar when using the default Posix Env.
* Remove [min|max]_timestamp from VersionEdit for now since they are not tracked in MANIFEST anyway but consume two empty std::string (up to 64 bytes) for each file. Should they be added back in the future, we should store them more compactly.
* Improve universal tiered storage compaction picker to avoid extra major compaction triggered by size amplification. If `preclude_last_level_data_seconds` is enabled, the size amplification is calculated within non last_level data only which skip the last level and use the penultimate level as the size base.
* If an error is hit when writing to a file (append, sync, etc), RocksDB is more strict with not issuing more operations to it, except closing the file, with exceptions of some WAL file operations in error recovery path.
* A `WriteBufferManager` constructed with `allow_stall == false` will no longer trigger write stall implicitly by thrashing until memtable count limit is reached. Instead, a column family can continue accumulating writes while that CF is flushing, which means memory may increase. Users who prefer stalling writes must now explicitly set `allow_stall == true`.
* Add `CompressedSecondaryCache` into the stress tests.
* Block cache keys have changed, which will cause any persistent caches to miss between versions.
### Performance Improvements
* Instead of constructing `FragmentedRangeTombstoneList` during every read operation, it is now constructed once and stored in immutable memtables. This improves speed of querying range tombstones from immutable memtables.
* When using iterators with the integrated BlobDB implementation, blob cache handles are now released immediately when the iterator's position changes.
* MultiGet can now do more IO in parallel by reading data blocks from SST files in multiple levels, if the optimize_multiget_for_io ReadOption flag is set.2022-09-20T19:20:37+00:00rocksdb v7.7.2rocksdb v7.7.22022-10-07T16:28:46+00:00## 7.7.2 (10/05/2022)
### Bug Fixes
* Fixed a bug in iterator refresh that was not freeing up SuperVersion, which could cause excessive resource pinniung (#10770).
* Fixed a bug where RocksDB could be doing compaction endlessly when allow_ingest_behind is true and the bottommost level is not filled (#10767).
### Behavior Changes
* Sanitize min_write_buffer_number_to_merge to 1 if atomic flush is enabled to prevent unexpected data loss when WAL is disabled in a multi-column-family setting (#10773).
## 7.7.1 (09/26/2022)
### Bug Fixes
* Fixed an optimistic transaction validation bug caused by DBImpl::GetLatestSequenceForKey() returning non-latest seq for merge (#10724).
* Fixed a bug in iterator refresh which could segfault for DeleteRange users (#10739).
## 7.7.0 (09/18/2022)
### Bug Fixes
* Fixed a hang when an operation such as `GetLiveFiles` or `CreateNewBackup` is asked to trigger and wait for memtable flush on a read-only DB. Such indirect requests for memtable flush are now ignored on a read-only DB.
* Fixed bug where `FlushWAL(true /* sync */)` (used by `GetLiveFilesStorageInfo()`, which is used by checkpoint and backup) could cause parallel writes at the tail of a WAL file to never be synced.
* Fix periodic_task unable to re-register the same task type, which may cause `SetOptions()` fail to update periodical_task time like: `stats_dump_period_sec`, `stats_persist_period_sec`.
* Fixed a bug in the rocksdb.prefetched.bytes.discarded stat. It was counting the prefetch buffer size, rather than the actual number of bytes discarded from the buffer.
* Fix bug where the directory containing CURRENT can left unsynced after CURRENT is updated to point to the latest MANIFEST, which leads to risk of unsync data loss of CURRENT.
* Update rocksdb.multiget.io.batch.size stat in non-async MultiGet as well.
* Fix a bug in key range overlap checking with concurrent compactions when user-defined timestamp is enabled. User-defined timestamps should be EXCLUDED when checking if two ranges overlap.
* Fixed a bug where the blob cache prepopulating logic did not consider the secondary cache (see #10603).
* Fixed the rocksdb.num.sst.read.per.level, rocksdb.num.index.and.filter.blocks.read.per.level and rocksdb.num.level.read.per.multiget stats in the MultiGet coroutines
* Fix a bug in io_uring_prep_cancel in AbortIO API for posix which expects sqe->addr to match with read request submitted and wrong paramter was being passed.
* Fixed a regression in iterator performance when the entire DB is a single memtable introduced in #10449. The fix is in #10705 and #10716.
* Fix a bug in io_uring_prep_cancel in AbortIO API for posix which expects sqe->addr to match with read request submitted and wrong paramter was being passed.
* Fixed a regression in iterator performance when the entire DB is a single memtable introduced in #10449. The fix is in #10705 and #10716.
### Public API changes
* Add `rocksdb_column_family_handle_get_id`, `rocksdb_column_family_handle_get_name` to get name, id of column family in C API
* Add a new stat rocksdb.async.prefetch.abort.micros to measure time spent waiting for async prefetch reads to abort
### Java API Changes
* Add CompactionPriority.RoundRobin.
* Revert to using the default metadata charge policy when creating an LRU cache via the Java API.
### Behavior Change
* DBOptions::verify_sst_unique_id_in_manifest is now an on-by-default feature that verifies SST file identity whenever they are opened by a DB, rather than only at DB::Open time.
* Right now, when the option migration tool (OptionChangeMigration()) migrates to FIFO compaction, it compacts all the data into one single SST file and move to L0. This might create a problem for some users: the giant file may be soon deleted to satisfy max_table_files_size, and might cayse the DB to be almost empty. We change the behavior so that the files are cut to be smaller, but these files might not follow the data insertion order. With the change, after the migration, migrated data might not be dropped by insertion order by FIFO compaction.
* When a block is firstly found from `CompressedSecondaryCache`, we just insert a dummy block into the primary cache and don’t erase the block from `CompressedSecondaryCache`. A standalone handle is returned to the caller. Only if the block is found again from `CompressedSecondaryCache` before the dummy block is evicted, we erase the block from `CompressedSecondaryCache` and insert it into the primary cache.
* When a block is firstly evicted from the primary cache to `CompressedSecondaryCache`, we just insert a dummy block in `CompressedSecondaryCache`. Only if it is evicted again before the dummy block is evicted from the cache, it is treated as a hot block and is inserted into `CompressedSecondaryCache`.
* Improved the estimation of memory used by cached blobs by taking into account the size of the object owning the blob value and also the allocator overhead if `malloc_usable_size` is available (see #10583).
* Blob values now have their own category in the cache occupancy statistics, as opposed to being lumped into the "Misc" bucket (see #10601).
* Change the optimize_multiget_for_io experimental ReadOptions flag to default on.
### New Features
* RocksDB does internal auto prefetching if it notices 2 sequential reads if readahead_size is not specified. New option `num_file_reads_for_auto_readahead` is added in BlockBasedTableOptions which indicates after how many sequential reads internal auto prefetching should be start (default is 2).
* Added new perf context counters `block_cache_standalone_handle_count`, `block_cache_real_handle_count`,`compressed_sec_cache_insert_real_count`, `compressed_sec_cache_insert_dummy_count`, `compressed_sec_cache_uncompressed_bytes`, and `compressed_sec_cache_compressed_bytes`.
* Memory for blobs which are to be inserted into the blob cache is now allocated using the cache's allocator (see #10628 and #10647).
* HyperClockCache is an experimental, lock-free Cache alternative for block cache that offers much improved CPU efficiency under high parallel load or high contention, with some caveats. As much as 4.5x higher ops/sec vs. LRUCache has been seen in db_bench under high parallel load.
* `CompressedSecondaryCacheOptions::enable_custom_split_merge` is added for enabling the custom split and merge feature, which split the compressed value into chunks so that they may better fit jemalloc bins.
### Performance Improvements
* Iterator performance is improved for `DeleteRange()` users. Internally, iterator will skip to the end of a range tombstone when possible, instead of looping through each key and check individually if a key is range deleted.
* Eliminated some allocations and copies in the blob read path. Also, `PinnableSlice` now only points to the blob value and pins the backing resource (cache entry or buffer) in all cases, instead of containing a copy of the blob value. See #10625 and #10647.
* In case of scans with async_io enabled, few optimizations have been added to issue more asynchronous requests in parallel in order to avoid synchronous prefetching.
* `DeleteRange()` users should see improvement in get/iterator performance from mutable memtable (see #10547).
2022-10-07T16:28:46+00:00rocksdb v7.7.3rocksdb v7.7.32022-10-12T21:58:10+00:00## 7.7.3 (10/11/2022)
### Bug Fixes
* Fixed a memory safety bug in experimental HyperClockCache (#10768)2022-10-12T21:58:10+00:00rocksdb v7.7.8rocksdb v7.7.82022-12-15T18:52:42+00:00## 7.7.8 (2022-11-27)
### Bug Fixes
* Fix failed memtable flush retry bug that could cause wrongly ordered updates, which would surface to writers as `Status::Corruption` in case of `force_consistency_checks=true` (default). It affects use cases that enable both parallel flush (`max_background_flushes > 1` or `max_background_jobs >= 8`) and non-default memtable count (`max_write_buffer_number > 2`).
* Tiered Storage: fixed excessive keys written to penultimate level in non-debug builds.
* Fixed a regression in iterator where range tombstones after `iterate_upper_bound` is processed.
## 7.7.7 (2022-11-15)
### Bug Fixes
* Fixed a regression in scan for async_io. During seek, valid buffers were getting cleared causing a regression.
## 7.7.6 (2022-11-03)
### Bug Fixes
* Fix memory corruption error in scans if async_io is enabled. Memory corruption happened if there is IOError while reading the data leading to empty buffer and other buffer already in progress of async read goes again for reading.
## 7.7.5 (2022-10-28)
### Bug Fixes
* Fixed an iterator performance regression for delete range users when scanning through a consecutive sequence of range tombstones (#10877).
## 7.7.4 (2022-10-28)
### Bug Fixes
* Fixed a case of calling malloc_usable_size on result of operator new[].2022-12-15T18:52:42+00:00rocksdb v7.8.3rocksdb v7.8.32022-12-15T18:56:20+00:00## 7.8.3 (2022-11-29)
* Revert an internal change in 7.8.0 associated with some memory usage churn.
## 7.8.2 (2022-11-27)
### Behavior changes
* Make best-efforts recovery verify SST unique ID before Version construction (#10962)
* Fix failed memtable flush retry bug that could cause wrongly ordered updates, which would surface to writers as `Status::Corruption` in case of `force_consistency_checks=true` (default). It affects use cases that enable both parallel flush (`max_background_flushes > 1` or `max_background_jobs >= 8`) and non-default memtable count (`max_write_buffer_number > 2`).
* Tiered Storage: fixed excessive keys written to penultimate level in non-debug builds.
### Bug Fixes
* Fixed a regression in scan for async_io. During seek, valid buffers were getting cleared causing a regression.
* Fixed a performance regression in iterator where range tombstones after `iterate_upper_bound` is processed.
## 7.8.1 (2022-11-02)
### Bug Fixes
* Fix memory corruption error in scans if async_io is enabled. Memory corruption happened if there is IOError while reading the data leading to empty buffer and other buffer already in progress of async read goes again for reading.
## 7.8.0 (2022-10-22)
### New Features
* `DeleteRange()` now supports user-defined timestamp.
* Provide support for async_io with tailing iterators when ReadOptions.tailing is enabled during scans.
* Tiered Storage: allow data moving up from the last level to the penultimate level if the input level is penultimate level or above.
* Added `DB::Properties::kFastBlockCacheEntryStats`, which is similar to `DB::Properties::kBlockCacheEntryStats`, except returns cached (stale) values in more cases to reduce overhead.
* FIFO compaction now supports migrating from a multi-level DB via DB::Open(). During the migration phase, FIFO compaction picker will:
* picks the sst file with the smallest starting key in the bottom-most non-empty level.
* Note that during the migration phase, the file purge order will only be an approximation of "FIFO" as files in lower-level might sometime contain newer keys than files in upper-level.
* Added an option `ignore_max_compaction_bytes_for_input` to ignore max_compaction_bytes limit when adding files to be compacted from input level. This should help reduce write amplification. The option is enabled by default.
* Tiered Storage: allow data moving up from the last level even if it's a last level only compaction, as long as the penultimate level is empty.
* Add a new option IOOptions.do_not_recurse that can be used by underlying file systems to skip recursing through sub directories and list only files in GetChildren API.
* Add option `preserve_internal_time_seconds` to preserve the time information for the latest data. Which can be used to determine the age of data when `preclude_last_level_data_seconds` is enabled. The time information is attached with SST in table property `rocksdb.seqno.time.map` which can be parsed by tool ldb or sst_dump.
### Bug Fixes
* Fix a bug in io_uring_prep_cancel in AbortIO API for posix which expects sqe->addr to match with read request submitted and wrong paramter was being passed.
* Fixed a regression in iterator performance when the entire DB is a single memtable introduced in #10449. The fix is in #10705 and #10716.
* Fixed an optimistic transaction validation bug caused by DBImpl::GetLatestSequenceForKey() returning non-latest seq for merge (#10724).
* Fixed a bug in iterator refresh which could segfault for DeleteRange users (#10739).
* Fixed a bug causing manual flush with `flush_opts.wait=false` to stall when database has stopped all writes (#10001).
* Fixed a bug in iterator refresh that was not freeing up SuperVersion, which could cause excessive resource pinniung (#10770).
* Fixed a bug where RocksDB could be doing compaction endlessly when allow_ingest_behind is true and the bottommost level is not filled (#10767).
* Fixed a memory safety bug in experimental HyperClockCache (#10768)
* Fixed some cases where `ldb update_manifest` and `ldb unsafe_remove_sst_file` are not usable because they were requiring the DB files to match the existing manifest state (before updating the manifest to match a desired state).
### Performance Improvements
* Try to align the compaction output file boundaries to the next level ones, which can reduce more than 10% compaction load for the default level compaction. The feature is enabled by default, to disable, set `AdvancedColumnFamilyOptions.level_compaction_dynamic_file_size` to false. As a side effect, it can create SSTs larger than the target_file_size (capped at 2x target_file_size) or smaller files.
* Improve RoundRobin TTL compaction, which is going to be the same as normal RoundRobin compaction to move the compaction cursor.
* Fix a small CPU regression caused by a change that UserComparatorWrapper was made Customizable, because Customizable itself has small CPU overhead for initialization.
* Fixed an iterator performance regression for delete range users when scanning through a consecutive sequence of range tombstones (#10877).
### Behavior Changes
* Sanitize min_write_buffer_number_to_merge to 1 if atomic flush is enabled to prevent unexpected data loss when WAL is disabled in a multi-column-family setting (#10773).
### Public API changes
* Make kXXH3 checksum the new default, because it is faster on common hardware, especially with kCRC32c affected by a performance bug in some versions of clang (https://github.com/facebook/rocksdb/issues/9891). DBs written with this new setting can be read by RocksDB 6.27 and newer.
* Refactor the classes, APIs and data structures for block cache tracing to allow a user provided trace writer to be used. Introduced an abstract BlockCacheTraceWriter class that takes a structured BlockCacheTraceRecord. The BlockCacheTraceWriter implementation can then format and log the record in whatever way it sees fit. The default BlockCacheTraceWriterImpl does file tracing using a user provided TraceWriter. More details in rocksdb/includb/block_cache_trace_writer.h.2022-12-15T18:56:20+00:00rocksdb v7.9.2rocksdb v7.9.22023-01-17T18:51:07+00:00## 7.9.2 (12/21/2022)
### Bug Fixes
* Fixed a heap use after free bug in async scan prefetching when the scan thread and another thread try to read and load the same seek block into cache.
## 7.9.1 (12/8/2022)
### Bug Fixes
* Fixed a regression in iterator where range tombstones after `iterate_upper_bound` is processed.
* Fixed a memory leak in MultiGet with async_io read option, caused by IO errors during table file open
### Behavior changes
* Make best-efforts recovery verify SST unique ID before Version construction (#10962)
## 7.9.0 (11/21/2022)
### Performance Improvements
* Fixed an iterator performance regression for delete range users when scanning through a consecutive sequence of range tombstones (#10877).
### Bug Fixes
* Fix memory corruption error in scans if async_io is enabled. Memory corruption happened if there is IOError while reading the data leading to empty buffer and other buffer already in progress of async read goes again for reading.
* Fix failed memtable flush retry bug that could cause wrongly ordered updates, which would surface to writers as `Status::Corruption` in case of `force_consistency_checks=true` (default). It affects use cases that enable both parallel flush (`max_background_flushes > 1` or `max_background_jobs >= 8`) and non-default memtable count (`max_write_buffer_number > 2`).
* Fixed an issue where the `READ_NUM_MERGE_OPERANDS` ticker was not updated when the base key-value or tombstone was read from an SST file.
* Fixed a memory safety bug when using a SecondaryCache with `block_cache_compressed`. `block_cache_compressed` no longer attempts to use SecondaryCache features.
* Fixed a regression in scan for async_io. During seek, valid buffers were getting cleared causing a regression.
* Tiered Storage: fixed excessive keys written to penultimate level in non-debug builds.
### New Features
* Add basic support for user-defined timestamp to Merge (#10819).
* Add stats for ReadAsync time spent and async read errors.
* Basic support for the wide-column data model is now available. Wide-column entities can be stored using the `PutEntity` API, and retrieved using `GetEntity` and the new `columns` API of iterator. For compatibility, the classic APIs `Get` and `MultiGet`, as well as iterator's `value` API return the value of the anonymous default column of wide-column entities; also, `GetEntity` and iterator's `columns` return any plain key-values in the form of an entity which only has the anonymous default column. `Merge` (and `GetMergeOperands`) currently also apply to the default column; any other columns of entities are unaffected by `Merge` operations. Note that some features like compaction filters, transactions, user-defined timestamps, and the SST file writer do not yet support wide-column entities; also, there is currently no `MultiGet`-like API to retrieve multiple entities at once. We plan to gradually close the above gaps and also implement new features like column-level operations (e.g. updating or querying only certain columns of an entity).
* Marked HyperClockCache as a production-ready alternative to LRUCache for the block cache. HyperClockCache greatly improves hot-path CPU efficiency under high parallel load or high contention, with some documented caveats and limitations. As much as 4.5x higher ops/sec vs. LRUCache has been seen in db_bench under high parallel load.
* Add periodic diagnostics to info_log (LOG file) for HyperClockCache block cache if performance is degraded by bad `estimated_entry_charge` option.
### Public API Changes
* Marked `block_cache_compressed` as a deprecated feature. Use SecondaryCache instead.
* Added a `SecondaryCache::InsertSaved()` API, with default implementation depending on `Insert()`. Some implementations might need to add a custom implementation of `InsertSaved()`. (Details in API comments.)
2023-01-17T18:51:07+00:00rocksdb v7.10.2rocksdb v7.10.22023-03-02T01:00:53+00:00## 7.10.2 (02/10/2023)
### Bug Fixes
* Fixed a bug in DB open/recovery from a compressed WAL that was caused due to incorrect handling of certain record fragments with the same offset within a WAL block.
## 7.10.1 (02/01/2023)
### Bug Fixes
* Fixed a data race on `ColumnFamilyData::flush_reason` caused by concurrent flushes.
* Fixed `DisableManualCompaction()` and `CompactRangeOptions::canceled` to cancel compactions even when they are waiting on conflicting compactions to finish
* Fixed a bug in which a successful `GetMergeOperands()` could transiently return `Status::MergeInProgress()`
* Return the correct error (Status::NotSupported()) to MultiGet caller when ReadOptions::async_io flag is true and IO uring is not enabled. Previously, Status::Corruption() was being returned when the actual failure was lack of async IO support.
## 7.10.0 (01/23/2023)
### Behavior changes
* Make best-efforts recovery verify SST unique ID before Version construction (#10962)
* Introduce `epoch_number` and sort L0 files by `epoch_number` instead of `largest_seqno`. `epoch_number` represents the order of a file being flushed or ingested/imported. Compaction output file will be assigned with the minimum `epoch_number` among input files'. For L0, larger `epoch_number` indicates newer L0 file.
### Bug Fixes
* Fixed a regression in iterator where range tombstones after `iterate_upper_bound` is processed.
* Fixed a memory leak in MultiGet with async_io read option, caused by IO errors during table file open
* Fixed a bug that multi-level FIFO compaction deletes one file in non-L0 even when `CompactionOptionsFIFO::max_table_files_size` is no exceeded since #10348 or 7.8.0.
* Fixed a bug caused by `DB::SyncWAL()` affecting `track_and_verify_wals_in_manifest`. Without the fix, application may see "open error: Corruption: Missing WAL with log number" while trying to open the db. The corruption is a false alarm but prevents DB open (#10892).
* Fixed a BackupEngine bug in which RestoreDBFromLatestBackup would fail if the latest backup was deleted and there is another valid backup available.
* Fix L0 file misorder corruption caused by ingesting files of overlapping seqnos with memtable entries' through introducing `epoch_number`. Before the fix, `force_consistency_checks=true` may catch the corruption before it's exposed to readers, in which case writes returning `Status::Corruption` would be expected. Also replace the previous incomplete fix (#5958) to the same corruption with this new and more complete fix.
* Fixed a bug in LockWAL() leading to re-locking mutex (#11020).
* Fixed a heap use after free bug in async scan prefetching when the scan thread and another thread try to read and load the same seek block into cache.
* Fixed a heap use after free in async scan prefetching if dictionary compression is enabled, in which case sync read of the compression dictionary gets mixed with async prefetching
* Fixed a data race bug of `CompactRange()` under `change_level=true` acts on overlapping range with an ongoing file ingestion for level compaction. This will either result in overlapping file ranges corruption at a certain level caught by `force_consistency_checks=true` or protentially two same keys both with seqno 0 in two different levels (i.e, new data ends up in lower/older level). The latter will be caught by assertion in debug build but go silently and result in read returning wrong result in release build. This fix is general so it also replaced previous fixes to a similar problem for `CompactFiles()` (#4665), general `CompactRange()` and auto compaction (commit 5c64fb6 and 87dfc1d).
* Fixed a bug in compaction output cutting where small output files were produced due to TTL file cutting states were not being updated (#11075).
### New Features
* When an SstPartitionerFactory is configured, CompactRange() now automatically selects for compaction any files overlapping a partition boundary that is in the compaction range, even if no actual entries are in the requested compaction range. With this feature, manual compaction can be used to (re-)establish SST partition points when SstPartitioner changes, without a full compaction.
* Add BackupEngine feature to exclude files from backup that are known to be backed up elsewhere, using `CreateBackupOptions::exclude_files_callback`. To restore the DB, the excluded files must be provided in alternative backup directories using `RestoreOptions::alternate_dirs`.
### Public API Changes
* Substantial changes have been made to the Cache class to support internal development goals. Direct use of Cache class members is discouraged and further breaking modifications are expected in the future. SecondaryCache has some related changes and implementations will need to be updated. (Unlike Cache, SecondaryCache is still intended to support user implementations, and disruptive changes will be avoided.) (#10975)
* Add `MergeOperationOutput::op_failure_scope` for merge operator users to control the blast radius of merge operator failures. Existing merge operator users do not need to make any change to preserve the old behavior
### Performance Improvements
* Updated xxHash source code, which should improve kXXH3 checksum speed, at least on ARM (#11098).
* Improved CPU efficiency of DB reads, from block cache access improvements (#10975).2023-03-02T01:00:53+00:00rocksdb v8.0.0rocksdb v8.0.02023-03-18T00:15:53+00:00## 8.0.0 (02/19/2023)
### Behavior changes
* `ReadOptions::verify_checksums=false` disables checksum verification for more reads of non-`CacheEntryRole::kDataBlock` blocks.
* In case of scan with async_io enabled, if posix doesn't support IOUring, Status::NotSupported error will be returned to the users. Initially that error was swallowed and reads were switched to synchronous reads.
### Bug Fixes
* Fixed a data race on `ColumnFamilyData::flush_reason` caused by concurrent flushes.
* Fixed an issue in `Get` and `MultiGet` when user-defined timestamps is enabled in combination with BlobDB.
* Fixed some atypical behaviors for `LockWAL()` such as allowing concurrent/recursive use and not expecting `UnlockWAL()` after non-OK result. See API comments.
* Fixed a feature interaction bug where for blobs `GetEntity` would expose the blob reference instead of the blob value.
* Fixed `DisableManualCompaction()` and `CompactRangeOptions::canceled` to cancel compactions even when they are waiting on conflicting compactions to finish
* Fixed a bug in which a successful `GetMergeOperands()` could transiently return `Status::MergeInProgress()`
* Return the correct error (Status::NotSupported()) to MultiGet caller when ReadOptions::async_io flag is true and IO uring is not enabled. Previously, Status::Corruption() was being returned when the actual failure was lack of async IO support.
* Fixed a bug in DB open/recovery from a compressed WAL that was caused due to incorrect handling of certain record fragments with the same offset within a WAL block.
### Feature Removal
* Remove RocksDB Lite.
* The feature block_cache_compressed is removed. Statistics related to it are removed too.
* Remove deprecated Env::LoadEnv(). Use Env::CreateFromString() instead.
* Remove deprecated FileSystem::Load(). Use FileSystem::CreateFromString() instead.
* Removed the deprecated version of these utility functions and the corresponding Java bindings: `LoadOptionsFromFile`, `LoadLatestOptions`, `CheckOptionsCompatibility`.
* Remove the FactoryFunc from the LoadObject method from the Customizable helper methods.
### Public API Changes
* Moved rarely-needed Cache class definition to new advanced_cache.h, and added a CacheWrapper class to advanced_cache.h. Minor changes to SimCache API definitions.
* Completely removed the following deprecated/obsolete statistics: the tickers `BLOCK_CACHE_INDEX_BYTES_EVICT`, `BLOCK_CACHE_FILTER_BYTES_EVICT`, `BLOOM_FILTER_MICROS`, `NO_FILE_CLOSES`, `STALL_L0_SLOWDOWN_MICROS`, `STALL_MEMTABLE_COMPACTION_MICROS`, `STALL_L0_NUM_FILES_MICROS`, `RATE_LIMIT_DELAY_MILLIS`, `NO_ITERATORS`, `NUMBER_FILTERED_DELETES`, `WRITE_TIMEDOUT`, `BLOB_DB_GC_NUM_KEYS_OVERWRITTEN`, `BLOB_DB_GC_NUM_KEYS_EXPIRED`, `BLOB_DB_GC_BYTES_OVERWRITTEN`, `BLOB_DB_GC_BYTES_EXPIRED`, `BLOCK_CACHE_COMPRESSION_DICT_BYTES_EVICT` as well as the histograms `STALL_L0_SLOWDOWN_COUNT`, `STALL_MEMTABLE_COMPACTION_COUNT`, `STALL_L0_NUM_FILES_COUNT`, `HARD_RATE_LIMIT_DELAY_COUNT`, `SOFT_RATE_LIMIT_DELAY_COUNT`, `BLOB_DB_GC_MICROS`, and `NUM_DATA_BLOCKS_READ_PER_LEVEL`. Note that as a result, the C++ enum values of the still supported statistics have changed. Developers are advised to not rely on the actual numeric values.
* Deprecated IngestExternalFileOptions::write_global_seqno and change default to false. This option only needs to be set to true to generate a DB compatible with RocksDB versions before 5.16.0.
* Remove deprecated APIs `GetColumnFamilyOptionsFrom{Map|String}(const ColumnFamilyOptions&, ..)`, `GetDBOptionsFrom{Map|String}(const DBOptions&, ..)`, `GetBlockBasedTableOptionsFrom{Map|String}(const BlockBasedTableOptions& table_options, ..)` and ` GetPlainTableOptionsFrom{Map|String}(const PlainTableOptions& table_options,..)`.
* Added a subcode of `Status::Corruption`, `Status::SubCode::kMergeOperatorFailed`, for users to identify corruption failures originating in the merge operator, as opposed to RocksDB's internally identified data corruptions
### Build Changes
* The `make` build now builds a shared library by default instead of a static library. Use `LIB_MODE=static` to override.
### New Features
* Compaction filters are now supported for wide-column entities by means of the `FilterV3` API. See the comment of the API for more details.
* Added `do_not_compress_roles` to `CompressedSecondaryCacheOptions` to disable compression on certain kinds of block. Filter blocks are now not compressed by CompressedSecondaryCache by default.
* Added a new `MultiGetEntity` API that enables batched wide-column point lookups. See the API comments for more details.
2023-03-18T00:15:53+00:00rocksdb v8.1.1rocksdb v8.1.12023-04-20T22:02:38+00:00## 8.1.1 (04/06/2023)
### Bug Fixes
* In the DB::VerifyFileChecksums API, ensure that file system reads of SST files are equal to the readahead_size in ReadOptions, if specified. Previously, each read was 2x the readahead_size.
## 8.1.0 (03/18/2023)
### Behavior changes
* Compaction output file cutting logic now considers range tombstone start keys. For example, SST partitioner now may receive ParitionRequest for range tombstone start keys.
* If the async_io ReadOption is specified for MultiGet or NewIterator on a platform that doesn't support IO uring, the option is ignored and synchronous IO is used.
### Bug Fixes
* Fixed an issue for backward iteration when user defined timestamp is enabled in combination with BlobDB.
* Fixed a couple of cases where a Merge operand encountered during iteration wasn't reflected in the `internal_merge_count` PerfContext counter.
* Fixed a bug in CreateColumnFamilyWithImport()/ExportColumnFamily() which did not support range tombstones (#11252).
* Fixed a bug where an excluded column family from an atomic flush contains unflushed data that should've been included in this atomic flush (i.e, data of seqno less than the max seqno of this atomic flush), leading to potential data loss in this excluded column family when `WriteOptions::disableWAL == true` (#11148).
### New Features
* Add statistics rocksdb.secondary.cache.filter.hits, rocksdb.secondary.cache.index.hits, and rocksdb.secondary.cache.filter.hits
* Added a new PerfContext counter `internal_merge_point_lookup_count` which tracks the number of Merge operands applied while serving point lookup queries.
* Add new statistics rocksdb.table.open.prefetch.tail.read.bytes, rocksdb.table.open.prefetch.tail.{miss|hit}
* Add support for SecondaryCache with HyperClockCache (`HyperClockCacheOptions` inherits `secondary_cache` option from `ShardedCacheOptions`)
* Add new db properties `rocksdb.cf-write-stall-stats`, `rocksdb.db-write-stall-stats`and APIs to examine them in a structured way. In particular, users of `GetMapProperty()` with property `kCFWriteStallStats`/`kDBWriteStallStats` can now use the functions in `WriteStallStatsMapKeys` to find stats in the map.
### Public API Changes
* Changed various functions and features in `Cache` that are mostly relevant to custom implementations or wrappers. Especially, asychronous lookup functionality is moved from `Lookup()` to a new `StartAsyncLookup()` function.
2023-04-20T22:02:38+00:00rocksdb v8.3.2rocksdb v8.3.22023-06-23T23:45:37+00:00## 8.3.2 (06/14/2023)
### Bug Fixes
* Reduced cases of illegally using Env::Default() during static destruction by never destroying the internal PosixEnv itself (except for builds checking for memory leaks). (#11538)
## 8.3.1 (06/07/2023)
### Performance Improvements
* Fixed higher read QPS during DB::Open() reading files created prior to #11406, especially when reading many small file (size < 52 MB) during DB::Open() and partitioned filter or index is used.
## 8.3.0 (05/19/2023)
### New Features
* Introduced a new option `block_protection_bytes_per_key`, which can be used to enable per key-value integrity protection for in-memory blocks in block cache (#11287).
* Added `JemallocAllocatorOptions::num_arenas`. Setting `num_arenas > 1` may mitigate mutex contention in the allocator, particularly in scenarios where block allocations commonly bypass jemalloc tcache.
* Improve the operational safety of publishing a DB or SST files to many hosts by using different block cache hash seeds on different hosts. The exact behavior is controlled by new option `ShardedCacheOptions::hash_seed`, which also documents the solved problem in more detail.
* Introduced a new option `CompactionOptionsFIFO::file_temperature_age_thresholds` that allows FIFO compaction to compact files to different temperatures based on key age (#11428).
* Added a new ticker stat to count how many times RocksDB detected a corruption while verifying a block checksum: `BLOCK_CHECKSUM_MISMATCH_COUNT`.
* New statistics `rocksdb.file.read.db.open.micros` that measures read time of block-based SST tables or blob files during db open.
* New statistics tickers for various iterator seek behaviors and relevant filtering, as \*`_LEVEL_SEEK_`\*. (#11460)
### Public API Changes
* EXPERIMENTAL: Add new API `DB::ClipColumnFamily` to clip the key in CF to a certain range. It will physically deletes all keys outside the range including tombstones.
* Add `MakeSharedCache()` construction functions to various cache Options objects, and deprecated the `NewWhateverCache()` functions with long parameter lists.
* Changed the meaning of various Bloom filter stats (prefix vs. whole key), with iterator-related filtering only being tracked in the new \*`_LEVEL_SEEK_`\*. stats. (#11460)
### Behavior changes
* For x86, CPU features are no longer detected at runtime nor in build scripts, but in source code using common preprocessor defines. This will likely unlock some small performance improvements on some newer hardware, but could hurt performance of the kCRC32c checksum, which is no longer the default, on some "portable" builds. See PR #11419 for details.
### Bug Fixes
* Delete an empty WAL file on DB open if the log number is less than the min log number to keep
* Delete temp OPTIONS file on DB open if there is a failure to write it out or rename it
### Performance Improvements
* Improved the I/O efficiency of prefetching SST metadata by recording more information in the DB manifest. Opening files written with previous versions will still rely on heuristics for how much to prefetch (#11406).
2023-06-23T23:45:37+00:00rocksdb v8.3.3rocksdb v8.3.32023-09-01T20:48:11+00:00## 8.3.3 (2023-09-01)
### Bug Fixes
* Fix a bug where if there is an error reading from offset 0 of a file from L1+ and that the file is not the first file in the sorted run, data can be lost in compaction and read/scan can return incorrect results.
* Fix a bug where iterator may return incorrect result for DeleteRange() users if there was an error reading from a file.
* Fixed a race condition in `GenericRateLimiter` that could cause it to stop granting requests2023-09-01T20:48:11+00:00rocksdb v8.4.4rocksdb v8.4.42023-09-01T20:54:51+00:00## 8.4.4 (2023-09-01)
### Bug Fixes
* Fix a bug where if there is an error reading from offset 0 of a file from L1+ and that the file is not the first file in the sorted run, data can be lost in compaction and read/scan can return incorrect results.
* Fix a bug where iterator may return incorrect result for DeleteRange() users if there was an error reading from a file.
* Fixed a race condition in `GenericRateLimiter` that could cause it to stop granting requests
## 8.4.3 (2023-07-27)
### Bug Fixes
* Fix use_after_free bug in async_io MultiReads when underlying FS enabled kFSBuffer. kFSBuffer is when underlying FS pass their own buffer instead of using RocksDB scratch in FSReadRequest.
## 8.4.0 (2023-06-26)
### New Features
* Add FSReadRequest::fs_scratch which is a data buffer allocated and provided by underlying FileSystem to RocksDB during reads, when FS wants to provide its own buffer with data instead of using RocksDB provided FSReadRequest::scratch. This can help in cpu optimization by avoiding copy from file system's buffer to RocksDB buffer. More details on how to use/enable it in file_system.h. Right now its supported only for MultiReads(async + sync) with non direct io.
* Start logging non-zero user-defined timestamp sizes in WAL to signal user key format in subsequent records and use it during recovery. This change will break recovery from WAL files written by early versions that contain user-defined timestamps. The workaround is to ensure there are no WAL files to recover (i.e. by flushing before close) before upgrade.
* Added new property "rocksdb.obsolete-sst-files-size-property" that reports the size of SST files that have become obsolete but have not yet been deleted or scheduled for deletion
* Start to record the value of the flag `AdvancedColumnFamilyOptions.persist_user_defined_timestamps` in the Manifest and table properties for a SST file when it is created. And use the recorded flag when creating a table reader for the SST file. This flag is only explicitly record if it's false.
* Add a new option OptimisticTransactionDBOptions::shared_lock_buckets that enables sharing mutexes for validating transactions between DB instances, for better balancing memory efficiency and validation contention across DB instances. Different column families and DBs also now use different hash seeds in this validation, so that the same set of key names will not contend across DBs or column families.
* Add a new ticker `rocksdb.files.marked.trash.deleted` to track the number of trash files deleted by background thread from the trash queue.
* Add an API NewTieredVolatileCache() in include/rocksdb/cache.h to allocate an instance of a block cache with a primary block cache tier and a compressed secondary cache tier. A cache of this type distributes memory reservations against the block cache, such as WriteBufferManager, table reader memory etc., proportionally across both the primary and compressed secondary cache.
* Add `WaitForCompact()` to wait for all flush and compactions jobs to finish. Jobs to wait include the unscheduled (queued, but not scheduled yet).
* Add `WriteBatch::Release()` that releases the batch's serialized data to the caller.
### Public API Changes
* Add C API `rocksdb_options_add_compact_on_deletion_collector_factory_del_ratio`.
* change the FileSystem::use_async_io() API to SupportedOps API in order to extend it to various operations supported by underlying FileSystem. Right now it contains FSSupportedOps::kAsyncIO and FSSupportedOps::kFSBuffer. More details about FSSupportedOps in filesystem.h
* Add new tickers: `rocksdb.error.handler.bg.error.count`, `rocksdb.error.handler.bg.io.error.count`, `rocksdb.error.handler.bg.retryable.io.error.count` to replace the misspelled ones: `rocksdb.error.handler.bg.errro.count`, `rocksdb.error.handler.bg.io.errro.count`, `rocksdb.error.handler.bg.retryable.io.errro.count` ('error' instead of 'errro'). Users should switch to use the new tickers before 9.0 release as the misspelled old tickers will be completely removed then.
* Overload the API CreateColumnFamilyWithImport() to support creating ColumnFamily by importing multiple ColumnFamilies It requires that CFs should not overlap in user key range.
### Behavior Changes
* Change the default value for option `level_compaction_dynamic_level_bytes` to true. This affects users who use leveled compaction and do not set this option explicitly. These users may see additional background compactions following DB open. These compactions help to shape the LSM according to `level_compaction_dynamic_level_bytes` such that the size of each level Ln is approximately size of Ln-1 * `max_bytes_for_level_multiplier`. Turning on this option has other benefits too: see more detail in wiki: https://github.com/facebook/rocksdb/wiki/Leveled-Compaction#option-level_compaction_dynamic_level_bytes-and-levels-target-size and in option comment in advanced_options.h (#11525).
* For Leveled Compaction users, `CompactRange()` will now always try to compact to the last non-empty level. (#11468)
For Leveled Compaction users, `CompactRange()` with `bottommost_level_compaction = BottommostLevelCompaction::kIfHaveCompactionFilter` will behave similar to `kForceOptimized` in that it will skip files created during this manual compaction when compacting files in the bottommost level. (#11468)
* RocksDB will try to drop range tombstones during non-bottommost compaction when it is safe to do so. (#11459)
* When a DB is openend with `allow_ingest_behind=true` (currently only Universal compaction is supported), files in the last level, i.e. the ingested files, will not be included in any compaction. (#11489)
* Statistics `rocksdb.sst.read.micros` scope is expanded to all SST reads except for file ingestion and column family import (some compaction reads were previously excluded).
### Bug Fixes
* Reduced cases of illegally using Env::Default() during static destruction by never destroying the internal PosixEnv itself (except for builds checking for memory leaks). (#11538)
* Fix extra prefetching during seek in async_io when BlockBasedTableOptions.num_file_reads_for_auto_readahead is 1 leading to extra reads than required.
* Fix a bug where compactions that are qualified to be run as 2 subcompactions were only run as one subcompaction.
* Fix a use-after-move bug in block.cc.2023-09-01T20:54:51+00:00rocksdb v8.5.3rocksdb v8.5.32023-09-01T21:01:16+00:00Please note 8.5.1 includes a fix for a persisted database corruption in an unlikely edge case. Upgrading to a version including this fix, like this one, is highly recommended!
## 8.5.3 (2023-09-01)
### Bug Fixes
* Fixed a race condition in `GenericRateLimiter` that could cause it to stop granting requests
## 8.5.2 (2023-08-31)
### Bug fixes
* Fix a bug where iterator may return incorrect result for DeleteRange() users if there was an error reading from a file.
## 8.5.1 (2023-08-31)
### Bug fixes
* Fix a bug where if there is an error reading from offset 0 of a file from L1+ and that the file is not the first file in the sorted run, data can be lost in compaction and read/scan can return incorrect results.
## 8.5.0 (2023-07-21)
### Public API Changes
* Removed recently added APIs `GeneralCache` and `MakeSharedGeneralCache()` as our plan changed to stop exposing a general-purpose cache interface. The old forms of these APIs, `Cache` and `NewLRUCache()`, are still available, although general-purpose caching support will be dropped eventually.
### Behavior Changes
* Option `periodic_compaction_seconds` no longer supports FIFO compaction: setting it has no effect on FIFO compactions. FIFO compaction users should only set option `ttl` instead.
* Move prefetching responsibility to page cache for compaction read for non directIO use case
### Performance Improvements
* In case of direct_io, if buffer passed by callee is already aligned, RandomAccessFileRead::Read will avoid realloacting a new buffer, reducing memcpy and use already passed aligned buffer.
* Small efficiency improvement to HyperClockCache by reducing chance of compiler-generated heap allocations
### Bug Fixes
* Fix use_after_free bug in async_io MultiReads when underlying FS enabled kFSBuffer. kFSBuffer is when underlying FS pass their own buffer instead of using RocksDB scratch in FSReadRequest. Right now it's an experimental feature.
* Fix a bug in FileTTLBooster that can cause users with a large number of levels (more than 65) to see errors like "runtime error: shift exponent .. is too large.." (#11673).2023-09-01T21:01:16+00:00rocksdb v8.5.4rocksdb v8.5.42023-09-27T05:20:53+00:00## 8.5.4 (09/26/2023)
### Bug Fixes
* Fixed a bug where compaction read under non direct IO still falls back to RocksDB internal prefetching after file system's prefetching returns non-OK status other than `Status::NotSupported()`
### Behavior Changes
* For non direct IO, eliminate the file system prefetching attempt for compaction read when `Options::compaction_readahead_size` is 02023-09-27T05:20:53+00:00rocksdb v8.6.7rocksdb v8.6.72023-10-05T17:36:27+00:00## 8.6.7 (09/26/2023)
### Bug Fixes
* Fixed a bug where compaction read under non direct IO still falls back to RocksDB internal prefetching after file system's prefetching returns non-OK status other than `Status::NotSupported()`
### Behavior Changes
* For non direct IO, eliminate the file system prefetching attempt for compaction read when `Options::compaction_readahead_size` is 0
## 8.6.6 (09/25/2023)
### Bug Fixes
* Fix a bug with atomic_flush=true that can cause DB to stuck after a flush fails (#11872).
* Fix a bug where RocksDB (with atomic_flush=false) can delete output SST files of pending flushes when a previous concurrent flush fails (#11865). This can result in DB entering read-only state with error message like `IO error: No such file or directory: While open a file for random read: /tmp/rocksdbtest-501/db_flush_test_87732_4230653031040984171/000013.sst`.
* When the compressed secondary cache capacity is reduced to 0, it should be completely disabled. Before this fix, inserts and lookups would still go to the backing `LRUCache` before returning, thus incurring locking overhead. With this fix, inserts and lookups are no-ops and do not add any overhead.
## 8.6.5 (09/15/2023)
### Bug Fixes
* Fixed a bug where `rocksdb.file.read.verify.file.checksums.micros` is not populated.
## 8.6.4 (09/13/2023)
### Public API changes
* Add a column family option `default_temperature` that is used for file reading accounting purpose, such as io statistics, for files that don't have an explicitly set temperature.
## 8.6.3 (09/12/2023)
### Bug Fixes
* Fix a bug where if there is an error reading from offset 0 of a file from L1+ and that the file is not the first file in the sorted run, data can be lost in compaction and read/scan can return incorrect results.
* Fix a bug where iterator may return incorrect result for DeleteRange() users if there was an error reading from a file.
## 8.6.2 (09/11/2023)
### Bug Fixes
* Add a fix for async_io where during seek, when reading a block for seeking a target key in a file without any readahead, the iterator aligned the read on a page boundary and reading more than necessary. This increased the storage read bandwidth usage.
## 8.6.1 (08/30/2023)
### Public API Changes
* `Options::compaction_readahead_size` 's default value is changed from 0 to 2MB.
### Behavior Changes
* Compaction read performance will regress when `Options::compaction_readahead_size` is explicitly set to 0
## 8.6.0 (08/18/2023)
### New Features
* Added enhanced data integrity checking on SST files with new format_version=6. Performance impact is very small or negligible. Previously if SST data was misplaced or re-arranged by the storage layer, it could pass block checksum with higher than 1 in 4 billion probability. With format_version=6, block checksums depend on what file they are in and location within the file. This way, misplaced SST data is no more likely to pass checksum verification than randomly corrupted data. Also in format_version=6, SST footers are checksum-protected.
* Add a new feature to trim readahead_size during scans upto upper_bound when iterate_upper_bound is specified. It's enabled through ReadOptions.auto_readahead_size. Users must also specify ReadOptions.iterate_upper_bound.
* RocksDB will compare the number of input keys to the number of keys processed after each compaction. Compaction will fail and report Corruption status if the verification fails. Option `compaction_verify_record_count` is introduced for this purpose and is enabled by default.
* Add a CF option `bottommost_file_compaction_delay` to allow specifying the delay of bottommost level single-file compactions.
* Add support to allow enabling / disabling user-defined timestamps feature for an existing column family in combination with the in-Memtable only feature.
* Implement a new admission policy for the compressed secondary cache that admits blocks evicted from the primary cache with the hit bit set. This policy can be specified in TieredVolatileCacheOptions by setting the newly added adm_policy option.
* Add a column family option `memtable_max_range_deletions` that limits the number of range deletions in a memtable. RocksDB will try to do an automatic flush after the limit is reached. (#11358)
* Add PutEntity API in sst_file_writer
* Add `timeout` in microsecond option to `WaitForCompactOptions` to allow timely termination of prolonged waiting in scenarios like recurring recoverable errors, such as out-of-space situations and continuous write streams that sustain ongoing flush and compactions
* New statistics `rocksdb.file.read.{get|multiget|db.iterator|verify.checksum|verify.file.checksums}.micros` measure read time of block-based SST tables or blob files during db open, `Get()`, `MultiGet()`, using db iterator, `VerifyFileChecksums()` and `VerifyChecksum()`. They require stats level greater than `StatsLevel::kExceptDetailedTimers`.
* Add close_db option to `WaitForCompactOptions` to call Close() after waiting is done.
* Add a new compression option `CompressionOptions::checksum` for enabling ZSTD's checksum feature to detect corruption during decompression.
### Public API Changes
* Mark `Options::access_hint_on_compaction_start` related APIs as deprecated. See #11631 for alternative behavior.
### Behavior Changes
* Statistics `rocksdb.sst.read.micros` now includes time spent on multi read and async read into the file
* For Universal Compaction users, periodic compaction (option `periodic_compaction_seconds`) will be set to 30 days by default if block based table is used.
### Bug Fixes
* Fix a bug in FileTTLBooster that can cause users with a large number of levels (more than 65) to see errors like "runtime error: shift exponent .. is too large.." (#11673).2023-10-05T17:36:27+00:00rocksdb v8.7.3rocksdb v8.7.32023-11-20T17:28:00+00:00## 8.7.3 (2023-10-30)
### Behavior Changes
* Deleting stale files upon recovery are delegated to SstFileManger if available so they can be rate limited.
## 8.7.2 (2023-10-25)
### Public API Changes
* Add new Cache APIs GetSecondaryCacheCapacity() and GetSecondaryCachePinnedUsage() to return the configured capacity, and cache reservation charged to the secondary cache.
### Bug Fixes
* Fixed a possible underflow when computing the compressed secondary cache share of memory reservations while updating the compressed secondary to total block cache ratio.
* Fix an assertion failure when UpdeteTieredCache() is called in an idempotent manner.
## 8.7.1 (2023-10-20)
### Bug Fixes
* Fix a bug in auto_readahead_size where first_internal_key of index blocks wasn't copied properly resulting in corruption error when first_internal_key was used for comparison.
* Add bounds check in WBWIIteratorImpl and make BaseDeltaIterator, WriteUnpreparedTxn and WritePreparedTxn respect the upper bound and lower bound in ReadOption. See 11680.
## 8.7.0 (2023-09-22)
### New Features
* Added an experimental new "automatic" variant of HyperClockCache that does not require a prior estimate of the average size of cache entries. This variant is activated when HyperClockCacheOptions::estimated\_entry\_charge = 0 and has essentially the same concurrency benefits as the existing HyperClockCache.
* Add a new statistic `COMPACTION_CPU_TOTAL_TIME` that records cumulative compaction cpu time. This ticker is updated regularly while a compaction is running.
* Add `GetEntity()` API for ReadOnly DB and Secondary DB.
* Add a new iterator API `Iterator::Refresh(const Snapshot *)` that allows iterator to be refreshed while using the input snapshot to read.
* Added a new read option `merge_operand_count_threshold`. When the number of merge operands applied during a successful point lookup exceeds this threshold, the query will return a special OK status with a new subcode `kMergeOperandThresholdExceeded`. Applications might use this signal to take action to reduce the number of merge operands for the affected key(s), for example by running a compaction.
* For `NewRibbonFilterPolicy()`, made the `bloom_before_level` option mutable through the Configurable interface and the SetOptions API, allowing dynamic switching between all-Bloom and all-Ribbon configurations, and configurations in between. See comments on `NewRibbonFilterPolicy()`
* RocksDB now allows the block cache to be stacked on top of a compressed secondary cache and a non-volatile secondary cache, thus creating a three-tier cache. To set it up, use the `NewTieredCache()` API in rocksdb/cache.h..
* Added a new wide-column aware full merge API called `FullMergeV3` to `MergeOperator`. `FullMergeV3` supports wide columns both as base value and merge result, which enables the application to perform more general transformations during merges. For backward compatibility, the default implementation implements the earlier logic of applying the merge operation to the default column of any wide-column entities. Specifically, if there is no base value or the base value is a plain key-value, the default implementation falls back to `FullMergeV2`. If the base value is a wide-column entity, the default implementation invokes `FullMergeV2` to perform the merge on the default column, and leaves any other columns unchanged.
* Add wide column support to ldb commands (scan, dump, idump, dump_wal) and sst_dump tool's scan command
### Public API Changes
* Expose more information about input files used in table creation (if any) in `CompactionFilter::Context`. See `CompactionFilter::Context::input_start_level`,`CompactionFilter::Context::input_table_properties` for more.
* `Options::compaction_readahead_size` 's default value is changed from 0 to 2MB.
* When using LZ4 compression, the `acceleration` parameter is configurable by setting the negated value in `CompressionOptions::level`. For example, `CompressionOptions::level=-10` will set `acceleration=10`
* The `NewTieredCache` API has been changed to take the total cache capacity (inclusive of both the primary and the compressed secondary cache) and the ratio of total capacity to allocate to the compressed cache. These are specified in `TieredCacheOptions`. Any capacity specified in `LRUCacheOptions`, `HyperClockCacheOptions` and `CompressedSecondaryCacheOptions` is ignored. A new API, `UpdateTieredCache` is provided to dynamically update the total capacity, ratio of compressed cache, and admission policy.
* The `NewTieredVolatileCache()` API in rocksdb/cache.h has been renamed to `NewTieredCache()`.
### Behavior Changes
* Compaction read performance will regress when `Options::compaction_readahead_size` is explicitly set to 0
* Universal size amp compaction will conditionally exclude some of the newest L0 files when selecting input with a small negative impact to size amp. This is to prevent a large number of L0 files from being locked by a size amp compaction, potentially leading to write stop with a few more flushes.
* Change ldb scan command delimiter from ':' to '==>'.
* For non direct IO, eliminate the file system prefetching attempt for compaction read when `Options::compaction_readahead_size` is 0
### Bug Fixes
* Fix a bug where if there is an error reading from offset 0 of a file from L1+ and that the file is not the first file in the sorted run, data can be lost in compaction and read/scan can return incorrect results.
* Fix a bug where iterator may return incorrect result for DeleteRange() users if there was an error reading from a file.
* Fix a bug with atomic_flush=true that can cause DB to stuck after a flush fails (#11872).
* Fix a bug where RocksDB (with atomic_flush=false) can delete output SST files of pending flushes when a previous concurrent flush fails (#11865). This can result in DB entering read-only state with error message like `IO error: No such file or directory: While open a file for random read: /tmp/rocksdbtest-501/db_flush_test_87732_4230653031040984171/000013.sst`.
* Fix an assertion fault during seek with async_io when readahead trimming is enabled.
* When the compressed secondary cache capacity is reduced to 0, it should be completely disabled. Before this fix, inserts and lookups would still go to the backing `LRUCache` before returning, thus incurring locking overhead. With this fix, inserts and lookups are no-ops and do not add any overhead.
* Updating the tiered cache (cache allocated using NewTieredCache()) by calling SetCapacity() on it was not working properly. The initial creation would set the primary cache capacity to the combined primary and compressed secondary cache capacity. But SetCapacity() would just set the primary cache capacity. With this fix, the user always specifies the total budget and compressed secondary cache ratio on creation. Subsequently, SetCapacity() will distribute the new capacity across the two caches by the same ratio.
* Fixed a bug in `MultiGet` for cleaning up SuperVersion acquired with locking db mutex.
* Fix a bug where row cache can falsely return kNotFound even though row cache entry is hit.
* Fixed a race condition in `GenericRateLimiter` that could cause it to stop granting requests
* Fix a bug (Issue #10257) where DB can hang after write stall since no compaction is scheduled (#11764).
* Add a fix for async_io where during seek, when reading a block for seeking a target key in a file without any readahead, the iterator aligned the read on a page boundary and reading more than necessary. This increased the storage read bandwidth usage.
* Fix an issue in sst dump tool to handle bounds specified for data with user-defined timestamps.
* When auto_readahead_size is enabled, update readahead upper bound during readahead trimming when reseek changes iterate_upper_bound dynamically.
* Fixed a bug where `rocksdb.file.read.verify.file.checksums.micros` is not populated
* Fixed a bug where compaction read under non direct IO still falls back to RocksDB internal prefetching after file system's prefetching returns non-OK status other than `Status::NotSupported()`
### Performance Improvements
* Added additional improvements in tuning readahead_size during Scans when auto_readahead_size is enabled. However it's not recommended for backward scans and might impact the performance. More details in options.h.
* During async_io, the Seek happens in 2 phases. Phase 1 starts an asynchronous read on a block cache miss, and phase 2 waits for it to complete and finishes the seek. In both phases, it tries to lookup the block cache for the data block first before looking in the prefetch buffer. It's optimized by doing the block cache lookup only in the first phase that would save some CPU.
2023-11-20T17:28:00+00:00rocksdb v8.8.1rocksdb v8.8.12023-11-22T18:00:46+00:00## 8.8.1 (2023-11-17)
### Bug fixes
* Make the cache memory reservation accounting in Tiered cache (primary and compressed secondary cache) more accurate to avoid over/under charging the secondary cache.
* Allow increasing the compressed_secondary_ratio in the Tiered cache after setting it to 0 to disable.
## 8.8.0 (2023-10-23)
### New Features
* Introduce AttributeGroup by adding the first AttributeGroup support API, MultiGetEntity(). Through the use of Column Families, AttributeGroup enables users to logically group wide-column entities. More APIs to support AttributeGroup will come soon, including GetEntity, PutEntity, and others.
* Added new tickers `rocksdb.fifo.{max.size|ttl}.compactions` to count FIFO compactions that drop files for different reasons
* Add an experimental offpeak duration awareness by setting `DBOptions::daily_offpeak_time_utc` in "HH:mm-HH:mm" format. This information will be used for resource optimization in the future
* Users can now change the max bytes granted in a single refill period (i.e, burst) during runtime by `SetSingleBurstBytes()` for RocksDB rate limiter
### Public API Changes
* The default value of `DBOptions::fail_if_options_file_error` changed from `false` to `true`. Operations that set in-memory options (e.g., `DB::Open*()`, `DB::SetOptions()`, `DB::CreateColumnFamily*()`, and `DB::DropColumnFamily()`) but fail to persist the change will now return a non-OK `Status` by default.
* Add new Cache APIs GetSecondaryCacheCapacity() and GetSecondaryCachePinnedUsage() to return the configured capacity, and cache reservation charged to the secondary cache.
### Behavior Changes
* For non direct IO, eliminate the file system prefetching attempt for compaction read when `Options::compaction_readahead_size` is 0
* During a write stop, writes now block on in-progress recovery attempts
* Deleting stale files upon recovery are delegated to SstFileManger if available so they can be rate limited.
### Bug Fixes
* Fix a bug in auto_readahead_size where first_internal_key of index blocks wasn't copied properly resulting in corruption error when first_internal_key was used for comparison.
* Fixed a bug where compaction read under non direct IO still falls back to RocksDB internal prefetching after file system's prefetching returns non-OK status other than `Status::NotSupported()`
* Add bounds check in WBWIIteratorImpl and make BaseDeltaIterator, WriteUnpreparedTxn and WritePreparedTxn respect the upper bound and lower bound in ReadOption. See 11680.
* Fixed the handling of wide-column base values in the `max_successive_merges` logic.
* Fixed a rare race bug involving a concurrent combination of Create/DropColumnFamily and/or Set(DB)Options that could lead to inconsistency between (a) the DB's reported options state, (b) the DB options in effect, and (c) the latest persisted OPTIONS file.
* Fixed a possible underflow when computing the compressed secondary cache share of memory reservations while updating the compressed secondary to total block cache ratio.
### Performance Improvements
* Improved the I/O efficiency of DB::Open a new DB with `create_missing_column_families=true` and many column families.
2023-11-22T18:00:46+00:00rocksdb v8.9.1rocksdb v8.9.12023-12-11T22:14:12+00:00## 8.9.1 (2023-12-08)
### Bug Fixes
* Avoid destroying the periodic task scheduler's default timer in order to prevent static destruction order issues.
## 8.9.0 (2023-11-17)
### New Features
* Add GetEntity() and PutEntity() API implementation for Attribute Group support. Through the use of Column Families, AttributeGroup enables users to logically group wide-column entities.
### Public API Changes
* Added rocksdb_ratelimiter_create_auto_tuned API to create an auto-tuned GenericRateLimiter.
* Added clipColumnFamily() to the Java API to clip the entries in the CF according to the range [begin_key, end_key).
* Make the `EnableFileDeletion` API not default to force enabling. For users that rely on this default behavior and still
want to continue to use force enabling, they need to explicitly pass a `true` to `EnableFileDeletion`.
* Add new Cache APIs GetSecondaryCacheCapacity() and GetSecondaryCachePinnedUsage() to return the configured capacity, and cache reservation charged to the secondary cache.
### Behavior Changes
* During off-peak hours defined by `daily_offpeak_time_utc`, the compaction picker will select a larger number of files for periodic compaction. This selection will include files that are projected to expire by the next off-peak start time, ensuring that these files are not chosen for periodic compaction outside of off-peak hours.
* If an error occurs when writing to a trace file after `DB::StartTrace()`, the subsequent trace writes are skipped to avoid writing to a file that has previously seen error. In this case, `DB::EndTrace()` will also return a non-ok status with info about the error occured previously in its status message.
* Deleting stale files upon recovery are delegated to SstFileManger if available so they can be rate limited.
* Make RocksDB only call `TablePropertiesCollector::Finish()` once.
* When `WAL_ttl_seconds > 0`, we now process archived WALs for deletion at least every `WAL_ttl_seconds / 2` seconds. Previously it could be less frequent in case of small `WAL_ttl_seconds` values when size-based expiration (`WAL_size_limit_MB > 0 `) was simultaneously enabled.
### Bug Fixes
* Fixed a crash or assertion failure bug in experimental new HyperClockCache variant, especially when running with a SecondaryCache.
* Fix a race between flush error recovery and db destruction that can lead to db crashing.
* Fixed some bugs in the index builder/reader path for user-defined timestamps in Memtable only feature.2023-12-11T22:14:12+00:00rocksdb v8.10.0rocksdb v8.10.02024-01-10T19:52:20+00:00## 8.10.0 (12/15/2023)
### New Features
* Provide support for async_io to trim readahead_size by doing block cache lookup
* Added initial wide-column support in `WriteBatchWithIndex`. This includes the `PutEntity` API and support for wide columns in the existing read APIs (`GetFromBatch`, `GetFromBatchAndDB`, `MultiGetFromBatchAndDB`, and `BaseDeltaIterator`).
### Public API Changes
* Custom implementations of `TablePropertiesCollectorFactory` may now return a `nullptr` collector to decline processing a file, reducing callback overheads in such cases.
### Behavior Changes
* Make ReadOptions.auto_readahead_size default true which does prefetching optimizations for forward scans if iterate_upper_bound and block_cache is also specified.
* Compactions can be scheduled in parallel in an additional scenario: high compaction debt relative to the data size
* HyperClockCache now has built-in protection against excessive CPU consumption under the extreme stress condition of no (or very few) evictable cache entries, which can slightly increase memory usage such conditions. New option `HyperClockCacheOptions::eviction_effort_cap` controls the space-time trade-off of the response. The default should be generally well-balanced, with no measurable affect on normal operation.
### Bug Fixes
* Fix a corner case with auto_readahead_size where Prev Operation returns NOT SUPPORTED error when scans direction is changed from forward to backward.
* Avoid destroying the periodic task scheduler's default timer in order to prevent static destruction order issues.
* Fix double counting of BYTES_WRITTEN ticker when doing writes with transactions.
* Fix a WRITE_STALL counter that was reporting wrong value in few cases.
* A lookup by MultiGet in a TieredCache that goes to the local flash cache and finishes with very low latency, i.e before the subsequent call to WaitAll, is ignored, resulting in a false negative and a memory leak.
### Performance Improvements
* Java API extensions to improve consistency and completeness of APIs
- Extended `RocksDB.get([ColumnFamilyHandle columnFamilyHandle,] ReadOptions opt, ByteBuffer key, ByteBuffer value)` which now accepts indirect buffer parameters as well as direct buffer parameters
- Extended `RocksDB.put( [ColumnFamilyHandle columnFamilyHandle,] WriteOptions writeOpts, final ByteBuffer key, final ByteBuffer value)` which now accepts indirect buffer parameters as well as direct buffer parameters
- Added `RocksDB.merge([ColumnFamilyHandle columnFamilyHandle,] WriteOptions writeOptions, ByteBuffer key, ByteBuffer value)` methods with the same parameter options as `put(...)` - direct and indirect buffers are supported
- Added `RocksIterator.key( byte[] key [, int offset, int len])` methods which retrieve the iterator key into the supplied buffer
- Added `RocksIterator.value( byte[] value [, int offset, int len])` methods which retrieve the iterator value into the supplied buffer
- Deprecated `get(final ColumnFamilyHandle columnFamilyHandle, final ReadOptions readOptions, byte[])` in favour of `get(final ReadOptions readOptions, final ColumnFamilyHandle columnFamilyHandle, byte[])` which has consistent parameter ordering with other methods in the same class
- Added `Transaction.get( ReadOptions opt, [ColumnFamilyHandle columnFamilyHandle, ] byte[] key, byte[] value)` methods which retrieve the requested value into the supplied buffer
- Added `Transaction.get( ReadOptions opt, [ColumnFamilyHandle columnFamilyHandle, ] ByteBuffer key, ByteBuffer value)` methods which retrieve the requested value into the supplied buffer
- Added `Transaction.getForUpdate( ReadOptions readOptions, [ColumnFamilyHandle columnFamilyHandle, ] byte[] key, byte[] value, boolean exclusive [, boolean doValidate])` methods which retrieve the requested value into the supplied buffer
- Added `Transaction.getForUpdate( ReadOptions readOptions, [ColumnFamilyHandle columnFamilyHandle, ] ByteBuffer key, ByteBuffer value, boolean exclusive [, boolean doValidate])` methods which retrieve the requested value into the supplied buffer
- Added `Transaction.getIterator()` method as a convenience which defaults the `ReadOptions` value supplied to existing `Transaction.iterator()` methods. This mirrors the existing `RocksDB.iterator()` method.
- Added `Transaction.put([ColumnFamilyHandle columnFamilyHandle, ] ByteBuffer key, ByteBuffer value [, boolean assumeTracked])` methods which supply the key, and the value to be written in a `ByteBuffer` parameter
- Added `Transaction.merge([ColumnFamilyHandle columnFamilyHandle, ] ByteBuffer key, ByteBuffer value [, boolean assumeTracked])` methods which supply the key, and the value to be written/merged in a `ByteBuffer` parameter
- Added `Transaction.mergeUntracked([ColumnFamilyHandle columnFamilyHandle, ] ByteBuffer key, ByteBuffer value)` methods which supply the key, and the value to be written/merged in a `ByteBuffer` parameter
2024-01-10T19:52:20+00:00osquery 2.4.0osquery 2.4.02017-04-06T23:02:28+00:00## New features in 2.4.0:
### Important changes
#3073 The Windows `registry` table was refactored to have a look and feel like the `file` table.
#3049 Distributed (ad-hoc) queries now support discovery queries.
#3087 & #3091 Improve events tables performance and protect against multiple queries overwriting sliding window optimizations.
#3100 Add globbing support to the Windows `registry` table.
#3120 Add the `auid` column to all Audit-based tables.
#3115 Add status logging to AWS-based logger plugins.
### Bug fixes
#3065 Set a max size for RocksDB `MANIFEST` logs, this helps protect against very large transaction logs leading to massive on-disk files.
#3098 Fix crash when sanitizing REG_NONE types from Windows registry.
#3106 Return blank or `NULL` values for `sha`, `md5` and `sha256` when files cannot be hashed.
#3116 Fix potential deadlock with periodic database reset.
#3142 Fix reentry bug with our GLog logger sink leading to potential deadlocks.
### Config options / CLI flags changes
`--logger_min_status VALUE` Minimum level for status log recording 1=INFO, 2=WARNING, 3=ERROR
### Table changes (from 2.3.4 to 2.4.0):
Moved table `startup_items` from Darwin to All Platforms
Added table `lldp_neighbors` to POSIX-compatible Plaforms
Added table `python_packages` to POSIX-compatible Plaforms
Added column `auid` (`BIGINT_TYPE`) to table `process_events`
Added column `auid` (`BIGINT_TYPE`) to table `socket_events`
Added column `auid` (`BIGINT_TYPE`) to table `user_events`
Renamed table `syslog` to `syslog_events` on Ubuntu, CentOS (the alias `syslog` still exists)
### Breaking Table API changes
Removed column `hive` (`TEXT_TYPE`) from table `registry`
Removed column `subkey` (`TEXT_TYPE`) from table `registry`
The `hive` and `subkey` columns have been combined into a `path` column.
2017-04-06T23:02:28+00:00osquery 2.4.1osquery 2.4.12017-04-21T23:11:53+00:002017-04-21T23:11:53+00:00osquery 2.4.2osquery 2.4.22017-04-24T19:19:54+00:00## New features in 2.4.2:
### Bug fixes
#3157 Use poll over select in inotify (and auditd, udev) publisher
#3169 Adding bounds checks and key checks for appcompat shims table
#3170 Fixing stringToWstring crashes with wide character strings
#3187 Drop permissions properly on Linux (fixes `rpm_packages` on CentOS7)
#3179 Add database initialization retry
### Config options / CLI flags changes
The `host_identifier` can now take a `specified` (explicit) identifier.
`--host_identifier VALUE` Field used to identify the host running osquery (hostname, uuid, instance, ephemeral, specified)
`--specified_identifier VALUE` Field used to specify the host_identifier when set to "specified"
### Table changes (from 2.4.0 to 2.4.2):
Moved table `routes` to All Platforms
Added table `event_taps` to Darwin (Apple OS X)
Added table `time_machine_backups` to Darwin (Apple OS X)
Added table `time_machine_destinations` to Darwin (Apple OS X)
Added table `scheduled_tasks` to Microsoft Windows
Added hidden column `eid` (`TEXT_TYPE`) to all `*_events` (used for testing)
2017-04-24T19:19:54+00:00osquery 2.4.3osquery 2.4.32017-05-01T19:45:56+00:00This is a pre-release for FreeBSD's port.2017-05-01T19:45:56+00:00osquery 2.4.4osquery 2.4.42017-05-12T23:50:25+00:00## New features in 2.4.4:
#3267 New SQLite functions: `md5`, `sha1`, and `sha256`
#2956 Augeas' lenses are now bundled with osquery packages
#3226 External build systems can disable YARA, TSK, or LLDB with `SKIP_` environment variables.
### Bug fixes
#3219 Fix extensions use of database during reset phase
#3248 Submodules will now update correctly on Windows
#3257 The IPv4 route gateways on Windows now work
### Table changes (from 2.4.2 to 2.4.4):
Added column `args` (`TEXT_TYPE`) to table `startup_items`
Added column `channel` (`INTEGER_TYPE`) to table `wifi_status`
Added column `channel` (`INTEGER_TYPE`) to table `wifi_survey`
Added table `pkg_packages` to FreeBSD
Added table `docker_container_labels` to POSIX-compatible Plaforms
Added table `docker_container_mounts` to POSIX-compatible Plaforms
Added table `docker_container_networks` to POSIX-compatible Plaforms
Added table `docker_container_ports` to POSIX-compatible Plaforms
Added table `docker_container_processes` to POSIX-compatible Plaforms
Added table `docker_container_stats` to POSIX-compatible Plaforms
Added table `docker_containers` to POSIX-compatible Plaforms
Added table `docker_image_labels` to POSIX-compatible Plaforms
Added table `docker_images` to POSIX-compatible Plaforms
Added table `docker_info` to POSIX-compatible Plaforms
Added table `docker_network_labels` to POSIX-compatible Plaforms
Added table `docker_networks` to POSIX-compatible Plaforms
Added table `docker_version` to POSIX-compatible Plaforms
Added table `docker_volume_labels` to POSIX-compatible Plaforms
Added table `docker_volumes` to POSIX-compatible Plaforms
2017-05-12T23:50:25+00:00osquery 2.4.5osquery 2.4.52017-05-26T22:38:59+00:002017-05-26T22:38:59+00:00osquery 2.4.6osquery 2.4.62017-05-31T00:21:04+00:00## New features in 2.4.6:
This release contains a 'Rebuild the World' release of third party dependencies with bumps in most of the libraries used by osquery. As a part of this bump in third party dependencies we now make use of Clang's ThinLTO to enhance the linking experience. This release further brings in fixes to our build process to facilitate using ASAN and TSAN frameworks. Lastly this release introduces the concept of views for osquery queries, as well as SQL to_base64 and from_base64 column functions.
#3297 Windows `interface_addresses` now leverages native Win32 APIs as opposed to WMI
#3312 Add base64 encode and decoding functions
#3306 Adding a config block to create views
### Bug fixes
#3307 Fix reading past the end of buffer in fileops tests
#3308 Fix temperature sorting in darwin temperature_sensors table
#3309 Fix crash caused by boost's unhandled exception in filesystem
#3286 Fix sudoers path on FreeBSD, add fields to os_version
#3291 Fix patchlevel reporting for FreeBSD
#3322 Removing pretty printing from windows event log data
#3335 Fix invalid control character in profile.py
[Tidy] Fix all C99 warnings #3353
### Table changes (from 2.4.4 to 2.4.6):
Added table `fbsd_kmods` to FreeBSD
Added column `device` (`TEXT_TYPE`) to table `disk_events`
Added column `type` (`TEXT_TYPE`) to table `interface_addresses`
Removed column `bsd_name` (`TEXT_TYPE`) from table `disk_events`
2017-05-31T00:21:04+00:00osquery 2.4.7osquery 2.4.72017-06-09T20:26:00+00:002017-06-09T20:26:00+00:00osquery 2.5.0osquery 2.5.02017-06-14T02:16:12+00:00## New features in 2.5.0:
There are several new features and bug fixes.
#3356 Only reconfigure event publishers if configuration content changes
#3375 Add the "platform mask" to enrollment requests
#3376 Allow Linux publishers to be interrupted (previously they would stop)
#3360 Add a watchdog delay (60s) before enforcing limits to allow for log flushing
#3402 Increase max `rpm_package_files` to 64k on Linux
### Table changes (from 2.4.6 to 2.5.0):
Added table `virtual_memory_info` to Darwin (Apple OS X)
Added table `load_average` to POSIX-compatible Plaforms
Added column `local_hostname` (`TEXT_TYPE`) to table `system_info`
Added and removed several columns from Window's `drivers` table
2017-06-14T02:16:12+00:00osquery 2.11.3osquery 2.11.32017-06-14T14:44:24+00:00
## [2.11.3](https://github.com/CERT-BDF/TheHive/tree/2.11.3) (2017-06-14)
[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/debian/2.11.2-2...2.11.3)
**Fixed bugs:**
- Unable to add tasks to case template [\#239](https://github.com/CERT-BDF/TheHive/issues/239)
- Problem Start TheHive on Ubuntu 16.04 [\#238](https://github.com/CERT-BDF/TheHive/issues/238)
- MISP synchronization doesn't retrieve all events [\#236](https://github.com/CERT-BDF/TheHive/issues/236)2017-06-14T14:44:24+00:00osquery 2.5.1osquery 2.5.12017-06-19T21:25:36+00:002017-06-19T21:25:36+00:00osquery 2.5.2osquery 2.5.22017-06-30T21:46:13+00:002017-06-30T21:46:13+00:00osquery 2.12.0osquery 2.12.02017-07-05T08:34:42+00:00## [2.12.0](https://github.com/CERT-BDF/TheHive/tree/2.12.0)
[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/2.11.3...2.12.0)
**Implemented enhancements:**
- Sort the analyzers list in observable details page [\#245](https://github.com/CERT-BDF/TheHive/issues/245)
- More options to sort cases [\#243](https://github.com/CERT-BDF/TheHive/issues/243)
- Alert Preview and management improvements [\#232](https://github.com/CERT-BDF/TheHive/issues/232)
- Ability to Reopen Tasks [\#156](https://github.com/CERT-BDF/TheHive/issues/156)
- Display short reports on the Observables tab [\#131](https://github.com/CERT-BDF/TheHive/issues/131)
- Custom fields for case template [\#12](https://github.com/CERT-BDF/TheHive/issues/12)
- Show case status and category \(FP, TP, IND\) in related cases [\#229](https://github.com/CERT-BDF/TheHive/issues/229)
- Open External Links in New Tab [\#228](https://github.com/CERT-BDF/TheHive/issues/228)
- Observable analyzers view reports. [\#191](https://github.com/CERT-BDF/TheHive/issues/191)
- Specifying tags on statistics page or performing a search [\#186](https://github.com/CERT-BDF/TheHive/issues/186)
- Choose case template while importing events from MISP [\#175](https://github.com/CERT-BDF/TheHive/issues/175)
- Use local font files [\#250](https://github.com/CERT-BDF/TheHive/issues/250)
**Fixed bugs:**
- Fix case metrics malformed definitions [\#248](https://github.com/CERT-BDF/TheHive/issues/248)
- Sorting alerts by severity fails [\#242](https://github.com/CERT-BDF/TheHive/issues/242)
- Alerting Panel: Typo Correction [\#240](https://github.com/CERT-BDF/TheHive/issues/240)
- files in alerts are limited to 32kB [\#237](https://github.com/CERT-BDF/TheHive/issues/237)
- Alert can contain inconsistent data [\#234](https://github.com/CERT-BDF/TheHive/issues/234)
- Search do not work with non-latin characters [\#223](https://github.com/CERT-BDF/TheHive/issues/223)
- report status not updated after finish [\#212](https://github.com/CERT-BDF/TheHive/issues/212)
- A locked user can use the API to create / delete / list cases \(and more\) [\#251](https://github.com/CERT-BDF/TheHive/issues/251)2017-07-05T08:34:42+00:00osquery 2.5.3osquery 2.5.32017-07-18T07:28:40+00:002017-07-18T07:28:40+00:00osquery 2.6.0osquery 2.6.02017-07-24T23:38:41+00:00This is the next stable build of osquery, ready for production. This release fixes many bugs in the Windows version vastly improving stability and some tables. The SQLite version was also bumped to 3.19.3 and improvements were made to inotify eventing on linux. The preferences table on Darwin has also been changed and it's core functionality moved to a new plist table. See (#3455) for more details as this may require updates to any scheduled queries that use this table. For more complete release notes, see the highlights below.
**Several bug fixes pertaining to Windows:**
* (#3478) Fixed a crash in interface_details - If WMI data was empty, an invalid access occurred.
* (#3481) Choco build output directory change - Building a package will now drop you in the directory you started in, not the build directory.
* (#3475) Fixed worker respawn logic - Killed workers were not being respawned correctly due to a lack of early exit.
* (#3470) system_info FQDN - The system_info table on Windows will now return the full FQDN, not just the host name.
* (#3484) Additional install locations - The programs table checks more locations to find installed applications.
* (#3431) Skip tests on Windows - It's now possible to skip building tests via a environment variable on Windows.
* (#3444) Autoexec - Added a new table to find auto-executing programs.
* (#3436) IE Extensions - Added a new table to list extensions installed in IE.
**A few bug fixes to POSIX/macOS**
* (#3454) (#3473) (#3476) High Sierra related fixes - Fixed a bug where the local clang-format wasn't being used and instead of the system one was called. Also fixed a globbing bug caused by a new file ordering on APFS systems.
* (#3480) Mount event on Darwin - FSEvents now also catches mount events and these alerts go through the same pub sub flow with the action "MOUNTED".
**General Updates**
* (#3488) Changes to plugin failures - All plugins will now fail if one fails. This ensures plugins are in a good state when initialization finishes.
* (#3485) Update to SQLite - SQLite version bumped to 3.19.3
* (#3489) TSAN fixes - Some general TSAN issues addressed.
* (#3487) Don't ignore SIGCHLD - Stop ignoring the SIGCHLD interrupt to exit faster.
* (#3459) Updates to inotify - Logic improved around add/removing subscribers in the inotify eventer.
* (#3469) Fix TLS Config Update - Fixes TLS update and sets the refresh period to one hour.
* (#3457) Moved pid file - The osquery pid file is now in /var/run/ on Linux and FreeBSD system.
* (#3378) Added epoch time to scheduled queries - To assist in keeping backend systems in sync with system state, an epoch decorator was added.
* (#3455) Separated preferences and plist - Preferences was split into its own table and the functionality of plist parsing was moved to a new plist table.
* (#3448) Watchdog issues resolved - There were some instances where certain flag usage would inadvertently disable the watchdog.
* (#3390) Symlink column in file table - A new column containing information on if the file is a symlink.2017-07-24T23:38:41+00:00osquery 2.12.1osquery 2.12.12017-08-01T08:41:55+00:00## [2.12.1](https://github.com/CERT-BDF/TheHive/tree/2.12.1)
[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/2.12.0...2.12.1)
**Implemented enhancements:**
- Fix warnings in debian package [\#267](https://github.com/CERT-BDF/TheHive/issues/267)
- Merging alert into existing case does not merge alert description into case description [\#255](https://github.com/CERT-BDF/TheHive/issues/255)
**Fixed bugs:**
- Case similarity reports merged cases [\#272](https://github.com/CERT-BDF/TheHive/issues/272)
- Closing a case with an open task does not dismiss task in "My tasks" [\#269](https://github.com/CERT-BDF/TheHive/issues/269)
- API: cannot create alert if one alert artifact contains the IOC field set [\#268](https://github.com/CERT-BDF/TheHive/issues/268)
- Can't get logs of a task via API [\#259](https://github.com/CERT-BDF/TheHive/issues/259)
- Add multiple attachments in a single task log doesn't work [\#257](https://github.com/CERT-BDF/TheHive/issues/257)
- Cortex Connector Not Found [\#256](https://github.com/CERT-BDF/TheHive/issues/256)
- TheHive doesn't send the file name to Cortex [\#254](https://github.com/CERT-BDF/TheHive/issues/254)
- Renaming of users does not work [\#249](https://github.com/CERT-BDF/TheHive/issues/249)
2017-08-01T08:41:55+00:00osquery 2.6.1osquery 2.6.12017-08-04T01:40:47+00:002017-08-04T01:40:47+00:00osquery 2.7.0osquery 2.7.02017-08-22T19:02:56+00:00## New features in 2.7.0
#3506 FSEvents on macOS will monitor mount events within already-monitored directories
#3503 OpenBSM events are monitored as `process_events` on macOS
#3265 Add RapidJSON integration as a boost property tree replacement
#3530 Implement excluded paths for FIM for Linux and macOS
### Bug fixes
#3517 Wait for each extension before respawning
#3553 and #3552 Fixing memory leaks in virtual tables
#3534 Improve macOS process `start_time` column
#3539 Fix sizes for `block_devices` on macOS and Linux
#3574 Display correct UID for proceses for Domain Users on Windows
#3580 Fix handling of multiple LIKE and GLOB predicates*
* When using `LIKE` and `GLOB` with `OR` in query predicates the SQLite optimizer may replace `TEXT` fields with incorrect values, causing unexpected behavior for tables like `file` expecting globbing input for path names.
### Table changes (from 2.6.0 to 2.7.0)
Added table `process_memory_map` to All Platforms (from POSIX)
Added table `device_firmware` to Darwin (Apple OS X)
Added table `gatekeeper` to Darwin (Apple OS X)
Added table `gatekeeper_approved_apps` to Darwin (Apple OS X)
Added table `shared_folders` to Darwin (Apple OS X)
Added table `sharing_preferences` to Darwin (Apple OS X)
Added table `certificates` to MacOS and Windows
Added table `user_events` to POSIX-compatible Plaforms
Added table `ec2_instance_metadata` to Ubuntu, CentOS
Added table `ec2_instance_tags` to Ubuntu, CentOS
Added column `block_size` (`INTEGER_TYPE`) to table `block_devices`
Added column `cwd` (`TEXT_TYPE`) to table `process_events`
Added column `status` (`BIGINT_TYPE`) to table `process_events`
Added column `action` (`TEXT_TYPE`) to table `scheduled_tasks`
Added column `class` (`TEXT_TYPE`) to table `usb_devices`
Added column `protocol` (`TEXT_TYPE`) to table `usb_devices`
Added column `subclass` (`TEXT_TYPE`) to table `usb_devices`
2017-08-22T19:02:56+00:00osquery 2.13.0osquery 2.13.02017-09-15T14:00:09+00:00## [2.13](https://github.com/CERT-BDF/TheHive/tree/2.13) (2017-09-15)
[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/2.12.1...2.13)
**Implemented enhancements:**
- Group ownership in Docker image prevents running on OpenShift [\#307](https://github.com/CERT-BDF/TheHive/issues/307)
- Improve the content of alert flow items [\#304](https://github.com/CERT-BDF/TheHive/issues/304)
- Add a basic support for webhooks [\#293](https://github.com/CERT-BDF/TheHive/issues/293)
- Add basic authentication to Stream API [\#291](https://github.com/CERT-BDF/TheHive/issues/291)
- Add Support for Play 2.6.x and Elasticsearch 5.x [\#275](https://github.com/CERT-BDF/TheHive/issues/275)
- Fine grained user permissions for API access [\#263](https://github.com/CERT-BDF/TheHive/issues/263)
- Alert Pane: Catch Incorrect Keywords [\#241](https://github.com/CERT-BDF/TheHive/issues/241)
- Specify multiple AD servers in TheHive configuration [\#231](https://github.com/CERT-BDF/TheHive/issues/231)
- Export cases in MISP events [\#52](https://github.com/CERT-BDF/TheHive/issues/52)
**Fixed bugs:**
- Download attachment with non-latin filename [\#302](https://github.com/CERT-BDF/TheHive/issues/302)
- Undefined threat level from MISP events becomes severity "4" [\#300](https://github.com/CERT-BDF/TheHive/issues/300)
- File name is not displayed in observable conflict dialog [\#295](https://github.com/CERT-BDF/TheHive/issues/295)
- A colon punctuation mark in a search query results in 500 [\#285](https://github.com/CERT-BDF/TheHive/issues/285)
- Previewing alerts fails with "too many substreams open" due to case similarity process [\#280](https://github.com/CERT-BDF/TheHive/issues/280)
**Closed issues:**
- Threat level/severity code inverted between The Hive and MISP [\#292](https://github.com/CERT-BDF/TheHive/issues/292)2017-09-15T14:00:09+00:00osquery 2.8.0osquery 2.8.02017-09-19T03:47:29+00:00# New features in 2.8.0
This release merges the osqueryi shell into the osqueryd daemon. Both binaries will still be shipped with all platforms packages and the osqueryi binary is simply a copy of osqueryd binary. The core logic of the shell meerly checks the name of the running executable, and if it's osqueryi we launch into the shell. This release also sees various changes to our third party dependencies. Firstly we have dropped snappy and LZ4 from our dependency chain in favor of ZSTD, so these packages will no longer be required for builds. Further we have upgraded all platforms to make use of Boost 1.65.0, and finally we have successfully seen Firehose/Kinesis logging brought to the Windows platform. Lastly a few hardening changes to the RocksDB interface will ensure a better and more robust interface with the local caching database and strive to recover from database corruption.
#3635 RocksDB interface has been extended to include a 'backup' and recover feature
#3641 Firehose/Kinesis logging is now supported on Windows
## Bug fixes
#3613 Fixed boost 1.65.0 builds for macos
#3599 Addressed an issue in the Kinesis/Firehose record size check
#3628 Wrapped the Windows shutdown event logic in a Mutex
#3651 New query counter added to ignore initial results for differential querying
#3661 Fixed listening_ports table to use readlink instead of readpath
#3663 Fixed RocksDB interface to avoid calling DB::Flush so often
#3662 Fixed debug info breakage introduced via binary merging
#3673 Fixed builds linking against shared objects
#3671 Fixed bug which had changed enrollment tests path
#3685 Use PackageKit to better enumerate package receipts on macos
#3698 Address shutdown behavior on Windows to ensure safe service stop
## Table changes (from 2.7.0 to 2.8.0)
Added table `python_packages` to All Platforms
Added table `chocolatey_packages` to Microsoft Windows
Added table `curl` to POSIX-compatible Plaforms
Added column `friendly_name` (`TEXT_TYPE`) to table `interface_addresses`
Added column `friendly_name` (`TEXT_TYPE`) to table `interface_details`
Added column `host` (`TEXT_TYPE`) to table `preferences`
Removed table `process_file_events` from Darwin (Apple OS X)
Removed table `python_packages` from POSIX-compatible Plaforms
2017-09-19T03:47:29+00:00osquery 2.8.1osquery 2.8.12017-09-29T17:24:01+00:00## New features in 2.8.1
This is largely a break-fix release addressing an issue with Kinesis/Firehose logging format. This release also sees a few small changes to the newly designed website as well as a small overhaul to the filesystem abstraction to make use of boosts `path` objects.
## Bug fixes
#3746 Check Crypt API values for `nullptr` before using in `disk_encryption` table
#3743 Add newline character between loglines for Firehose/Kinesis
## Table changes (from 2.8.0 to 2.8.1)
Added column `last_opened_time` (`DOUBLE_TYPE`) to table `apps`2017-09-29T17:24:01+00:00osquery 2.13.1osquery 2.13.12017-10-03T08:24:46+00:00[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/2.13.0...2.13.1)
**Fixed bugs:**
- Tasks Tab Elasticsearch exception: Fielddata is disabled on text fields by default. Set fielddata=true on \[title\] [\#311](https://github.com/CERT-BDF/TheHive/issues/311)2017-10-03T08:24:46+00:00osquery 2.9.0osquery 2.9.02017-10-05T00:37:07+00:00## New features in 2.9.0
This is a security release, it includes fixes for weaknesses in several virtual tables.
Please check out the new [`SECURITY.md`](https://github.com/facebook/osquery/blob/master/SECURITY.md) security issues tracker for more details. This release has updated several dependency formulas. The focus for those updates was also security related. While it is unclear if weaknesses in dependencies have an exact adverse effect on osquery, it is important to update them regardless. These updates mean a stronger and safer set of binary versions available on the https://osquery.io downloads page.
## Bug fixes
#3785 (**CVE-2017-15026**) Use sanitized SQL for `ie_extensions` on Windows
#3783 Drop temporary privileges to the intended user within `safari_extensions`
#3782 (**CVE-2017-15027**) Use the owner of parent path in `dropToParent` event if the parent is a symlink
#3781 (**CVE-2017-15028**) Drop temporary privileges to the intended user within `known_hosts`
The notable dependency updates include:
#3780 `libmagic` updated to 5.32
#3775 `libxml2` updated to 2.9.5
#3767 `augeas` updated to 1.8.1
#3770 `libarchive` updated to 3.3.3
2017-10-05T00:37:07+00:00osquery 2.9.1osquery 2.9.12017-10-17T06:31:31+00:002017-10-17T06:31:31+00:00osquery 2.9.2osquery 2.9.22017-10-21T21:54:01+00:002017-10-21T21:54:01+00:00osquery 2.10.0osquery 2.10.02017-10-24T18:45:28+00:00## New features in 2.10.0
We've ported our HTTP client to Boost Beast to allow for more meaningful TLS errors and support for HTTP proxies.
#3623 Use Boost Beast as the HTTP client implementation (previously we used cpp-netlib)
## Bug fixes
#3862 Lock access to individual SQL databases
#3856 Fix extended_schema on Windows (previously all extended columns were HIDDEN)
## Table changes (from 2.9.0 to 2.10.0)
Added table `key_events` to Darwin (Apple OS X)
Added table `authenticode` to Microsoft Windows
Added table `logical_drives` to Microsoft Windows
Added table `physical_disk_performance` to Microsoft Windows
Added column `version` (`TEXT_TYPE`) to table `usb_devices`
2017-10-24T18:45:28+00:00osquery 2.10.1osquery 2.10.12017-11-01T17:26:51+00:002017-11-01T17:26:51+00:00osquery 2.10.2osquery 2.10.22017-11-09T21:22:08+00:00## New features in 2.10.2
#3884 The macOS firewall exception URLs are now included in `alf_exceptions`
The systemd service unit includes a post-init script to reload the units properly.
## Bug fixes
#3892 Use better precision for calculating process start time on macOS
#3917 Event tap publisher resource management fixes
## Table changes (from 2.10.0 to 2.10.2)
Added table `curl` to All Platforms
Added table `curl_certificate` to All Platforms
Added table `pipes` to Microsoft Windows
Added column `dst_port` (`TEXT_TYPE`) to table `iptables`
Added column `src_port` (`TEXT_TYPE`) to table `iptables`
2017-11-09T21:22:08+00:00osquery 2.10.3osquery 2.10.32017-11-20T16:32:25+00:00This is a pre-release for internal testing of extensions changes.2017-11-20T16:32:25+00:00osquery 2.10.4osquery 2.10.42017-11-27T19:56:55+00:002017-11-27T19:56:55+00:00osquery 2.13.2osquery 2.13.22017-12-05T13:50:04+00:00[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/2.13.1...2.13.2)
**Fixed bugs:**
- Security issue on Play 2.6.5 [\#356](https://github.com/CERT-BDF/TheHive/issues/356)
- Incorrect stats: non-IOC observables counted as IOC and IOC word displayed twice [\#347](https://github.com/CERT-BDF/TheHive/issues/347)
- Deleted Observables, Show up on the statistics tab under Observables by Type [\#343](https://github.com/CERT-BDF/TheHive/issues/343)
- Statistics on metrics doesn't work [\#342](https://github.com/CERT-BDF/TheHive/issues/342)
- Error on custom fields format when merging cases [\#331](https://github.com/CERT-BDF/TheHive/issues/331)2017-12-05T13:50:04+00:00osquery 3.0.1osquery 3.0.12017-12-07T15:42:44+00:00## [3.0.1](https://github.com/CERT-BDF/TheHive/tree/3.0.1) (2017-12-07)
[Full Changelog](https://github.com/CERT-BDF/TheHive/compare/3.0.0...3.0.1)
**Fixed bugs:**
- MISP Event Export Error [\#387](https://github.com/CERT-BDF/TheHive/issues/387)
- During migration, dashboards are not created [\#386](https://github.com/CERT-BDF/TheHive/issues/386)
- Error when configuring multiple ElasticSearch nodes [\#383](https://github.com/CERT-BDF/TheHive/issues/383)2017-12-07T15:42:44+00:00osquery 2.11.0osquery 2.11.02017-12-18T22:22:12+00:00## New features in 2.11.0
This version adds more features to osquery extensions. For a few examples, the Thrift API
calls now enforce a 5 minutes maximum execution time to protect osquery from hung
extensions (#3847); extension processes that are autoloaded, will respawn if they exit
prematurely (#3944).
We now depend on the newest `libaugeas` and have altered our integration to achieve
much better performance (#3911). Several changes in the new Augeas version were designed for
osquery's use cases.
Finally, along with the bug and features below, this version adds more care to Windows
Services and MSI packaging (#3927).
#3921 Kafka SSL support
#3814 Hash table cache
#3887 Windows Event Log (as a logger plugin) support
#4005 Non-blacklistable queries
## Bug fixes
#3909 Print correct address family id for AF_UNIX sockets
#3938 Remove 'removed' results correctly
#3943 Stop renaming worker and extension argv[0]
#3958 Fix header calculation with HTTP client and AWS Firehose
#3979 Only daemon-reload if systemd is running
#3985 Removing newline from Windows Event Log lines
#4001 Remove invalid assumptions about status logging (refactor status logging)
## Table changes (from 2.10.2 to 2.11.0)
Added table `groups` to All Platforms
Added table `intel_me_info` to Linux and Windows
Added table `shadow` to Linux
Added column `blacklisted` (`INTEGER_TYPE`) to table `osquery_schedule`
Added column `install_location` (`TEXT_TYPE`) to table `programs`
Added column `type` (`TEXT_TYPE`) to table `users`
Renamed table `key_events` to `user_interaction_events` on MacOS2017-12-18T22:22:12+00:00osquery 2.11.1osquery 2.11.12017-12-24T06:16:56+00:00This tag includes dependency changes to accommodate Homebrew builds.2017-12-24T06:16:56+00:00osquery 2.11.2osquery 2.11.22017-12-30T20:34:49+00:00This is a small release that adds mitigations for #3984.
It also includes a new `crashes` table for Windows, a bugfix #4022 for `startup_items` not including non-existent paths, and upgraded our internal dependencies for boost (1.66) and thrift (0.11).
This release is also the first using the new ASL2.0 and GPL2 dual license.2017-12-30T20:34:49+00:00osquery 3.0.0osquery 3.0.02018-01-16T04:33:17+00:00Welcome to the 3.0.0 series! In this series we'll be moving fast to incorporate new features that improve performance and safety. Minor releases will indicate new landed features. We'll highlight what to expect for compatibility in the release notes for each version.
In this kick-off tag, we're ratcheting the build "runtime" that is installed with `make deps`. On macOS and Linux this is completely rebuilt to minimize the final binary size. We have also nitpicked compatibility options for macOS and believe this version is much safer for older versions, below 10.13. Finally, this version pays attention to OS and package manager maintainers. It will be a struggle to find the correct dependencies, but 3.0.0 supports a traditional `cmake` build if the `SKIP_DEPS` environment variable exists.2018-01-16T04:33:17+00:00osquery 3.1.0osquery 3.1.02018-02-08T00:46:43+00:00See the 3.0.0 release notes about the 3.0 series!
This release includes the Linux Audit redesign. This redesign is faster, more reliable, and more extensible!2018-02-08T00:46:43+00:00osquery 3.2.0osquery 3.2.02018-03-21T16:47:25+00:002018-03-21T16:47:25+00:00osquery 3.0.2osquery 3.0.22018-03-23T10:35:12+00:00## [3.0.2](https://github.com/TheHive-Project/TheHive/tree/3.0.2) (2017-12-20)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.1...3.0.2)
**Implemented enhancements:**
- Add multiline/multi entity graph to dashboards [\#399](https://github.com/TheHive-Project/TheHive/issues/399)
- Can not configure ElasticSearch authentication [\#384](https://github.com/TheHive-Project/TheHive/issues/384)
**Fixed bugs:**
- "Mark as Sighted" Option not available for "File" observable type [\#400](https://github.com/TheHive-Project/TheHive/issues/400)2018-03-23T10:35:12+00:00osquery 3.0.3osquery 3.0.32018-03-23T10:35:37+00:00## [3.0.3](https://github.com/TheHive-Project/TheHive/tree/3.0.3) (2018-01-10)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.2...3.0.3)
**Fixed bugs:**
- THP-SEC-ADV-2017-001: Privilege Escalation in all Versions of TheHive [\#408](https://github.com/TheHive-Project/TheHive/issues/408)2018-03-23T10:35:37+00:00osquery 3.0.4osquery 3.0.42018-03-23T10:36:17+00:00## [3.0.4](https://github.com/TheHive-Project/TheHive/tree/3.0.4) (2018-02-05)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.3...3.0.4)
**Implemented enhancements:**
- Make alerts searchable through the global search field [\#456](https://github.com/TheHive-Project/TheHive/issues/456)
- Make counts on Counter dashboard's widget clickable [\#455](https://github.com/TheHive-Project/TheHive/issues/455)
- MISP feeds cause the growing of ES audit docs [\#450](https://github.com/TheHive-Project/TheHive/issues/450)
- Case metrics sort [\#418](https://github.com/TheHive-Project/TheHive/issues/418)
- Filter MISP Events Using MISP Tags & More Before Creating Alerts [\#370](https://github.com/TheHive-Project/TheHive/issues/370)
- OAuth2 single sign-on implementation \(BE + FE\) [\#430](https://github.com/TheHive-Project/TheHive/pull/430) ([saibot94](https://github.com/saibot94))
**Fixed bugs:**
- Remove uppercase filter on template name [\#464](https://github.com/TheHive-Project/TheHive/issues/464)
- Fix the alert bulk update timeline message [\#463](https://github.com/TheHive-Project/TheHive/issues/463)
- "too many substreams open" on alerts [\#462](https://github.com/TheHive-Project/TheHive/issues/462)
- Fix MISP export error dialog column's wrap [\#460](https://github.com/TheHive-Project/TheHive/issues/460)
- More than 20 users prevents assignment in tasks [\#459](https://github.com/TheHive-Project/TheHive/issues/459)
- Type is not used when generating alert id [\#457](https://github.com/TheHive-Project/TheHive/issues/457)
- Fix link to default report templates [\#454](https://github.com/TheHive-Project/TheHive/issues/454)
- Make dashboard donuts clickable [\#453](https://github.com/TheHive-Project/TheHive/issues/453)
- Refresh custom fields on open cases by background changes [\#440](https://github.com/TheHive-Project/TheHive/issues/440)
- Bug: Case metrics not shown when creating case from template [\#417](https://github.com/TheHive-Project/TheHive/issues/417)
- Observable report taxonomies bug [\#409](https://github.com/TheHive-Project/TheHive/issues/409)
**Closed issues:**
- GET request with Content-Type ends up in HTTP 400 [\#438](https://github.com/TheHive-Project/TheHive/issues/438)
- Feature Request: Ability to bulk upload files as observables. [\#435](https://github.com/TheHive-Project/TheHive/issues/435)
- Add metadata to MISP event when exporting case from TheHive [\#433](https://github.com/TheHive-Project/TheHive/issues/433)
- How to limit by date amount of events pulled from MISP initially? [\#432](https://github.com/TheHive-Project/TheHive/issues/432)2018-03-23T10:36:17+00:00osquery 3.0.5osquery 3.0.52018-03-23T10:36:36+00:00## [3.0.5](https://github.com/TheHive-Project/TheHive/tree/3.0.5) (2018-02-08)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.4...3.0.5)
**Fixed bugs:**
- Importing Template Button Non-Functional bug [\#404](https://github.com/TheHive-Project/TheHive/issues/404)
- No reports available for "domain" type bug [\#409](https://github.com/TheHive-Project/TheHive/issues/409)2018-03-23T10:36:36+00:00osquery 3.2.1osquery 3.2.12018-03-29T20:40:24+00:002018-03-29T20:40:24+00:00osquery 3.2.2osquery 3.2.22018-03-29T23:16:04+00:002018-03-29T23:16:04+00:00osquery 3.0.7osquery 3.0.72018-04-03T15:40:21+00:00## [3.0.7](https://github.com/TheHive-Project/TheHive/tree/3.0.7) (2018-03-29)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.6...3.0.7)
**Implemented enhancements:**
- Delete Case [\#100](https://github.com/TheHive-Project/TheHive/issues/100)
**Fixed bugs:**
- Display only cortex servers available for each analyzer, in observable details page [\#513](https://github.com/TheHive-Project/TheHive/issues/513)
- Can't save case template in 3.0.6 [\#502](https://github.com/TheHive-Project/TheHive/issues/502)2018-04-03T15:40:21+00:00osquery 3.0.6osquery 3.0.62018-04-03T15:41:06+00:00## [3.0.6](https://github.com/TheHive-Project/TheHive/tree/3.0.6) (2018-03-08)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.5...3.0.6)
**Implemented enhancements:**
- Add compatibility with Cortex 2 [\#466](https://github.com/TheHive-Project/TheHive/issues/466)
**Fixed bugs:**
- Tasks are stripped when merging cases [\#489](https://github.com/TheHive-Project/TheHive/issues/489)2018-04-03T15:41:06+00:00osquery 3.0.8osquery 3.0.82018-04-13T13:32:33+00:00## [3.0.8](https://github.com/TheHive-Project/TheHive/tree/3.0.8) (2018-04-04)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.7...3.0.8)
**Fixed bugs:**
- Mini reports is not shown when Cortex 2 is used [\#526](https://github.com/TheHive-Project/TheHive/issues/526)
- Session collision when TheHive & Cortex 2 share the same URL [\#525](https://github.com/TheHive-Project/TheHive/issues/525)
- "Run all" in single observable context does not work [\#524](https://github.com/TheHive-Project/TheHive/issues/524)
- Error on displaying analyzers name in report template admin page [\#523](https://github.com/TheHive-Project/TheHive/issues/523)
- Job Analyzer is no longer named in 3.0.7 with Cortex2 [\#521](https://github.com/TheHive-Project/TheHive/issues/521)
**Merged pull requests:**
- Add ElasticSearch file descriptor limit to docker-compose.yml [\#505](https://github.com/TheHive-Project/TheHive/pull/505) ([flmsc](https://github.com/flmsc))2018-04-13T13:32:33+00:00osquery 3.0.9osquery 3.0.92018-04-13T13:32:55+00:00## [3.0.9](https://github.com/TheHive-Project/TheHive/tree/3.0.9)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.8...3.0.9)
**Fixed bugs:**
- Cortex connection can fail without any error log [\#543](https://github.com/TheHive-Project/TheHive/issues/543)
- PhishTank Cortex Tag is transparent [\#535](https://github.com/TheHive-Project/TheHive/issues/535)
- Naming inconsistencies in Live-Channel [\#531](https://github.com/TheHive-Project/TheHive/issues/531)
- Error when trying to analyze a filename with the Hybrid Analysis analyzer [\#530](https://github.com/TheHive-Project/TheHive/issues/530)
- Long Report isn't shown [\#527](https://github.com/TheHive-Project/TheHive/issues/527)
- Artifacts' sighted flags are not merged when merging cases [\#518](https://github.com/TheHive-Project/TheHive/issues/518)
- TheHive MISP cert validation, the trustAnchors parameter must be non-empty [\#452](https://github.com/TheHive-Project/TheHive/issues/452)
**Closed issues:**
- The Hive - MISP SSL configuration: General SSLEngine problem [\#544](https://github.com/TheHive-Project/TheHive/issues/544)
- Dropdown menu for case templates doesnt have scroll [\#541](https://github.com/TheHive-Project/TheHive/issues/541)
**Merged pull requests:**
- Update spacing for elasticsearch section in docker-compose yml file [\#539](https://github.com/TheHive-Project/TheHive/pull/539) ([jbarlow-mcafee](https://github.com/jbarlow-mcafee))2018-04-13T13:32:55+00:00osquery 3.2.3osquery 3.2.32018-04-18T17:51:06+00:002018-04-18T17:51:06+00:00osquery 3.2.4osquery 3.2.42018-04-25T03:26:12+00:002018-04-25T03:26:12+00:00osquery 3.2.5osquery 3.2.52018-05-11T21:30:45+00:002018-05-11T21:30:45+00:00osquery 3.2.6osquery 3.2.62018-05-22T21:10:54+00:002018-05-22T21:10:54+00:00osquery 3.0.10osquery 3.0.102018-06-08T13:06:23+00:00## [3.0.10](https://github.com/TheHive-Project/TheHive/tree/3.0.10) (2018-05-29)
[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.9...3.0.10)
**Implemented enhancements:**
- Rotate logs [\#579](https://github.com/TheHive-Project/TheHive/issues/579)
- Send caseId to Cortex analyzer [\#564](https://github.com/TheHive-Project/TheHive/issues/564)
- Poll for connectors status and display [\#563](https://github.com/TheHive-Project/TheHive/issues/563)
- Sort related cases by related artifacts amount [\#548](https://github.com/TheHive-Project/TheHive/issues/548)
- Time Calculation for individual tasks [\#546](https://github.com/TheHive-Project/TheHive/issues/546)
**Fixed bugs:**
- Wrong error message when creating a observable with invalid data [\#592](https://github.com/TheHive-Project/TheHive/issues/592)
- Analyzer name not reflected in modal view of mini-reports [\#586](https://github.com/TheHive-Project/TheHive/issues/586)
- Invalid searches lead to read error messages [\#584](https://github.com/TheHive-Project/TheHive/issues/584)
- Merge case by ID brings red error message if not a number in textfield [\#583](https://github.com/TheHive-Project/TheHive/issues/583)
- Open cases not listed after deletion of merged case in UI [\#557](https://github.com/TheHive-Project/TheHive/issues/557)
- Making dashboards private makes them "invisible" [\#555](https://github.com/TheHive-Project/TheHive/issues/555)
- MISP Synchronisation error [\#522](https://github.com/TheHive-Project/TheHive/issues/522)
- Short Report is not shown on observables \(3.0.8\) [\#512](https://github.com/TheHive-Project/TheHive/issues/512)
- Artifacts reports are not merged when merging cases [\#446](https://github.com/TheHive-Project/TheHive/issues/446)
**Closed issues:**
- Max Age Filter Not Working? [\#577](https://github.com/TheHive-Project/TheHive/issues/577)
- Support X-Pack authentication/encryption for elastic [\#570](https://github.com/TheHive-Project/TheHive/issues/570)
- Order the cases list by custom field \[Feature Request\] [\#567](https://github.com/TheHive-Project/TheHive/issues/567)
- Using Postman to test the API, getting "No CSRF token found in headers" [\#549](https://github.com/TheHive-Project/TheHive/issues/549)2018-06-08T13:06:23+00:00osquery 3.2.7osquery 3.2.72018-06-11T21:04:32+00:002018-06-11T21:04:32+00:00osquery 3.2.8osquery 3.2.82018-06-13T20:53:05+00:002018-06-13T20:53:05+00:00osquery 3.2.9osquery 3.2.92018-06-19T22:49:38+00:002018-06-19T22:49:38+00:00osquery 3.1.0-RC1osquery 3.1.0-RC12018-07-31T12:29:50+00:00[Full Changelog](https://github.com/TheHive-Project/TheHive/compare/3.0.10...3.1.0-RC1)
**Implemented enhancements:**
- Display drop-down for custom fields sorted alphabetically [\#653](https://github.com/TheHive-Project/TheHive/issues/653)
- Custom fields in Alerts? [\#635](https://github.com/TheHive-Project/TheHive/issues/635)
- Check Cortex authentication in status page [\#625](https://github.com/TheHive-Project/TheHive/issues/625)
- Revamp the search section capabilities [\#620](https://github.com/TheHive-Project/TheHive/issues/620)
- New TheHive-Project repository [\#618](https://github.com/TheHive-Project/TheHive/issues/618)
- Add PAP to case to indicate which kind of action is allowed [\#616](https://github.com/TheHive-Project/TheHive/issues/616)
- Ability to execute active response on any element of TheHive [\#609](https://github.com/TheHive-Project/TheHive/issues/609)
- Consider providing checksums for the release files [\#590](https://github.com/TheHive-Project/TheHive/issues/590)
- Start Task - Button [\#540](https://github.com/TheHive-Project/TheHive/issues/540)
- Handling malware as zip protected file [\#538](https://github.com/TheHive-Project/TheHive/issues/538)
- Auto-refresh for Dashboards [\#476](https://github.com/TheHive-Project/TheHive/issues/476)
- Assign Tasks to users from the Tasks tab [\#426](https://github.com/TheHive-Project/TheHive/issues/426)
- Make The Hive MISP integration sharing vs pull configurable [\#374](https://github.com/TheHive-Project/TheHive/issues/374)
- MISP Sharing Improvements [\#366](https://github.com/TheHive-Project/TheHive/issues/366)
- Output of analyzer as new observable [\#246](https://github.com/TheHive-Project/TheHive/issues/246)
- Ability to have nested tasks [\#148](https://github.com/TheHive-Project/TheHive/issues/148)
- Single-Sign On support [\#354](https://github.com/TheHive-Project/TheHive/issues/354)
**Fixed bugs:**
- Default value of custom fields are not saved [\#649](https://github.com/TheHive-Project/TheHive/issues/649)
- Attachments with character "\#" in the filename are wrongly proceesed [\#645](https://github.com/TheHive-Project/TheHive/issues/645)
- Session does not expire correctly [\#640](https://github.com/TheHive-Project/TheHive/issues/640)
- Dashboards contain analyzer IDs instead of correct names [\#608](https://github.com/TheHive-Project/TheHive/issues/608)
- Error with Single Sign-On on TheHive with X.509 Certificates [\#600](https://github.com/TheHive-Project/TheHive/issues/600)
- Entity case XXXXXXXXXX not found - After deleting case [\#534](https://github.com/TheHive-Project/TheHive/issues/534)
- Artifacts reports are not merged when merging cases [\#446](https://github.com/TheHive-Project/TheHive/issues/446)
- If cortex modules fails in some way, it is permanently repolled by TheHive [\#324](https://github.com/TheHive-Project/TheHive/issues/324)
- Previewing alerts fails with "too many substreams open" due to case similarity process [\#280](https://github.com/TheHive-Project/TheHive/issues/280)
- File upload when /tmp is full [\#321](https://github.com/TheHive-Project/TheHive/issues/321)
- StreamSrv: Unexpected message : StreamNotFound [\#414](https://github.com/TheHive-Project/TheHive/issues/414)
**Merged pull requests:**
- fix bug in AlertListCtrl [\#642](https://github.com/TheHive-Project/TheHive/pull/642) ([billmurrin](https://github.com/billmurrin))
- flag for Windows env [\#641](https://github.com/TheHive-Project/TheHive/pull/641) ([billmurrin](https://github.com/billmurrin))
- 426 - assign tasks to users from tasks tab [\#628](https://github.com/TheHive-Project/TheHive/pull/628) ([billmurrin](https://github.com/billmurrin))
- Fix installation links [\#603](https://github.com/TheHive-Project/TheHive/pull/603) ([Viltaria](https://github.com/Viltaria))
2018-07-31T12:29:50+00:00osquery 3.3.0osquery 3.3.02018-08-06T17:27:49+00:002018-08-06T17:27:49+00:00osquery 3.3.1osquery 3.3.12018-09-19T17:48:50+00:002018-09-19T17:48:50+00:00osquery 3.3.2osquery 3.3.22019-01-10T01:17:06+00:002019-01-10T01:17:06+00:00osquery 3.4.0osquery 3.4.02019-05-23T00:07:24+00:00This is a **Windows only** release, intended to address critical bugs and performance issues with the osquery agent on Windows systems.
The release notes are temporarily left as a "Todo", and will be drafted soon!2019-05-23T00:07:24+00:00osquery 4.0.0osquery 4.0.02019-06-29T00:10:47+00:00This is a pre-release for the new version of osquery, based on the really cool refactor done by the Facebook's team in London.
This initial version introduces CMake support, CI and packaging.
# Requirements
## Linux
Ubuntu 18.04 or better
## macOS
Mojave
## Windows
Windows 10 or Windows Server 2016
2019-06-29T00:10:47+00:00osquery 4.0.1osquery 4.0.12019-09-10T01:14:41+00:00This release has two major focuses. It is the first release since [osquery transitioned to a Linux Foundation project](https://www.linuxfoundation.org/press-release/2019/06/the-linux-foundation-announces-intent-to-form-new-foundation-to-support-osquery-community/).
It features a heavily reworked build system. This aims to provide flexibility and stability.
[Git Commits](https://github.com/osquery/osquery/compare/3.3.2...4.0.1)
### New Features / Under the Hood improvements
- Linux Audit `process_events` Implement support for fork/vfork/clone/execveat ([#5701](https://github.com/osquery/osquery/pull/5701))
- New SQLite function `regex_match` to match across columns ([#5444](https://github.com/osquery/osquery/pull/5444))
- LRU cache for syscall tracing ([#5521](https://github.com/osquery/osquery/pull/5521))
- Basic tracing via eBPF on Linux ([#5403](https://github.com/osquery/osquery/pull/5403), [#5386](https://github.com/osquery/osquery/pull/5386), [#5384](https://github.com/osquery/osquery/pull/5384))
- Experimental `kill` and `setuid` syscall tracing in Linux via eBPF ([#5519](https://github.com/osquery/osquery/pull/5519))
- New eventing (ev2) framework ([#5401](https://github.com/osquery/osquery/pull/5401))
- Improved table performance profiles ([#5187](https://github.com/osquery/osquery/pull/5187))
- macOS query pack: detect SearchAwesome malware ([#5713](https://github.com/osquery/osquery/pull/5713))
- macOS query pack: detect when a process is tapping keyboard event ([#5345](https://github.com/osquery/osquery/pull/5345))
### Build
- Refactor CMake build ([#5604](https://github.com/osquery/osquery/pull/5604), [#5627](https://github.com/osquery/osquery/pull/5627), [#5630](https://github.com/osquery/osquery/pull/5630), ([#5618](https://github.com/osquery/osquery/pull/5618)), ([#5619](https://github.com/osquery/osquery/pull/5619)))
- Refactor third-party libraries to build from source on Linux ([#5706](https://github.com/osquery/osquery/pull/5706))
- Add Azure Pipelines support for CI/CD ([#5604](https://github.com/osquery/osquery/pull/5604), [#5632](https://github.com/osquery/osquery/pull/5632), [#5626](https://github.com/osquery/osquery/pull/5626), [#5613](https://github.com/osquery/osquery/pull/5613), [#5607](https://github.com/osquery/osquery/pull/5607), [#5673](https://github.com/osquery/osquery/pull/5673), [#5610](https://github.com/osquery/osquery/pull/5610))
- Add Buck as a build system ([971bee44](https://github.com/osquery/osquery/commit/971bee44))
- Use `urllib2` to automatically handle HTTP 301/302 redirections ([#5612](https://github.com/osquery/osquery/pull/5612))
- Update MSI package to install to `Program Files` on Windows ([#5579](https://github.com/osquery/osquery/pull/54579))
- Linux custom toolchain integration ([#5759](https://github.com/osquery/osquery/pull/5759))
### Harderning
- Link binaries with Full RELRO on Linux ([#5748](https://github.com/osquery/osquery/pull/5748))
- Remove FTS features from SQLite ([#5703](https://github.com/osquery/osquery/pull/5703)) ([#5702](https://github.com/osquery/osquery/issues/5702))
- Fix SQLite API usage errors ([#5551](https://github.com/osquery/osquery/pull/5551))
- Fix issues reported by ASAN ([#5665](https://github.com/osquery/osquery/pull/5665))
- Handle bad FDs in `md_tables` ([#5553](https://github.com/osquery/osquery/pull/5533))
- Fix lock resource leak in events/syslog ([#5552](https://github.com/osquery/osquery/pull/5552))
- Fix memory leak in macOS `keychain_items` and `extended_attributes` tables ([#5550](https://github.com/osquery/osquery/pull/5550), [#5538](https://github.com/osquery/osquery/pull/5538))
- Fix memory leak in `genLoggedInUsers` (Windows). Update `WTSFreeMemoryEx` to `WTSFreeMemory` ([#5642](https://github.com/osquery/osquery/pull/5642))
- Fix potential null dereferences in `smbios_tables` ([#5332](https://github.com/osquery/osquery/pull/5332))
- Fix osquery exiting with wrong status ([3824c2e6](https://github.com/osquery/osquery/commit/3824c2e6))
- Add additional `install` and `uninstall` flag incompatibility check ([85eb77a0](https://github.com/osquery/osquery/commit/85eb77a0))
- Fix warning with constants initialisation in `magic` ([2a624f2f](https://github.com/osquery/osquery/commit/2a624f2f))
- Fix sign compare warning in `file_compression` ([b93069b3](https://github.com/osquery/osquery/commit/b93069b3))
- Refactored `logical_drives` table on Windows ([#5400](https://github.com/osquery/osquery/pull/5400))
- Refactored core/windows/wmi to use smart pointers ([#5492](https://github.com/osquery/osquery/pull/5492))
- Fixed various potential crashes in the virtual table implementaion ([6ade85a5](https://github.com/osquery/osquery/commit/6ade85a5))
- Increase the amount of `MaxRecvRetries` for Thrift sockets ([#5390](https://github.com/osquery/osquery/pull/5390))
### Bug Fixes
- Fix the reading of the serial of a certificate (little-endian big int) ([#5742](https://github.com/osquery/osquery/pull/5742))
- Fix bugs and update pathname variables in MSI package build script ([#5733](https://github.com/osquery/osquery/pull/5733))
- Fix `registry` table exception closing an uninitialized key handle ([#5718](https://github.com/osquery/osquery/pull/5718))
- Config views are now recreated on startup ([#5732](https://github.com/osquery/osquery/pull/5732))
- Change MSI Service Error handling on Windows ([#5467](https://github.com/osquery/osquery/pull/5467))
- Allow mounting SQLite DBs using WAL journaling with ATC ([#5525](https://github.com/osquery/osquery/issues/5225), [#5633](https://github.com/osquery/osquery/pull/5633))
- Fix `mount` table interacting with direct autofs ([#5635](https://github.com/osquery/osquery/pull/5635))
- Fix HTTP Host Header to include port ([#5576](https://github.com/osquery/osquery/pull/5576))
- Various fixes to the Windows `certificates` table and expansion to include Personal certificates ([#5697](https://github.com/osquery/osquery/pull/5697)), ([#5696](https://github.com/osquery/osquery/pull/5696)), ([#5640](https://github.com/osquery/osquery/pull/5640)), ([#5631](https://github.com/osquery/osquery/pull/5631))
- Add optimization back to macOS `users` and `groups` ([#5684](https://github.com/osquery/osquery/pull/5684))
- Do not return a row for macOS `battery` if no data is present ([#5650](https://github.com/osquery/osquery/pull/5650))
- Fix several integer conversions in `process_ops` ([#5614](https://github.com/osquery/osquery/pull/5614))
- Include weekends on the `kernel_panics` table ([#5298](https://github.com/osquery/osquery/pull/5298))
- Fix `key_strength` bug for Windows `certificates` table ([#5304](https://github.com/osquery/osquery/pull/5304))
- The `interface` column of `routes` table could be empty on Windows ([bcf0ab8e](https://github.com/osquery/osquery/commit/bcf0ab8e))
- The `name` column of `programs` table could be empty on Windows ([7bceba4b](https://github.com/osquery/osquery/commit/7bceba4b))
- Fix `disable_watcher` flag ([08dc11b7](https://github.com/osquery/osquery/commit/08dc11b7))
- Populate `path` column correctly in `firefox_addons` table ([#5462](https://github.com/osquery/osquery/pull/5462))
- Fix numeric monitoring plugin not being registered ([#5484](https://github.com/osquery/osquery/pull/5484))
- Fix wrong error code returned when querying the Windows registry ([#5621](https://github.com/osquery/osquery/pull/5621))
- Fix `logical_drives` boot partition detection ([#5477](https://github.com/osquery/osquery/pull/5477))
- Replace sync calls by async within the HTTP client implementation ([#5606](https://github.com/osquery/osquery/pull/5606))
- Fix RocksDB crash related to `OptimizeForSmallDb` ([a31d7582](https://github.com/osquery/osquery/commit/a31d7582))
- Fix bug in table column data validator ([e3037331](https://github.com/osquery/osquery/commit/e3037331))
- Fix random port problem ([a32ed7c4](https://github.com/osquery/osquery/commit/a32ed7c4))
- Refactor `battery` table and return information even if advanced information is missing ([6a64e353](https://github.com/osquery/osquery/commit/6a64e353))
### Table Changes
- Added table `ibridge_info` on macOS (Notebooks only) ([#5707](https://github.com/osquery/osquery/pull/5707))
- Added table `running_apps` on macOS ([#5216](https://github.com/osquery/osquery/pull/5216))
- Added table `atom_packages` on macOS and Linux ([6d159d40](https://github.com/osquery/osquery/commit/6d159d40))
- Remove EC2 tables on Windows ([#5657](https://github.com/osquery/osquery/pull/5657))
- Added column `win_timestamp` to `time` table on Windows ([3bbe6c51](https://github.com/osquery/osquery/commit/3bbe6c51))
- Added column `is_hidded` to `users` and `groups` table on macOS ([#5368](https://github.com/osquery/osquery/pull/5368))
- Added column `profile` to `chrome_extensions` table ([#5213](https://github.com/osquery/osquery/pull/5213))
- Added column `epoch` to `rpm_packages` table on Linux ([#5248](https://github.com/osquery/osquery/pull/5248))
- Added column `sid` to `logged_in_users` table on Windows ([#5454](https://github.com/osquery/osquery/pull/5454))
- Added column `registry_hive` to `logged_in_users` table on Windows ([#5454](https://github.com/osquery/osquery/pull/5454))
- Added column `sid` to `certificates` table on Windows ([#5631](https://github.com/osquery/osquery/pull/5631))
- Added column `store_location` to `certificates` table on Windows ([#5631](https://github.com/osquery/osquery/pull/5631))
- Added column `store` to `certificates` table on Windows ([#5631](https://github.com/osquery/osquery/pull/5631))
- Added column `username` to `certificates` table on Windows ([#5631](https://github.com/osquery/osquery/pull/5631))
- Added column `store_id` to `certificates` table on Windows ([#5631](https://github.com/osquery/osquery/pull/5631))
- Added column `product_version` to `file` table on Windows ([#5431](https://github.com/osquery/osquery/pull/5431))
- Added column `source` to `sudoers` table on POSIX systems ([#5350](https://github.com/osquery/osquery/pull/5350))2019-09-10T01:14:41+00:00osquery 4.0.2osquery 4.0.22019-09-12T22:37:08+00:002019-09-12T22:37:08+00:00osquery 4.1.0osquery 4.1.02019-11-03T15:55:26+00:00
### New Features / Under the Hood improvements
- Restore extension SDK and build support ([#5851](https://github.com/osquery/osquery/pull/5851))
- Documentation improvements ([#5860](https://github.com/osquery/osquery/pull/5860)), ([#5852](https://github.com/osquery/osquery/pull/5852)), ([#5912](https://github.com/osquery/osquery/pull/5912)), ([#5954](https://github.com/osquery/osquery/pull/5954))
- Add more tests throughout the codebase ([#5837](https://github.com/osquery/osquery/pull/5837)), ([#5832](https://github.com/osquery/osquery/pull/5832)), ([#5857](https://github.com/osquery/osquery/pull/5857)), ([#5864](https://github.com/osquery/osquery/pull/5864)), ([#5855](https://github.com/osquery/osquery/pull/5855)), ([#5869](https://github.com/osquery/osquery/pull/5869)), ([#5871](https://github.com/osquery/osquery/pull/5871)), ([#5885](https://github.com/osquery/osquery/pull/5885)), ([#5903](https://github.com/osquery/osquery/pull/5903)), ([#5879](https://github.com/osquery/osquery/pull/5879)), ([#5914](https://github.com/osquery/osquery/pull/5914)), ([#5941](https://github.com/osquery/osquery/pull/5941)), ([#5957](https://github.com/osquery/osquery/pull/5957))
- Allow configuration more Linux Audit settings using flags ([#5953](https://github.com/osquery/osquery/pull/5953))
- Add logger_tls_max_lines flag ([#5956](https://github.com/osquery/osquery/pull/5956))
- Add AWS Session Token support ([#5944](https://github.com/osquery/osquery/pull/5944))
### Build
- Lots of work on CPack-based packaging ([#5809](https://github.com/osquery/osquery/pull/5809)), ([#5822](https://github.com/osquery/osquery/pull/5822)), ([#5823](https://github.com/osquery/osquery/pull/5823)), ([#5827](https://github.com/osquery/osquery/pull/5827)), ([#5780](https://github.com/osquery/osquery/pull/5780)), ([#5850](https://github.com/osquery/osquery/pull/5850)), ([#5843](https://github.com/osquery/osquery/pull/5843)), ([#5881](https://github.com/osquery/osquery/pull/5881)), ([#5825](https://github.com/osquery/osquery/pull/5825)), ([#5940](https://github.com/osquery/osquery/pull/5940)), ([#5951](https://github.com/osquery/osquery/pull/5951)), ([#5936](https://github.com/osquery/osquery/pull/5936))
- Lots of work porting Python2 to Python3 ([#5846](https://github.com/osquery/osquery/pull/5846))
- Upgrade OpenSSL to 1.0.2t on all platforms ([#5928](https://github.com/osquery/osquery/pull/5928))
- Use SQLite 3.29.0 on Windows and macOS ([#5810](https://github.com/osquery/osquery/pull/5810))
- Use aws-sdk-cpp source-builds on Windows and macOS ([#5889](https://github.com/osquery/osquery/pull/5889))
- Add various code quality checks and utilities ([#5834](https://github.com/osquery/osquery/pull/5834)), ([#5730](https://github.com/osquery/osquery/pull/5730)), ([#5872](https://github.com/osquery/osquery/pull/5872))
### Harderning
- Restore fuzzing harness and use oss-fuzz ([#5844](https://github.com/osquery/osquery/pull/5844)), ([#5886](https://github.com/osquery/osquery/pull/5886)), ([#5910](https://github.com/osquery/osquery/pull/5910)), ([#5915](https://github.com/osquery/osquery/pull/5915)), ([#5923](https://github.com/osquery/osquery/pull/5923)), ([#5955](https://github.com/osquery/osquery/pull/5955)), ([#5963](https://github.com/osquery/osquery/pull/5963))
- Use newer RapidJSON and switch to safer iterative parsing ([#5893](https://github.com/osquery/osquery/pull/5893)), ([#5913](https://github.com/osquery/osquery/pull/5913))
### Bug Fixes
- Set Windows MSI ErrorControl to normal instead of critical ([#5818](https://github.com/osquery/osquery/pull/5818))
- Wrap flagfile with quotes for Windows install flag ([#5824](https://github.com/osquery/osquery/pull/5824))
- Improve submodule usages in CMake ([#5850](https://github.com/osquery/osquery/pull/5850)), ([#5880](https://github.com/osquery/osquery/pull/5880)), ([#5892](https://github.com/osquery/osquery/pull/5892)), ([#5897](https://github.com/osquery/osquery/pull/5897)), ([#5907](https://github.com/osquery/osquery/pull/5907))
- Improve locking support in internal APIS ([#5841](https://github.com/osquery/osquery/pull/5841)), ([#5906](https://github.com/osquery/osquery/pull/5906)), ([#5943](https://github.com/osquery/osquery/pull/5943)), ([#5944](https://github.com/osquery/osquery/pull/5944))
- Fixes for macOS application layer firewall tables ([#5378](https://github.com/osquery/osquery/pull/5378))
- Fixes within BPF event tables ([#5874](https://github.com/osquery/osquery/pull/5874))
- Refactor and improve PCI device tables on Linux ([#5446](https://github.com/osquery/osquery/pull/5446))
- Implement PID indexing on Windows `processes` table ([#5919](https://github.com/osquery/osquery/pull/5919))
- Improve `WHERE IN()` performance ([#5924](https://github.com/osquery/osquery/pull/5924)), ([#5938](https://github.com/osquery/osquery/pull/5938))
- Improve the internal HTTP client ([#5891](https://github.com/osquery/osquery/pull/5891)), ([#5946](https://github.com/osquery/osquery/pull/5946)), ([#5947](https://github.com/osquery/osquery/pull/5947))
- Fix Windows version codename lookup ([#5887](https://github.com/osquery/osquery/pull/5887))
### Table Changes
- Added table `alf_services` to Darwin (Apple OS X) ([#5378](https://github.com/osquery/osquery/pull/5378))
- Added table `connectivity` to Microsoft Windows ([#5500](https://github.com/osquery/osquery/pull/5500))
- Added table `default_environment` to Microsoft Windows ([#5441](https://github.com/osquery/osquery/pull/5441))
- Added table `windows_security_products` to Microsoft Windows ([#5479](https://github.com/osquery/osquery/pull/5479))
- Added column `platform_mask` (`INTEGER_TYPE`) to table `osquery_info` ([#5898](https://github.com/osquery/osquery/pull/5898))2019-11-03T15:55:26+00:00osquery 4.1.1osquery 4.1.12019-11-19T17:58:55+00:00### New Features / Under the Hood improvements
- Improve `nvram` table to use input variable names ([#6053](https://github.com/osquery/osquery/pull/6053))
- Improve `apt_sources` source detection ([#6047](https://github.com/osquery/osquery/pull/6047))
- Change `atom_packages` to use user constraints ([#6052](https://github.com/osquery/osquery/pull/6052))
- Re-enable required-column warning messages ([#6038](https://github.com/osquery/osquery/pull/6038))
### Build
- Migrate several libraries to the CMake source layer ([#5902](https://github.com/osquery/osquery/pull/5902)), ([#6023](https://github.com/osquery/osquery/pull/6023))
- Update SQLite from 3.29.0-3 to 3.30.1-1 ([#6020](https://github.com/osquery/osquery/pull/6020))
- Recommend building with MacOS 10.11 SDK ([#6000](https://github.com/osquery/osquery/pull/6000))
### Hardening
### Bug Fixes
- Fix Linux audit incorrect read and handle leak ([#5959](https://github.com/osquery/osquery/pull/5959))
- Change "logNumericsAsNumbers" to "numerics" logger top-level key ([#6002](https://github.com/osquery/osquery/pull/6002))
- Restore INDEX behavior for extensions ([#6006](https://github.com/osquery/osquery/pull/6006))
- Fix potential JSON parsing issues in ATC plugin ([#6029](https://github.com/osquery/osquery/pull/6029))
- Avoid scanning special files with YARA ([#5971](https://github.com/osquery/osquery/pull/5971))
- Fix use-after-move in YARA subscriber ([#6054](https://github.com/osquery/osquery/pull/6054))
- Handle relative redirects in internal HTTP clients ([#6049](https://github.com/osquery/osquery/pull/6049))
- Apply options config parsing before others ([#6050](https://github.com/osquery/osquery/pull/6050))
### Table Changes
- Added table `windows_optional_features` to Microsoft Windows [#5991](https://github.com/osquery/osquery/pull/5991))
2019-11-19T17:58:55+00:00osquery 4.1.2osquery 4.1.22019-12-17T15:11:23+00:00## [4.1.2](https://github.com/osquery/osquery/releases/tag/4.1.2)
[Git Commits](https://github.com/osquery/osquery/compare/4.1.1...4.1.2)
### New Features / Under the Hood improvements
- Add more tests throughout the codebase ([#5908](https://github.com/osquery/osquery/pull/5908)), ([#6071](https://github.com/osquery/osquery/pull/6071)), ([#6126](https://github.com/osquery/osquery/pull/6126))
- The `chrome_extensions` table now supports Chromium and Brave ([#6126](https://github.com/osquery/osquery/pull/6126))
### Build
- Require Python 3.5 and greater ([#6081](https://github.com/osquery/osquery/pull/6081)), ([#6120](https://github.com/osquery/osquery/pull/6120))
- Prepare Python tests for CI (lots of effort!) ([#6068](https://github.com/osquery/osquery/pull/6068))
- Restore osqueryd integration test ([#6116](https://github.com/osquery/osquery/pull/6116))
### Bug Fixes
- Continue to use `com.facebook.osquery.plist` for Launch Daemon configuration ([#6093](https://github.com/osquery/osquery/pull/6093))
- Update systemd service to use KillMode=control-group ([#6096](https://github.com/osquery/osquery/pull/6096))
- RPM and DEB packages both have post-install scripts to reload systemd ([#6097](https://github.com/osquery/osquery/pull/6097))
- Update Windows package build script to include cert bundle ([#6114](https://github.com/osquery/osquery/pull/6114))
- Update table specs to fix constraints passing ([#6103](https://github.com/osquery/osquery/pull/6103)), ([#6104](https://github.com/osquery/osquery/pull/6104)), ([#6105](https://github.com/osquery/osquery/pull/6105)), ([#6106](https://github.com/osquery/osquery/pull/6106)), ([#6122](https://github.com/osquery/osquery/pull/6122))
### Table Changes
- Added tables `azure_instance_tags` and `azure_instance_metadata` to Linux and Microsoft Windows ([#5434](https://github.com/osquery/osquery/pull/5434))
- Added column `install_time` (`INTEGER_TYPE`) to table `rpm_packages` ([#6113](https://github.com/osquery/osquery/pull/6113))
- Added column `bsd_flags` (`TEST_TYPE`) to table `file` on Darwin ([#5981](https://github.com/osquery/osquery/pull/5981))
2019-12-17T15:11:23+00:00osquery 4.2.0osquery 4.2.02020-02-13T17:03:57+00:00### New Features / Under the Hood improvements
- TLS Testing infrastructure has been overhauled ([#6170](https://github.com/osquery/osquery/pull/6170))
- Boost regex has been replaced with std ([#6236](https://github.com/osquery/osquery/pull/6236))
- `community_id_v1` added as a SQL function ([#6211](https://github.com/osquery/osquery/pull/6211))
### Build
- Fix format checking on Windows ([#6188](https://github.com/osquery/osquery/pull/6188))
- Fix format folder exclusions for build checks ([#6201](https://github.com/osquery/osquery/pull/6201))
- Fix the linking for extensions in build ([#6219](https://github.com/osquery/osquery/pull/6219))
- Fix build to include windows optional features table ([#6207](https://github.com/osquery/osquery/pull/6207))
### Security Issues
- [CVE-2020-1887] osquery does not properly verify the SNI hostname ([#6197](https://github.com/osquery/osquery/pull/6197))
### Bug Fixes
- Carver no longer returns empty carves for hidden files ([#6183](https://github.com/osquery/osquery/pull/6183))
- Address a race in the Dispatcher logic ([#6145](https://github.com/osquery/osquery/pull/6145))
- Fix validation in 'last' table ([#6147](https://github.com/osquery/osquery/pull/6147))
- Fix flaky logger testing ([#6171](https://github.com/osquery/osquery/pull/6171))
- Fix JSON format assumptions in file_paths parsing ([#6159](https://github.com/osquery/osquery/pull/6159))
- Fix windows WMI BSTR to be wstrings ([#6175](https://github.com/osquery/osquery/pull/6175))
- Fix windows string <-> wstring conversion functions ([#6187](https://github.com/osquery/osquery/pull/6187))
- Enable more intelligent path expansion on Windows ([#6153](https://github.com/osquery/osquery/pull/6153))
- Fix heap buffer overflow in callDoubleFunc and powerFunc ([#6225](https://github.com/osquery/osquery/pull/6225))
### Table Changes
- Added table `firefox_addons` to All Platforms ([#6200](https://github.com/osquery/osquery/pull/6200))
- Added table `ssh_configs` to All Platforms ([#6161](https://github.com/osquery/osquery/pull/6161))
- Added table `user_ssh_keys` to All Platforms ([#6161](https://github.com/osquery/osquery/pull/6161))
- Added table `mdls` to Darwin (Apple OS X) ([#4825](https://github.com/osquery/osquery/pull/4825))
- Added table `hvci_status` to Microsoft Windows ([#5426](https://github.com/osquery/osquery/pull/5426))
- Added table `ntfs_journal_events` to Microsoft Windows ([#5426](https://github.com/osquery/osquery/pull/5426))
- Added table `docker_image_layers` to POSIX-compatible Plaforms ([#6154](https://github.com/osquery/osquery/pull/6154))
- Added table `process_open_pipes` to POSIX-compatible Plaforms ([#6142](https://github.com/osquery/osquery/pull/6142))
- Added table `apparmor_profiles` to Ubuntu, CentOS ([#6138](https://github.com/osquery/osquery/pull/6138))
- Added table `selinux_settings` to Ubuntu, CentOS ([#6118](https://github.com/osquery/osquery/pull/6118))
- Added column `lock_status` (`INTEGER_TYPE`) to table `bitlocker_info` ([#6155](https://github.com/osquery/osquery/pull/6155))
- Added column `percentage_encrypted` (`INTEGER_TYPE`) to table `bitlocker_info` ([#6155](https://github.com/osquery/osquery/pull/6155))
- Added column `version` (`INTEGER_TYPE`) to table `bitlocker_info` ([#6155](https://github.com/osquery/osquery/pull/6155))
- Added column `optional_permissions` (`TEXT_TYPE`) to table `chrome_extensions` ([#6115](https://github.com/osquery/osquery/pull/6115))
- Removed table `firefox_addons` from POSIX-compatible Plaforms ([#6200](https://github.com/osquery/osquery/pull/6200))
- Removed table `ssh_configs` from POSIX-compatible Plaforms ([#6161](https://github.com/osquery/osquery/pull/6161))
- Removed table `user_ssh_keys` from POSIX-compatible Plaforms ([#6161](https://github.com/osquery/osquery/pull/6161))2020-02-13T17:03:57+00:00osquery 4.3.0osquery 4.3.02020-04-14T15:04:31+00:00### New Features / Under the Hood improvements
- Change verbosity of scheduled query execution messages from INFO to verbose only ([#6271](https://github.com/osquery/osquery/pull/6271))
- Updated the unwanted-chrome-extensions queries to include all users, not the osquery process owner only ([#6265](https://github.com/osquery/osquery/pull/6265))
- Check for errors in the return status of the extension tables and report them ([#6108](https://github.com/osquery/osquery/pull/6108))
- First steps to properly support UTF8 strings on Windows ([#6190](https://github.com/osquery/osquery/pull/6190))
- Display the undelying API error string when udev monitoring fails ([#6186](https://github.com/osquery/osquery/pull/6186))
- Add the `path` column to the ATC generate specs ([#6278](https://github.com/osquery/osquery/pull/6278))
- Log a warning message if osquery fails to get the service description on Microsoft Windows ([#6281](https://github.com/osquery/osquery/pull/6281))
- Make AWS kinesis status logging configurable ([#6135](https://github.com/osquery/osquery/pull/6135))
- Add an integration test for the `disk_info` table ([#6323](https://github.com/osquery/osquery/pull/6323))
- Use -1 for missing `ppid` in the `process_events` table ([#6339](https://github.com/osquery/osquery/pull/6339))
- Remove error when converting empty numeric rows ([#6371](https://github.com/osquery/osquery/pull/6371))
- Change verbosity from ERROR to INFO of access failures to system processes on Microsoft Windows ([#6370](https://github.com/osquery/osquery/pull/6370))
- Make possible to get verbose messages from the dispatcher service management on Microsoft Windows too ([#6369](https://github.com/osquery/osquery/pull/6369))
### Build
- Fix codegen template for extension group ([#6244](https://github.com/osquery/osquery/pull/6244))
- Update SQLite from 3.30.1-1 to 3.31.1 ([#6252](https://github.com/osquery/osquery/pull/6252))
- Update the osquery-toolchain to version 1.1.0 which uses LLVM/Clang 9.0.1 ([#6315](https://github.com/osquery/osquery/pull/6315))
- Update openssl to version 1.1.1f ([#6302](https://github.com/osquery/osquery/pull/6302), [#6359](https://github.com/osquery/osquery/pull/6359))
- Simplify formula-based third party libraries build ([#6303](https://github.com/osquery/osquery/pull/6303))
- Removed the Buck build system ([#6361](https://github.com/osquery/osquery/pull/6361))
- Add librdkafka to Windows build ([#6095](https://github.com/osquery/osquery/pull/6095))
### Bug Fixes
- Fix CFNumber conversion when the type was a Float64/32 instead of a Double ([#6273](https://github.com/osquery/osquery/pull/6273))
- Fix duplicate results being returned by the chrome_extensions table ([#6277](https://github.com/osquery/osquery/pull/6277))
- Fix flaky ProcessOpenFilesTest.test_sanity ([#6185](https://github.com/osquery/osquery/pull/6185))
- Fix the `--database_dump` flag for RocksDB not outputting anything ([#6272](https://github.com/osquery/osquery/pull/6272))
- Fix the `pci_devices` table pci ids extraction in non-existing paths ([#6297](https://github.com/osquery/osquery/pull/6297))
- Fix parsing an invalid decorators config ([#6317](https://github.com/osquery/osquery/pull/6317))
- Fix flaky TLSConfigTests.test_runner_and_scheduler ([#6308](https://github.com/osquery/osquery/pull/6308))
- Fix chromeExtensions.test_sanity ([#6324](https://github.com/osquery/osquery/pull/6324))
- Fix broken Unicode filename searches on Microsoft Windows ([#6291](https://github.com/osquery/osquery/pull/6291))
- Fix a use-after-free when sqlite attempts to access the entire rows data at the end of a query ([#6328](https://github.com/osquery/osquery/pull/6328))
- Keep proc instance for test_base and test_osqueryd ([#6335](https://github.com/osquery/osquery/pull/6335))
- Fix osquery not exiting when given check or dump requests ([#6334](https://github.com/osquery/osquery/pull/6334))
- Fix `process` table `cmdline` parsing ([#6340](https://github.com/osquery/osquery/pull/6340))
- Fix a crash when parsing files with libmagic ([#6363](https://github.com/osquery/osquery/pull/6363))
- Fix a sporadic readFile API failure when using non-blocking I/O ([#6368](https://github.com/osquery/osquery/pull/6368))
- Fix the MSI package not always installing in the system drive by default ([#6379](https://github.com/osquery/osquery/pull/6379))
- Ensure the extensions uuid is never 0 ([#6377](https://github.com/osquery/osquery/pull/6377))
- Fix a race condition making the watcher act as a worker on Microsoft Windows ([#6372](https://github.com/osquery/osquery/pull/6372))
- Fix extensions tables detaching which was sometimes failing ([#6373](https://github.com/osquery/osquery/pull/6373))
- Fix an issue with extensions re-registration ([#6374](https://github.com/osquery/osquery/pull/6374))
- Fix a crash due to a race condition in accessing the iokit port on Darwin (Apple OS X) ([#6380](https://github.com/osquery/osquery/pull/6380))
### Hardening
- Limit SQL functions regex_match and regex_split regex size ([#6267](https://github.com/osquery/osquery/pull/6267))
- Prevent a stack overflow when parsing deeply nested configs ([#6325](https://github.com/osquery/osquery/pull/6325))
### Table Changes
- Added table `chrome_extension_content_scripts` to All Platforms ([#6140](https://github.com/osquery/osquery/pull/6140))
- Added table `docker_container_fs_changes` to POSIX-compatible Plaforms ([#6178](https://github.com/osquery/osquery/pull/6178))
- Added table `windows_security_center` to Microsoft Windows ([#6256](https://github.com/osquery/osquery/pull/6256))
- Added many new tables to Linux to query `lxd` ([#6249](https://github.com/osquery/osquery/pull/6249))
- Added table `screenlock` to Darwin (Apple OS X) ([#6243](https://github.com/osquery/osquery/pull/6243))
- Added table `userassist` to Microsoft Windows ([#5539](https://github.com/osquery/osquery/pull/5539))
- Added column `status` (`TEXT`) to table `deb_packages` ([#6341](https://github.com/osquery/osquery/pull/6341))
- Added many new columns to the `curl_certificate` table ([#6176](https://github.com/osquery/osquery/pull/6176))
- Added table `socket_events` to Darwin (Apple OS X) ([#6028](https://github.com/osquery/osquery/pull/6028))
- Added table `hvci_status`, previously inadvertly left out from the build, to Microsoft Windows ([6378](https://github.com/osquery/osquery/pull/6378))2020-04-14T15:04:31+00:00osquery 4.4.0osquery 4.4.02020-06-25T19:06:51+00:00### New Features / Under the Hood improvements
- Implement container access from tables on Linux ([#6209](https://github.com/osquery/osquery/pull/6209), [#6485](https://github.com/osquery/osquery/pull/6485))
- Update language to use 'allow list' and 'deny list' ([#6489](https://github.com/osquery/osquery/pull/6489), [#6487](https://github.com/osquery/osquery/pull/6487), [#6488](https://github.com/osquery/osquery/pull/6488), [#6493](https://github.com/osquery/osquery/pull/6493))
- macos: Automatic configuration of the OpenBSM audit rules ([#6447](https://github.com/osquery/osquery/pull/6447))
- macos: Add polling to OpenBSM publisher ([#6436](https://github.com/osquery/osquery/pull/6436))
- Add messages to distributed query results ([#6352](https://github.com/osquery/osquery/pull/6352))
- Implement event batching support for Windows tables ([#6280](https://github.com/osquery/osquery/pull/6280))
### Table Changes
- Add container access to the os_version table ([#6413](https://github.com/osquery/osquery/pull/6413))
- Add container access to DEB, RPM, NPM packages tables ([#6414](https://github.com/osquery/osquery/pull/6414))
- Add fields auid, fs{u,g}id, s{u,g}id to auditd based tables ([#6362](https://github.com/osquery/osquery/pull/6362))
- Improve apt_sources resiliency ([#6482](https://github.com/osquery/osquery/pull/6482))
- Make file and hash container columns hidden ([#6486](https://github.com/osquery/osquery/pull/6486))
- Add 'maintainer', 'section', 'priority' columns to deb_packages ([#6442](https://github.com/osquery/osquery/pull/6442))
- Add 'vendor', 'package_group' columns to rpm_packages ([#6443](https://github.com/osquery/osquery/pull/6443))
- Add 'arch' column to os_version ([#6444](https://github.com/osquery/osquery/pull/6444))
- Add 'board_xxx' columns to system_info table ([#6398](https://github.com/osquery/osquery/pull/6398))
- Windows: omit non-interactive sessions from logged_in_users ([#6375](https://github.com/osquery/osquery/pull/6375))
- Fixes to package_bom table ([#6457](https://github.com/osquery/osquery/pull/6457), [#6461](https://github.com/osquery/osquery/pull/6461))
- Add chassis_info table for windows ([#5282](https://github.com/osquery/osquery/pull/5282))
- Add Azure tables ([#6507](https://github.com/osquery/osquery/pull/6507))
### Bug Fixes
- Update hash cache inode number in query cache ([#6440](https://github.com/osquery/osquery/pull/6440))
- Only explode registry key if it can be tokenized ([#6474](https://github.com/osquery/osquery/pull/6474))
- Change ErrorBase::takeUnderlyingError to non const ([#6483](https://github.com/osquery/osquery/pull/6483))
- Use RapidJSON to fix event format results and the Kafka Logger ([#6449](https://github.com/osquery/osquery/pull/6449))
- Correct the 'cwd' and 'root' columns of processes table on Windows ([#6459](https://github.com/osquery/osquery/pull/6459))
- Correct some SQLite types ([#6392](https://github.com/osquery/osquery/pull/6392))
- Partial fix for md_devices issue ([#6417](https://github.com/osquery/osquery/pull/6417))
- Fix the handling of empty args strings, on Windows ([#6460](https://github.com/osquery/osquery/pull/6460))
- Refactor shutdown logging, and remove explicit syslog call ([#6376](https://github.com/osquery/osquery/pull/6376))
- Change the Windows registry LIKE path constraint to filter recursively ([#6448](https://github.com/osquery/osquery/pull/6448))
- Use sync resolve within http client ([#6490](https://github.com/osquery/osquery/pull/6490))
- Fix typed_row table caching ([#6508](https://github.com/osquery/osquery/pull/6508))
- Do not use system proxy for AWS local authority ([#6512](https://github.com/osquery/osquery/pull/6512))
- Only populate table cache with star-like selects ([#6513](https://github.com/osquery/osquery/pull/6513))
### Documentation
- Update osquery security policy ([#6425](https://github.com/osquery/osquery/pull/6425))
- Updating changelog for 4.3.0 release ([#6387](https://github.com/osquery/osquery/pull/6387))
- Improve the new table tutorial ([#6479](https://github.com/osquery/osquery/pull/6479))
- Add Auto Table Construction to docs ([#6476](https://github.com/osquery/osquery/pull/6476))
- Add documentation for enabling socket_events on macOS ([#6407](https://github.com/osquery/osquery/pull/6407))
- Update winbaseobj table description ([#6429](https://github.com/osquery/osquery/pull/6429))
- Fixing the description of failed_login_count from account_policy_data ([#6415](https://github.com/osquery/osquery/pull/6415))
- Remove references to brew in macOS install ([#6494](https://github.com/osquery/osquery/pull/6494))
- Add note to bump the Homebrew cask ([#6519](https://github.com/osquery/osquery/pull/6519))
- Updating docs on cpack usage to include Chocolatey ([#6022](https://github.com/osquery/osquery/pull/6022))
- Changelog for 4.4.0 ([#6492](https://github.com/osquery/osquery/pull/6492), [#6523](https://github.com/osquery/osquery/pull/6523)))
### Build
- Fix Userassist.test_sanity test sometimes failing ([#6396](https://github.com/osquery/osquery/pull/6396))
- Drop the facebook and source_migration layers ([#6473](https://github.com/osquery/osquery/pull/6473))
- Move ssdeep-cpp to source_migration ([#6464](https://github.com/osquery/osquery/pull/6464))
- Move smartmontools to source_migration ([#6465](https://github.com/osquery/osquery/pull/6465))
- Build augeas from source on macOS ([#6399](https://github.com/osquery/osquery/pull/6399))
- Build lldpd from source on macOS ([#6406](https://github.com/osquery/osquery/pull/6406))
- Build linenoise-ng from source on macOS and Windows ([#6412](https://github.com/osquery/osquery/pull/6412))
- Build sleuthkit from source on macOS ([#6416](https://github.com/osquery/osquery/pull/6416))
- Build popt from source on macOS ([#6409](https://github.com/osquery/osquery/pull/6409))
- Fix libelfin build on ossfuzz and LLVM/Clang 10 ([#6472](https://github.com/osquery/osquery/pull/6472))
- Use the patched libelfin version ([#6480](https://github.com/osquery/osquery/pull/6480))
- codegen: Port Jinja2 to Templite ([#6470](https://github.com/osquery/osquery/pull/6470))
- Pass the minimum macOS SDK version to openssl only if explicitly set ([#6471](https://github.com/osquery/osquery/pull/6471))
- Add git-lfs as dep for macOS build in documentation ([#6384](https://github.com/osquery/osquery/pull/6384))
- Update openssl from 1.1.1f to 1.1.1g ([#6432](https://github.com/osquery/osquery/pull/6432))
- Build openssl with the macOS SDK version taken from CMake ([#6469](https://github.com/osquery/osquery/pull/6469))
- Do not install openssl docs ([#6441](https://github.com/osquery/osquery/pull/6441))
- Update build configuration of ReadTheDocs ([#6434](https://github.com/osquery/osquery/pull/6434), [#6456](https://github.com/osquery/osquery/pull/6456))
- Link librdkafka on Windows ([#6454](https://github.com/osquery/osquery/pull/6454))
- Build sleuthkit on Windows ([#6445](https://github.com/osquery/osquery/pull/6445))
- Add nupkg cpack build option and update Windows deployment script ([#6262](https://github.com/osquery/osquery/pull/6262))
- Fix rpm and deb package name format ([#6468](https://github.com/osquery/osquery/pull/6468))
- Fix atom_packages, processes, rpm_packages tests ([#6518](https://github.com/osquery/osquery/pull/6518))
- Fixes and cleanup for Windows compiler flags ([#6521](https://github.com/osquery/osquery/pull/6521))
- Correct macOS framework linking ([#6522](https://github.com/osquery/osquery/pull/6522))
### Security Issues
- Disable openssl compression support ([#6433](https://github.com/osquery/osquery/pull/6433))
### Hardening
- Use LOAD_LIBRARY_SEARCH_SYSTEM32 for LoadLibrary ([#6458](https://github.com/osquery/osquery/pull/6458))
2020-06-25T19:06:51+00:00osquery 4.5.0osquery 4.5.02020-09-12T23:18:58+00:00We would like to thank all of the contributors working on bootstrapping the ARM64/AARCH64 support and Windows 32bit support.
Additionally, we want to thank those working on Unicode support and all the bug fixes, documentation improvements, and new features.
Thank you! :clap:
### New Features
- ARM64/AARCH64 beta support for Linux ([#6612](https://github.com/osquery/osquery/pull/6612))
- Windows 32bit support ([#6543](https://github.com/osquery/osquery/pull/6543))
- Fix buildup of RocksDB SST files ([#6606](https://github.com/osquery/osquery/pull/6606))
### Under the Hood improvements
- Remove selectAllFrom from Linux `process_events` callback ([#6638](https://github.com/osquery/osquery/pull/6638))
- Remove database read only concept ([#6637](https://github.com/osquery/osquery/pull/6637))
- Move database initialization retry logic into DB API ([#6633](https://github.com/osquery/osquery/pull/6633))
- Move osquery/include files into respective CMake targets ([#6557](https://github.com/osquery/osquery/pull/6557))
- Memoize `EventFactory::getType` ([#6555](https://github.com/osquery/osquery/pull/6555))
- Update schedule counter behavior ([#6223](https://github.com/osquery/osquery/pull/6223))
- Define `UNICODE` and `_UNICODE` preprocessors for windows ([#6338](https://github.com/osquery/osquery/pull/6338))
- Add WMI utility function to convert datetime to FILETIME ([#5901](https://github.com/osquery/osquery/pull/5901))
- Move osquery shutdown logic outside of `Initialize`r ([#6530](https://github.com/osquery/osquery/pull/6530))
### Table Changes
- Support for Windows Background Activity Moderator ([#6585](https://github.com/osquery/osquery/pull/6585))
- Add `apparmor_events` table to Linux ([#4982](https://github.com/osquery/osquery/pull/4982))
- Add `sigurl` column to get YARA signatures from an HTTPS server ([#6607](https://github.com/osquery/osquery/pull/6607))
- Add `sigrules` column to pass YARA signatures within queries ([#6568](https://github.com/osquery/osquery/pull/6568))
- Add non-evented table for querying `windows_event_log` ([#6563](https://github.com/osquery/osquery/pull/6563))
- Improve `chassis_types` and `security_breach` columns within `chassis_info` ([#6608](https://github.com/osquery/osquery/pull/6608))
- Fix bool type usage in `powershell_events` ([#6584](https://github.com/osquery/osquery/pull/6584))
- Add `FileVersionRaw` column to `file` table for Windows ([#5771](https://github.com/osquery/osquery/pull/5771))
- Enable YARA table on Windows ([#6564](https://github.com/osquery/osquery/pull/6564))
- Add `dns_cache` table for Windows ([#6505](https://github.com/osquery/osquery/pull/6505))
- Add support for processing KILL syscall ([#6435](https://github.com/osquery/osquery/pull/6435))
- Add `startup_item`s table for Linux ([#6502](https://github.com/osquery/osquery/pull/6502))
- Add `shimcache` table ([#6463](https://github.com/osquery/osquery/pull/6463))
- Refactor `shell_history` to use generators (it will use less memory) ([#6541](https://github.com/osquery/osquery/pull/6541))
### Bug Fixes
- Set thread names correctly on macOS and Linux ([#6627](https://github.com/osquery/osquery/pull/6627))
- Apply `--scheduler_timeout` correctly ([#6618](https://github.com/osquery/osquery/pull/6618))
- Add check for `character_frequencies` size ([#6625](https://github.com/osquery/osquery/pull/6625))
- Fix race in removing external `TablePlugins` ([#6623](https://github.com/osquery/osquery/pull/6623))
- Force shell to disable watchdog and logger ([#6621](https://github.com/osquery/osquery/pull/6621))
- Return early within the shell if relative flags are used ([#6605](https://github.com/osquery/osquery/pull/6605))
- Apply watcher delay each time the worker is started ([#6604](https://github.com/osquery/osquery/pull/6604))
- Set global output function for Thrift ([#6592](https://github.com/osquery/osquery/pull/6592))
- Fix incorrect `readFile` params in `createPidFile` ([#6578](https://github.com/osquery/osquery/pull/6578))
- Fix call to `LocalFree` on deinit ptr inside `getUidFromSid` ([#6579](https://github.com/osquery/osquery/pull/6579))
- Fix `readFile` to observe requested read size ([#6569](https://github.com/osquery/osquery/pull/6569))
- Replace fstream within `syslog_event`s with a custom non-blocking getline ([#6539](https://github.com/osquery/osquery/pull/6539))
- Only fire events if a publisher exists ([#6553](https://github.com/osquery/osquery/pull/6553))
- Fix Leak in `psidToString` ([#6548](https://github.com/osquery/osquery/pull/6548))
- Fix memory leaks in `rpm_package_files` ([#6544](https://github.com/osquery/osquery/pull/6544))
- Change "Symlink loop" message from warning to verbose ([#6545](https://github.com/osquery/osquery/pull/6545))
### Documentation
- Update process auditing docs schema link ([#6645](https://github.com/osquery/osquery/pull/6645))
- Improve descriptions for the `processes` table ([#6596](https://github.com/osquery/osquery/pull/6596))
- Replace slackin with Slack shared invite ([#6617](https://github.com/osquery/osquery/pull/6617))
- Update copyright notices to osquery foundation ([#6589](https://github.com/osquery/osquery/pull/6589), [#6590](https://github.com/osquery/osquery/pull/6590))
### Build
- Fix Windows build by removing non existing C11 conformance ([#6629](https://github.com/osquery/osquery/pull/6629))
- Remove `ExecStartPre` from systemd service unit ([#6586](https://github.com/osquery/osquery/pull/6586))
- Fix pip upgrade warning within CI ([#6576](https://github.com/osquery/osquery/pull/6576))
- Detect `MAJOR_IN_SYSMACROS`/`MKDEV` for librpm in CMake ([#6554](https://github.com/osquery/osquery/pull/6554))
- Add `curl_certificate` tests ([#5281](https://github.com/osquery/osquery/pull/5281))
- Update YARA library to 4.0.2 ([#6559](https://github.com/osquery/osquery/pull/6559))
- Improve testing assumptions and flush fsevents when stopping ([#6552](https://github.com/osquery/osquery/pull/6552))
- Fix the test utility to allow Windows profiling ([#6550](https://github.com/osquery/osquery/pull/6550))
- Support ASAN for boost coroutine2 using ucontext ([#6531](https://github.com/osquery/osquery/pull/6531))
- Update instructions for CPack package building ([#6529](https://github.com/osquery/osquery/pull/6529))
- Use specific RPM variables to set the package name ([#6527](https://github.com/osquery/osquery/pull/6527))
- Update compiler version used to v142 within Azure ([#6528](https://github.com/osquery/osquery/pull/6528))
### Hardening
- Restore PIE support being dropped on Linux ([#6611](https://github.com/osquery/osquery/pull/6611))2020-09-12T23:18:58+00:00osquery 4.5.1osquery 4.5.12020-10-05T17:06:19+00:00# osquery Changelog
<a name="4.5.1"></a>
## [4.5.1](https://github.com/osquery/osquery/releases/tag/4.5.1)
[Git Commits](https://github.com/osquery/osquery/compare/4.5.0...4.5.1)
### Under the Hood improvements
- Improve carver tests by faking `postCarve` ([#6659](https://github.com/osquery/osquery/pull/6659))
- Emit an error during carving, if the `carve` SQL function is disabled ([#6658](https://github.com/osquery/osquery/pull/6658))
- Update `carves` specs to allow full scan ([#6657](https://github.com/osquery/osquery/pull/6657))
- Update `carves` table to use JSON ([#6656](https://github.com/osquery/osquery/pull/6656))
- Improve performance and accuracy of Windows `registry` querying ([#6647](https://github.com/osquery/osquery/pull/6647))
- Refactor `ephemeral` database plugin into core and simplify tests ([#6648](https://github.com/osquery/osquery/pull/6648))
### Table Changes
- Support for Office MRU (most recently used) entries ([#6587](https://github.com/osquery/osquery/pull/6587))
- Implement configurable timeout through WHERE clause on `curl_certificate` ([#6641](https://github.com/osquery/osquery/pull/6641))
- Add `atom_packages` table spec to window ([#6649](https://github.com/osquery/osquery/pull/6649))
- Add signature information to `authenticode` table on windows ([#6677](https://github.com/osquery/osquery/pull/6677))
- Add additional AWS regions ([#6666](https://github.com/osquery/osquery/pull/6666))
### Bug Fixes
- Fix container overflow in `curl_certificate` ([#6664](https://github.com/osquery/osquery/pull/6664))
- Fix handling of invalid array bound error with `EvtNext` function ([#6660](https://github.com/osquery/osquery/pull/6660))
- Fix `wmi_bios_info` table searching ([#5246](https://github.com/osquery/osquery/pull/5246))
- Fix `image` column within `drivers` table on Windows ([#6652](https://github.com/osquery/osquery/pull/6652))
- Fix windows `dirPathsAreEqual` to use the documented way ([#6690](https://github.com/osquery/osquery/pull/6690))
- Fix incorrect `stat()` return checking within process_events ([#6694](https://github.com/osquery/osquery/pull/6694))
- Always flush `stdout` when called with `--help` ([#6693](https://github.com/osquery/osquery/pull/6693))
### Documentation
- Document max scheduled query interval ([#6683](https://github.com/osquery/osquery/pull/6683))
- Update documentation around build steps ([#6681](https://github.com/osquery/osquery/pull/6681))
- Documentation copy editing ([#6676](https://github.com/osquery/osquery/pull/6676), [#6665](https://github.com/osquery/osquery/pull/6665), [#6662](https://github.com/osquery/osquery/pull/6662))
- Add 4.5.0 CHANGELOG ([#6646](https://github.com/osquery/osquery/pull/6646))
- Add 4.5.1 CHANGELOG ([#6692](https://github.com/osquery/osquery/pull/6692))
### Build
- Improve flaky python test handling ([#6654](https://github.com/osquery/osquery/pull/6654))
- Restore `test_osqueryi` ([#6631](https://github.com/osquery/osquery/pull/6631))
- Limit `osqueryd` CPU usage to 20% in systemd unit file ([#6644](https://github.com/osquery/osquery/pull/6644))
- Improve flaky `test_osqueryi` ([#6688](https://github.com/osquery/osquery/pull/6688))
- Add `cppcheck` support to macOS ([#6685](https://github.com/osquery/osquery/pull/6685))
### Hardening
- Add exception catching for table execution ([#6689](https://github.com/osquery/osquery/pull/6689))
2020-10-05T17:06:19+00:00osquery 4.6.0osquery 4.6.02020-12-15T04:28:40+00:00## [4.6.0](https://github.com/osquery/osquery/releases/tag/4.6.0)
[Git Commits](https://github.com/osquery/osquery/compare/4.5.1...4.6.0)
### New Features
- Initial implementations for BPF-based socket and process events tables ([#6571](https://github.com/osquery/osquery/pull/6571))
- Support EC2 tables on Windows ([#6756](https://github.com/osquery/osquery/pull/6756))
### Under the Hood improvements
- BPF: Add container support to fork/vfork/clone ([#6721](https://github.com/osquery/osquery/pull/6721))
- BPF: Additional improvements on the initial implementation ([#6717](https://github.com/osquery/osquery/pull/6717))
- BPF: Fix the tests ([#6783](https://github.com/osquery/osquery/pull/6783))
- BPF: Fix wrong d_type compare in filesystem classes ([#6774](https://github.com/osquery/osquery/pull/6774))
- BPF: Implement additional syscalls to track file descriptor usage ([#6723](https://github.com/osquery/osquery/pull/6723))
- Remove unused LTCG flag ([#6769](https://github.com/osquery/osquery/pull/6769))
- Support TLS client certificate chains ([#6753](https://github.com/osquery/osquery/pull/6753))
- Refactor carver to use the Scheduler ([#6671](https://github.com/osquery/osquery/pull/6671))
- Add configuration flag to disable file_events by default ([#6663](https://github.com/osquery/osquery/pull/6663))
- libs: Build x86_64 configurations on Ubuntu 14.04 ([#6687](https://github.com/osquery/osquery/pull/6687))
- libs: Port the RocksDB Win7 compatibility patch to the MSBuild generator ([#6765](https://github.com/osquery/osquery/pull/6765))
- libs: Update BPF libraries to support LLVM 11 ([#6775](https://github.com/osquery/osquery/pull/6775))
- libs: Update RocksDB to version 6.14.5 ([#6759](https://github.com/osquery/osquery/pull/6759))
- libs: Update bzip2 to version 1.0.8 ([#6786](https://github.com/osquery/osquery/pull/6786))
- libs: Update ebpfpub to latest version ([#6757](https://github.com/osquery/osquery/pull/6757))
- libs: Update sqlite to version 3.34.0 ([#6804](https://github.com/osquery/osquery/pull/6804))
- libs: update aws-sdk to 1.7.230 ([#6749](https://github.com/osquery/osquery/pull/6749))
- Adding support for pretty-printing JSON results in osqueryi ([#6695](https://github.com/osquery/osquery/pull/6695))
### Table Changes
- Add Yandex Browser support for chrome_extensions ([#6735](https://github.com/osquery/osquery/pull/6735))
- Add additional file stat flags to Darwin (bsd_flags) ([#6699](https://github.com/osquery/osquery/pull/6699))
- Add extended_attributes table to Linux, add support for Linux capabilities ([#6195](https://github.com/osquery/osquery/pull/6195))
- Add indexed column support to Windows users table ([#6782](https://github.com/osquery/osquery/pull/6782))
- Enable AWS Instance profile as credential provider on Windows ([#6754](https://github.com/osquery/osquery/pull/6754))
- Add systemd support for startup_items on Linux ([#6562](https://github.com/osquery/osquery/pull/6562))
### Bug Fixes
- Do not use memset on VirtualTable, a non-POD type ([#6760](https://github.com/osquery/osquery/pull/6760))
- Fix deadlock when registering two extensions ([#6745](https://github.com/osquery/osquery/pull/6745))
- Fix last_connected column in wifi_networks on Catalina ([#6669](https://github.com/osquery/osquery/pull/6669))
- Fix missing negations, duplicate rows in iptables table ([#6713](https://github.com/osquery/osquery/pull/6713))
- Fix shadow table to detect empty passwords ([#6696](https://github.com/osquery/osquery/pull/6696))
- Free memory allocated by ConvertStringSidToSid ([#6714](https://github.com/osquery/osquery/pull/6714))
- PackageIdentifiers are optional in InstallHistory.plist ([#6767](https://github.com/osquery/osquery/pull/6767))
- Removing PUNYCODE flag from windows string conversions ([#6730](https://github.com/osquery/osquery/pull/6730))
- Fix memory leak in the dbus classes ([#6773](https://github.com/osquery/osquery/pull/6773))
- Change the kernel_modules size column type to BIGINT ([#6712](https://github.com/osquery/osquery/pull/6712))
### Documentation
- Add a README.md to source-based libraries ([#6686](https://github.com/osquery/osquery/pull/6686))
- Fix spelling typos ([#6705](https://github.com/osquery/osquery/pull/6705))
- Journald Audit Logs Masking Documentation ([#6748](https://github.com/osquery/osquery/pull/6748))
### Build
- CI: Provide built packages as Azure artifacts ([#6772](https://github.com/osquery/osquery/pull/6772))
- CI: Python installation improvements on Windows ([#6764](https://github.com/osquery/osquery/pull/6764))
- CI: Update brew scripts ([#6794](https://github.com/osquery/osquery/pull/6794))
- CMake: Disable BPF support if the LLVM libs are not compatible ([#6746](https://github.com/osquery/osquery/pull/6746))
- CMake: Use CPACK_RPM_PACKAGE_RELEASE ([#6805](https://github.com/osquery/osquery/pull/6805))
- CMake: Add max version limit to 3.18.0 on Linux ([#6801](https://github.com/osquery/osquery/pull/6801))
- Change urls for submodules gpg-error, libgcrypt, libcap ([#6768](https://github.com/osquery/osquery/pull/6768))
- Reduce linkage requirements for tests ([#6715](https://github.com/osquery/osquery/pull/6715))
- Remove a Buck leftover ([#6799](https://github.com/osquery/osquery/pull/6799))
- Remove boost workaround introduced in #5591 for string_view ([#6771](https://github.com/osquery/osquery/pull/6771))
- Tests: Fix tests on Catalina ([#6704](https://github.com/osquery/osquery/pull/6704))
- Update cmake_minum_required to 3.17.5 and pin version in CI ([#6770](https://github.com/osquery/osquery/pull/6770))
- build: Fix Windows build on newer MSVC ([#6732](https://github.com/osquery/osquery/pull/6732))
- extensions: Always compile examples to prevent them from breaking ([#6747](https://github.com/osquery/osquery/pull/6747))
### Security Issues
- Add SQLite authorizer to mitgate CVE-2020-26273 / GHSA-4g56-2482-x7q8 (https://github.com/osquery/osquery/commit/c3f9a3dae22d43ed3b4f6a403cbf89da4cba7c3c)
### Packs
- Updated unwanted-chrome-extensions ([#6720](https://github.com/osquery/osquery/pull/6720))
- Restrict the usb_devices pack to Posix ([#6739](https://github.com/osquery/osquery/pull/6739))
- Add Reptile rootkit to ossec-rootkit pack ([#6703](https://github.com/osquery/osquery/pull/6703))
2020-12-15T04:28:40+00:00osquery 4.7.0osquery 4.7.02021-03-12T19:03:02+00:00Commits from 21 contributors! Thank you all!
### New Features
- Add `concat` and `concat_ws` sql functions ([#6927](https://github.com/osquery/osquery/pull/6927))
- Update the scheduler to log the query name at info level ([#6934](https://github.com/osquery/osquery/pull/6934))
- Add support for SQLite RPM databases ([#6939](https://github.com/osquery/osquery/pull/6939))
### Table Changes
- Add `computer` column to Windows Eventlogs ([#6952](https://github.com/osquery/osquery/pull/6952))
- Add `docker_image_history` table ([#6884](https://github.com/osquery/osquery/pull/6884))
- Add `filevault_status` column to disk_encryption table ([#6823](https://github.com/osquery/osquery/pull/6823))
- Add `location_services` table on macOS ([#6826](https://github.com/osquery/osquery/pull/6826))
- Add `shellbags` table ([#6949](https://github.com/osquery/osquery/pull/6949))
- Add `system_extensions` table on macOS ([#6863](https://github.com/osquery/osquery/pull/6863))
- Add `systemd_units` table ([#6593](https://github.com/osquery/osquery/pull/6593))
- Add `ycloud_instance_metadata` table ([#6961](https://github.com/osquery/osquery/pull/6961))
- Fix loading of YARA rules on Windows ([#6893](https://github.com/osquery/osquery/pull/6893))
- Fix macOS OpenDirectory attribute mismatch ([#6816](https://github.com/osquery/osquery/pull/6816))
- Update `augeas` table not to autoload system lenses ([#6980](https://github.com/osquery/osquery/pull/6980))
- Update `chrome_extensions` table -- more browser support and tests ([#6780](https://github.com/osquery/osquery/pull/6780))
- Update `office_mru` table to correct platforms ([#6827](https://github.com/osquery/osquery/pull/6827))
- Update aws table to include macOS ([#6817](https://github.com/osquery/osquery/pull/6817))
### Under the Hood improvements
- Remove Azure Pipelines ([#6953](https://github.com/osquery/osquery/pull/6953))
- Disable deprecated TLS versions 1.0, 1.1 ([#6910](https://github.com/osquery/osquery/pull/6910))
- Use librpm bdb_ro backend and remove bdb ([#6931](https://github.com/osquery/osquery/pull/6931))
- bpf: Improve execve/execveat tracing, add AArch64 build support ([#6802](https://github.com/osquery/osquery/pull/6802))
- Use a distinct carver `request_id` and add this to the schema ([#6959](https://github.com/osquery/osquery/pull/6959))
- Initialize TLSLogForwarder before enrollment check ([#6958](https://github.com/osquery/osquery/pull/6958))
- Put noisy thrift logs behind a flag ([#6951](https://github.com/osquery/osquery/pull/6951))
- Fix bug in windows thrift, causing named pipe closing ([#6937](https://github.com/osquery/osquery/pull/6937))
- Remove unused/experimental ebpf code ([#6879](https://github.com/osquery/osquery/pull/6879))
- Remove unused ev2 code ([#6878](https://github.com/osquery/osquery/pull/6878))
- Refactor the eventing framework to reduce disk IO and improve performance([#6610](https://github.com/osquery/osquery/pull/6610))
### Bug Fixes
- Add `journal_mode` to the sqlite authorizer PRAGMAs ([#6999](https://github.com/osquery/osquery/pull/6999))
- Add `table_info` to the sqlite authorizer PRAGMAs ([#6814](https://github.com/osquery/osquery/pull/6814))
- Always use BIGINT macro for `long long` data ([#6986](https://github.com/osquery/osquery/pull/6986))
- Copy JSON objects to avoid MemoryPool buildup ([#6957](https://github.com/osquery/osquery/pull/6957))
- Do not call unconfigured subscribers errors ([#6847](https://github.com/osquery/osquery/pull/6847))
- Do not ignore mountpoints that have the same mount path ([#6871](https://github.com/osquery/osquery/pull/6871))
- Do not start scheduler when shutting down ([#6960](https://github.com/osquery/osquery/pull/6960))
- Don't mark scope and key columns as index in selinux_settings table ([#6872](https://github.com/osquery/osquery/pull/6872))
- Fix `augeas` table output bug for non-path entries ([#6981](https://github.com/osquery/osquery/pull/6981))
- Fix `pids` column in `docker_container_stats` table ([#6965](https://github.com/osquery/osquery/pull/6965))
- Fix additional relative path check in Yara for Windows ([#6894](https://github.com/osquery/osquery/pull/6894))
- Fix config validation oom with duplicated keys ([#6876](https://github.com/osquery/osquery/pull/6876))
- Fix data type macro used for 64-bit timestamp variables ([#6897](https://github.com/osquery/osquery/pull/6897))
- Fix error in `process_open_files` inode need stoul, not stoi ([#6983](https://github.com/osquery/osquery/pull/6983))
- Fix leaks when a query fails from the shell ([#6849](https://github.com/osquery/osquery/pull/6849))
- Fix mem leak regression with Windows sids API ([#6984](https://github.com/osquery/osquery/pull/6984))
- Make Group ID columns consistent across Windows tables ([#6987](https://github.com/osquery/osquery/pull/6987))
- When iterating /proc, use individual try/catch so catch partial failures ([#6933](https://github.com/osquery/osquery/pull/6933))
- augeas: Clear aug pointer on error ([#6973](https://github.com/osquery/osquery/pull/6973))
### Documentation
- Add 4.6.0 CHANGELOG ([#6809](https://github.com/osquery/osquery/pull/6809))
- Add 4.7.0 CHANGELOG ([#6985](#https://github.com/osquery/osquery/pull/6985))
- Add docs for TLS enroll max attempts ([#6888](https://github.com/osquery/osquery/pull/6888))
- Change reference about Azure Pipelines to GitHub Actions ([#6988](https://github.com/osquery/osquery/pull/6988))
- Clarify FIM exclude category documentation ([#6966](https://github.com/osquery/osquery/pull/6966))
- Document retrieval of available tables/columns via SQL ([#6812](https://github.com/osquery/osquery/pull/6812))
- Fix Github Actions status badge in the README ([#6908](https://github.com/osquery/osquery/pull/6908))
- Fix all broken or redirected URLs and references ([#6835](https://github.com/osquery/osquery/pull/6835))
- Fix broken URL in docs ([#6882](https://github.com/osquery/osquery/pull/6882))
- Fix incorrect Slack URLs ([#6844](https://github.com/osquery/osquery/pull/6844))
- Fix packs discovery queries documentation ([#6946](https://github.com/osquery/osquery/pull/6946))
- Fix reference to a Powershell script on Windows ([#6936](https://github.com/osquery/osquery/pull/6936))
- Fix typos in source code ([#6901](https://github.com/osquery/osquery/pull/6901))
- Improve explanations of event control flags ([#6954](https://github.com/osquery/osquery/pull/6954))
- Spellcheck and Markdown edits ([#6899](https://github.com/osquery/osquery/pull/6899))
- Update README to include release process comment ([#6877](https://github.com/osquery/osquery/pull/6877))
- Update documentation about denylist schedule key ([#6922](https://github.com/osquery/osquery/pull/6922))
- Update macOS OpenBSM configuration ([#6916](https://github.com/osquery/osquery/pull/6916))
- Update the Linux install steps and package listing ([#6956](https://github.com/osquery/osquery/pull/6956))
- Update the info about osquery's TLS version support ([#6963](https://github.com/osquery/osquery/pull/6963))
### Build
- Fix reference to a Powershell script on Windows ([#6936](https://github.com/osquery/osquery/pull/6936))
- Fix typos in source code ([#6901](https://github.com/osquery/osquery/pull/6901))
- Improve explanations of event control flags ([#6954](https://github.com/osquery/osquery/pull/6954))
- Spellcheck and Markdown edits ([#6899](https://github.com/osquery/osquery/pull/6899))
- Update README to include release process comment ([#6877](https://github.com/osquery/osquery/pull/6877))
- Update documentation about denylist schedule key ([#6922](https://github.com/osquery/osquery/pull/6922))
- Update macOS OpenBSM configuration ([#6916](https://github.com/osquery/osquery/pull/6916))
- Update the Linux install steps and package listing ([#6956](https://github.com/osquery/osquery/pull/6956))
- Update the info about osquery's TLS version support ([#6963](https://github.com/osquery/osquery/pull/6963))
### Build
- CI: Add a RelWithDebInfo Linux job to generate packages ([#6838](https://github.com/osquery/osquery/pull/6838))
- CI: Add support for GitHub Actions ([#6885](https://github.com/osquery/osquery/pull/6885))
- CI: Add unit tests for RPM DB querying ([#6919](https://github.com/osquery/osquery/pull/6919))
- CI: Fix ExtendedAttributesTableTests failing due to an unexpected attribute ([#6942](https://github.com/osquery/osquery/pull/6942))
- CI: Fix StartupItemTest failing due to unexpected values ([#6940](https://github.com/osquery/osquery/pull/6940))
- CI: Fix SystemControlsTest adding sunrpc as an expected subsystem ([#6932](https://github.com/osquery/osquery/pull/6932))
- CI: Fix XattrTests failing due to unexpected attribute name ([#6941](https://github.com/osquery/osquery/pull/6941))
- CI: Fix an incorrect check in StartupItems test ([#6950](https://github.com/osquery/osquery/pull/6950))
- CI: Fix wifi_tests on macOS 10.15 and above ([#6724](https://github.com/osquery/osquery/pull/6724))
- CI: Move cppcheck step after the tests ([#6845](https://github.com/osquery/osquery/pull/6845))
- CI: Permit running formatting earlier in the CI ([#6836](https://github.com/osquery/osquery/pull/6836))
- CI: Remove incorrect 2to3 symlink breaking Python brew upgrade ([#6819](https://github.com/osquery/osquery/pull/6819))
- CI: Remove unused empty test file ([#6918](https://github.com/osquery/osquery/pull/6918))
- CI: Remove unused tests for Rocksdb and Inmemory db plugins ([#6900](https://github.com/osquery/osquery/pull/6900))
- CI: Update XCode to 12.3 and Update min macOS version to 10.12 ([#6896](https://github.com/osquery/osquery/pull/6896), [#6913](https://github.com/osquery/osquery/pull/6913))
- CI: Update macOS agent to 10.15 Catalina ([#6680](https://github.com/osquery/osquery/pull/6680))
- CMake: Add -pthread compile option on posix platforms ([#6909](https://github.com/osquery/osquery/pull/6909))
- CMake: Add Valgrind support ([#6834](https://github.com/osquery/osquery/pull/6834))
- CMake: Add an option to disable building AWS tables and library ([#6831](https://github.com/osquery/osquery/pull/6831))
- CMake: Add an option to disable building libdpkg tables and library ([#6848](https://github.com/osquery/osquery/pull/6848))
- CMake: Detect missing headers during include namespace generation ([#6855](https://github.com/osquery/osquery/pull/6855))
- CMake: Do not attempt to dllimport Thrift symbols ([#6856](https://github.com/osquery/osquery/pull/6856))
- CMake: Do not compile Windows libraries with debug symbols ([#6833](https://github.com/osquery/osquery/pull/6833))
- CMake: Explicitly set the MSVC runtime library ([#6818](https://github.com/osquery/osquery/pull/6818))
- CMake: Fix amalgamated tables generation on change ([#6832](https://github.com/osquery/osquery/pull/6832))
- CMake: Fix platformtablecontaineripc include namespace generation ([#6853](https://github.com/osquery/osquery/pull/6853))
- CMake: Further fix amalgamation file gen on change ([#6854](https://github.com/osquery/osquery/pull/6854))
- CMake: Refactor and rename fuzzers build flag ([#6829](https://github.com/osquery/osquery/pull/6829))
- CMake: Significantly speed up configuration phase ([#6914](https://github.com/osquery/osquery/pull/6914))
- CMake: Use make jobserver for OpenSSL on Linux and macOS ([#6821](https://github.com/osquery/osquery/pull/6821))
- CPack: Remove extraneous lenses directory for augues on macOS ([#6998](https://github.com/osquery/osquery/pull/6998))
- Change libdpkg submodule url to our own GitHub mirror ([#6903](https://github.com/osquery/osquery/pull/6903))
- Disable incremental linking to reduce build size on Windows ([#6898](https://github.com/osquery/osquery/pull/6898))
- GitHub Actions: Fix .deb artifacts, add scheduled builds ([#6920](https://github.com/osquery/osquery/pull/6920))
- Remove `hash` and `yara` table from fuzz harnesses ([#6972](https://github.com/osquery/osquery/pull/6972))
- libraries: Reduce the compilation units from libarchive ([#6886](https://github.com/osquery/osquery/pull/6886))
- libraries: Remove the last usage of sqlite3 from sleuthkit ([#6858](https://github.com/osquery/osquery/pull/6858))
- libraries: Rename yara str functions to avoid symbol collisions ([#6917](https://github.com/osquery/osquery/pull/6917))
- libraries: Update librpm to version 4.16.1.2 ([#6850](https://github.com/osquery/osquery/pull/6850))
- libraries: Update openssl to version 1.1.1i ([#6820](https://github.com/osquery/osquery/pull/6820))
- libraries: Update thrift to version 0.13.0 ([#6822](https://github.com/osquery/osquery/pull/6822))
### Hardening
- Update CODEOWNERS to reflect existing teams ([#6955](https://github.com/osquery/osquery/pull/6955), [#6975](https://github.com/osquery/osquery/pull/6975))
- Restrict access to Thrift server pipe on Windows ([#6875](https://github.com/osquery/osquery/pull/6875))
- Fix a leak in libdpkg when querying the `deb_packages` table ([#6892](https://github.com/osquery/osquery/pull/6892))
- Fix UB and dangerous casting in the pubsub framework ([#6881](https://github.com/osquery/osquery/pull/6881))
- Fix heap-use-after-free in deregisterEventSubscriber ([#6880](https://github.com/osquery/osquery/pull/6880))
- Thift patch to support security configuration ([#6846](https://github.com/osquery/osquery/pull/6846))
- Improve config fuzzer dictionary creation script ([#6860](https://github.com/osquery/osquery/pull/6860))
- Avoid running queries for views when fuzzing ([#6859](https://github.com/osquery/osquery/pull/6859))
2021-03-12T19:03:02+00:00osquery 0.0.2osquery 0.0.22021-04-15T11:48:17+00:002021-04-15T11:48:17+00:00osquery 4.8.0osquery 4.8.02021-04-19T02:42:24+00:00## [4.8.0](https://github.com/osquery/osquery/releases/tag/4.8.0)
[Git Commits](https://github.com/osquery/osquery/compare/4.7.0...4.8.0)
Representing commits from 14 contributors! Thank you all.
This version fixes a regression introduced in 4.7.0 related to events expiration optimization. Please read ([#7055](https://github.com/osquery/osquery/pull/7055)) for more information.
This release upgrades openssl, as is general good practice. Osquery is not known to be effected by any security issues in OpenSSL.
### New Features
- shell: Add `.connect` meta command ([#6944](https://github.com/osquery/osquery/pull/6944))
### Table Changes
- Add `seccomp_events` table for Linux ([#7006](https://github.com/osquery/osquery/pull/7006))
- Add `shortcut_files` table for Windows ([#6994](https://github.com/osquery/osquery/pull/6994))
### Under the Hood improvements
- Removing Keyboard Event Taps from osx-attacks pack ([#7023](https://github.com/osquery/osquery/pull/7023))
- Refactor watcher out of singleton pattern ([#7042](https://github.com/osquery/osquery/pull/7042))
- Small events subscriber refactor to increase test coverage ([#7050](https://github.com/osquery/osquery/pull/7050))
- Setting non-required `deb_packages` fields as optional in test ([#7001](https://github.com/osquery/osquery/pull/7001))
### Bug Fixes
- Handle events optimization edge cases ([#7060](https://github.com/osquery/osquery/pull/7060))
- Fix optimization for multiple queries using the same subscriber ([#7055](https://github.com/osquery/osquery/pull/7055))
- Use epoch and counter for events-based queries ([#7051](https://github.com/osquery/osquery/pull/7051))
- Guard node key to prevent duplicate enrollments ([#7052](https://github.com/osquery/osquery/pull/7052))
- Change windows calculation for physical_memory ([#7028](https://github.com/osquery/osquery/pull/7028))
- Free using WTSFreeMemoryEx for WTSEnumerateSessionsExW ([#7039](https://github.com/osquery/osquery/pull/7039))
- Release variable in Windows data conversation ([#7024](https://github.com/osquery/osquery/pull/7024))
- Change `chrome_extensions` warnings to verbose ([#7032](https://github.com/osquery/osquery/pull/7032))
- Add transactions to the SQLite authorizer PRAGMAs ([#7029](https://github.com/osquery/osquery/pull/7029))
- Change Windows messages to verbose ([#7027](https://github.com/osquery/osquery/pull/7027))
- Fix scheduler to print the correct number of elapsed seconds ([#7016](https://github.com/osquery/osquery/pull/7016))
### Documentation
- Fix `tls_enroll_max_attempts` flag name in the documentation ([#7049](https://github.com/osquery/osquery/pull/7049))
- Improve docs on FIM, mention NTFS and Audit, etc. ([#7036](https://github.com/osquery/osquery/pull/7036))
- config: Add docs for the events top-level-key ([#7040](https://github.com/osquery/osquery/pull/7040))
- Add funding link on GitHub generated page ([#7043](https://github.com/osquery/osquery/pull/7043))
- Correct the example in the `windows_events` table spec ([#7035](https://github.com/osquery/osquery/pull/7035))
- Correct docs about OpenSSL and TLS behavior ([#7033](https://github.com/osquery/osquery/pull/7033))
- Update docs to describe how to build for aarch64/arm64 (#6285) ([#6970](https://github.com/osquery/osquery/pull/6970))
- Add a note on enabling Windows to build with CMake's long paths ([#7010](https://github.com/osquery/osquery/pull/7010))
- Add 4.8.0 CHANGELOG ([#7057](https://github.com/osquery/osquery/pull/7057))
### Build
- Add an option to enable incremental linking on Windows ([#7044](https://github.com/osquery/osquery/pull/7044))
- Remove Buck leftovers that supported building with old versions of OpenSSL ([#7034](https://github.com/osquery/osquery/pull/7034))
- Add build_aarch64 workflow for push ([#7014](https://github.com/osquery/osquery/pull/7014))
- Move CI to using docker from osquery ([#7012](https://github.com/osquery/osquery/pull/7012))
- Update dockerfile to multiplatform ([#7011](https://github.com/osquery/osquery/pull/7011))
- Run GH Actions workflows on all tags ([#7004](https://github.com/osquery/osquery/pull/7004))
- Disable BPF events tests if OSQUERY_BUILD_BPF is false ([#7002](https://github.com/osquery/osquery/pull/7002))
- libs: Update OpenSSL to version 1.1.1k ([#7026](https://github.com/osquery/osquery/pull/7026))
2021-04-19T02:42:24+00:00osquery 4.9.0osquery 4.9.02021-06-14T14:39:45+00:00Representing commits from 16 contributors! Thank you all.
### New Features
- Add filesystem logrotate feature ([#7015](https://github.com/osquery/osquery/pull/7015))
- Add Non-Functional EndpointSecurity based process events to macOS (Requires updated codesigning due in 5.0) ([#7046](https://github.com/osquery/osquery/pull/7046))
### Table Changes
- Add `mdm_managed` column to `system_extensions` on macOS ([#6915](https://github.com/osquery/osquery/pull/6915))
- Add `prefetch` table on Windows ([#7076](https://github.com/osquery/osquery/pull/7076))
- Add support for IMDSv2 to AWS tables ([#7084](https://github.com/osquery/osquery/pull/7084))
- Enable container stats on docker containers that don't have traditional networks ([#7145](https://github.com/osquery/osquery/pull/7145))
- Update `homebrew_packages` to include new prefix, and allow specifying alternate prefixes ([#7117](https://github.com/osquery/osquery/pull/7117))
- Update `ntfs_acl_permissions` to list all ACE entries (using `GetAce()`) ([#7114](https://github.com/osquery/osquery/pull/7114))
- Update `processes` table to display additional Windows attributes (`secured`, `protected`, `virtual`, `elevated`) ([#7121](https://github.com/osquery/osquery/pull/7121))
- Update how `package_install_history` identifies the packageIdentifiers key ([#7099](https://github.com/osquery/osquery/pull/7099))
- Update how `identifier` is calculated in `chrome_extensions` ([#7124](https://github.com/osquery/osquery/pull/7124))
### Under the Hood improvements
- Improve speed of osquery shutdown procedure ([#7077](https://github.com/osquery/osquery/pull/7077))
- Improve shutdown speed during initialization ([#7106](https://github.com/osquery/osquery/pull/7106))
- Update website generators ([#7136](https://github.com/osquery/osquery/pull/7136))
- CLI flag to allow osquery to keep retrying enrollment (instead of exiting) ([#7125](https://github.com/osquery/osquery/pull/7125))
- rocksdb: Do not fsync WAL writes ([#7094](https://github.com/osquery/osquery/pull/7094))
- Move CPack packaging to a dedicated repository ([#7059](https://github.com/osquery/osquery/pull/7059))
- Restore thrift socket 5min timeout ([#7072](https://github.com/osquery/osquery/pull/7072))
- Consolidate syscalls to a single audit rule ([#7063](https://github.com/osquery/osquery/pull/7063))
### Bug Fixes
- Add current WMI location for Dell BIOS info ([#7103](https://github.com/osquery/osquery/pull/7103))
- Correct RocksDB error code and subcode printing on open failure ([#7069](https://github.com/osquery/osquery/pull/7069))
- Fix `pipe_channel` not reading all data in a message ([#7139](https://github.com/osquery/osquery/pull/7139))
- Fix crash and deadlocks in recursive logging ([#7127](https://github.com/osquery/osquery/pull/7127))
- Fix custom `curl_certificate` timeouts ([#7151](https://github.com/osquery/osquery/pull/7151))
- Fix extensions crash on shutdown ([#7075](https://github.com/osquery/osquery/pull/7075))
- Handle updated paths on various macOS tables -- `xprotect_entries`, `xprotect_meta`, `launchd` ([#7138](https://github.com/osquery/osquery/pull/7138), [#7154](https://github.com/osquery/osquery/pull/7154))
- Trigger event cleanup checks every 256 events ([#7143](https://github.com/osquery/osquery/pull/7143))
- Update generating an extension uuid to be thread safe ([#7135](https://github.com/osquery/osquery/pull/7135))
- Watchdog should wait for the worker to shutdown ([#7116](https://github.com/osquery/osquery/pull/7116))
### Documentation
- Update process auditing requirements documentation ([#7102](https://github.com/osquery/osquery/pull/7102))
- Update website docs indicating windows support for YARA tables ([#7130](https://github.com/osquery/osquery/pull/7130))
- Add 4.9.0 CHANGELOG ([#7152](https://github.com/osquery/osquery/pull/7152))
### Build
- Add Apple provisioning profile for distribution ([#7119](https://github.com/osquery/osquery/pull/7119))
- Add more tests for events expiration ([#7071](https://github.com/osquery/osquery/pull/7071))
- CI: Regenerate sccache cache when compiler version changes ([#7081](https://github.com/osquery/osquery/pull/7081))
- Fix flaky test test_daemon_sigint by waiting for pidfile ([#7095](https://github.com/osquery/osquery/pull/7095))
- Fix icon in Windows packaging ([#7148](https://github.com/osquery/osquery/pull/7148))
- Minor cleanup of unused variables ([#7128](https://github.com/osquery/osquery/pull/7128))
- Print extension SDK minimum version required when failing to load ([#7074](https://github.com/osquery/osquery/pull/7074))
- Remove POSIX-only `-fexceptions` flag on Windows ([#7126](https://github.com/osquery/osquery/pull/7126))
- Remove duplicated osquery_utils_aws_tests-test ([#7078](https://github.com/osquery/osquery/pull/7078))
- Remove flaky test decorators for python tests ([#7070](https://github.com/osquery/osquery/pull/7070))
- Update SQLite to version 3.35.5 ([#7090](https://github.com/osquery/osquery/pull/7090))
- Update librdkafka to version 1.7.0 ([#7134](https://github.com/osquery/osquery/pull/7134))
- Update libyara to version 4.1.1 ([#7133](https://github.com/osquery/osquery/pull/7133))
2021-06-14T14:39:45+00:00osquery 5.0.0osquery 5.0.02021-08-26T18:25:13+00:00Initial draft of the 5.0. This release may be deleted!2021-08-26T18:25:13+00:00osquery 5.0.1osquery 5.0.12021-09-03T03:39:13+00:00Next 5.0 beta! Moving along2021-09-03T03:39:13+00:00osquery 5.1.0osquery 5.1.02021-12-03T15:06:13+00:005.1.0 notes coming soon!2021-12-03T15:06:13+00:00osquery 5.2.0osquery 5.2.02021-12-29T02:28:52+00:00Apple M1 Support! Release notes coming soon2021-12-29T02:28:52+00:00osquery 5.2.1osquery 5.2.12022-01-18T18:47:56+00:00yara bug fix2022-01-18T18:47:56+00:00osquery 5.2.2osquery 5.2.22022-02-04T16:30:54+00:00Native M1 Support. Very Exciting. Release notes coming soon2022-02-04T16:30:54+00:00osquery 5.2.3osquery 5.2.32022-04-05T22:05:20+00:00Full Commits: https://github.com/osquery/osquery/compare/5.2.2...5.2.32022-04-05T22:05:20+00:00osquery 5.3.0osquery 5.3.02022-05-24T20:33:25+00:00<a name="5.3.0"></a>
## [5.3.0](https://github.com/osquery/osquery/releases/tag/5.3.0)
[Git Commits](https://github.com/osquery/osquery/compare/5.2.3...5.3.0)
osquery 5.3.0 brings several table improvements and bugfixes.
Worth mentioning also the deprecation of the `smart_drive_info` table
and the new warning added when incorrectly configuring a CLI only flag
via the config file. In the next release CLI only flags will not be
configurable through the config file or refresh anymore.
This release represents commits from 15 contributors! Thank you all.
### Deprecation Notices
- Deprecate unmaintainable legacy table, `smart_drive_info` [#7464](https://github.com/osquery/osquery/issues/7464)
### New Features
- Add the option `tls_disable_status_log` to prevent status logs from being sent via TLS [#7550](https://github.com/osquery/osquery/pull/7550)
- Add SQLite function `in_cidr_block` to check if IPv4/v6 addresses are within the supplied CIDR block [#7563](https://github.com/osquery/osquery/pull/7563)
### Table Changes
- Add the `admindir` column to the `deb_packages` table to parse package databases on different paths [#7549](https://github.com/osquery/osquery/pull/7549)
- Implement and fix `wifi_networks` on macOS Big Sur and newer [#7503](https://github.com/osquery/osquery/pull/7503)
- Add windows/darwin support to `npm_packages` [#7536](https://github.com/osquery/osquery/pull/7536)
- Move `apt_sources` and `yum_sources` tables to linux only [#7537](https://github.com/osquery/osquery/pull/7537)
- Add homebrew paths to the `python_packages` table [#7535](https://github.com/osquery/osquery/pull/7535)
- Mark `wall_time` column in `osquery_schedule` as hidden [#7501](https://github.com/osquery/osquery/pull/7501)
- Add new metrics and improve description of existing ones in `osquery_schedule` [#7438](https://github.com/osquery/osquery/pull/7438)
- Add the `mirrorlist` column in the table `yum_sources` [#7479](https://github.com/osquery/osquery/pull/7479)
- Implement `output_size` for `osquery_schedule` [#7436](https://github.com/osquery/osquery/pull/7436)
- `deb_packages` table: Use additional instead of index for the `admindir` column [#7573](https://github.com/osquery/osquery/pull/7573)
- `certificates` table: Add Linux support [#7570](https://github.com/osquery/osquery/pull/7570)
- Add `translated` column to `processes` table to indicate whether the process is running under Apple Rosetta [#7507](https://github.com/osquery/osquery/pull/7507)
- Add the "internet password" type to the macOS `keychain_items` table [#7576](https://github.com/osquery/osquery/pull/7576)
- Add `original filename` column to `file` table on Windows [#7156](https://github.com/osquery/osquery/pull/7156)
### Bug Fixes
- Fix watchdog not killing unhealthy worker/extension fast enough [#7474](https://github.com/osquery/osquery/pull/7474)
- Fix the `test_http_server.py` `--persist` option [#7497](https://github.com/osquery/osquery/pull/7497)
- Update`profile.py --leaks` for python3 [#7534](https://github.com/osquery/osquery/pull/7534)
- Fixes osquery tls connections to aws kinesis when tls_server_certs is set [#7450](https://github.com/osquery/osquery/pull/7450)
- Fix parsing issue when a backslash as the last character on sudoers file line [#7440](https://github.com/osquery/osquery/pull/7440)
- Change the JSON of the results coming from an event scheduled query to an array [#7434](https://github.com/osquery/osquery/pull/7434)
- Fix globToRegex truncating UTF16 characters [#7430](https://github.com/osquery/osquery/pull/7430)
- Prevent hanging when the WMI server does not respond [#7429](https://github.com/osquery/osquery/pull/7429)
- Fix `python_packages` table so that it lists python packages from any user Python installations [#7414](https://github.com/osquery/osquery/pull/7414)
- Set string size limit on thrift protocol factory to prevent a crash [#7484](https://github.com/osquery/osquery/pull/7484)
- Fix driver image path in `drivers` table [#7444](https://github.com/osquery/osquery/pull/7444)
- Do not remove nonblocking flag when reading "special" files, to prevent hangs [#7530](https://github.com/osquery/osquery/pull/7530)
- Fix crash due to interaction between distributed and config plugin [#7504](https://github.com/osquery/osquery/pull/7504)
- bpf: Disable the BPF publisher in case of error [#7500](https://github.com/osquery/osquery/pull/7500)
- Warn about setting CLI_FLAGs in the config [#7583](https://github.com/osquery/osquery/pull/7583)
- Explicitly set context for the tables reading utmpx databases [#7578](https://github.com/osquery/osquery/pull/7578)
- bpf: Improve socket event handling [#7446](https://github.com/osquery/osquery/pull/7446)
- certificates: Refactor the OpenSSL utilities [#7581](https://github.com/osquery/osquery/pull/7581)
- Fix shared_resources accessing uninitialized variables [#7600](https://github.com/osquery/osquery/pull/7600)
### Under the Hood improvements
- Implement a performant cache for users and groups on Windows [#7516](https://github.com/osquery/osquery/pull/7516)
- Replace WmiRequest constructor with static factory method to improve error handling and prevent crashes [#7489](https://github.com/osquery/osquery/pull/7489)
- Remove redundant string conversion [#7603](https://github.com/osquery/osquery/pull/7603)
### Build
- Fix DebPackages.test_sanity test when the `size` column is empty [#7569](https://github.com/osquery/osquery/pull/7569)
- libs: Update libdpkg from version v1.19.0.5 to v1.21.7 [#7549](https://github.com/osquery/osquery/pull/7549)
- CI: Restore some release checks [#7558](https://github.com/osquery/osquery/pull/7558)
- Prevent ebpfpub linking against the system zlib [#7557](https://github.com/osquery/osquery/pull/7557)
- Fix mdfind.test_sanity flaky behavior [#7533](https://github.com/osquery/osquery/pull/7533)
- Enable fuzzing and Asan on Windows, enable Asan on macOS [#7470](https://github.com/osquery/osquery/pull/7470)
- Update cppcheck to version 2.6.3 and skip analysis for third party code [#7455](https://github.com/osquery/osquery/pull/7455)
- Change `cpu_info` test to expect *at least* one socket, not just one [#7490](https://github.com/osquery/osquery/pull/7490)
- Fix third party libraries flags leaking to osquery targets [#7480](https://github.com/osquery/osquery/pull/7480)
- Add third party libraries target [#7467](https://github.com/osquery/osquery/pull/7467)
- Do not run clang-tidy on third party libraries [#7432](https://github.com/osquery/osquery/pull/7432)
- CI: Create github workflow target to gate mergeability [#7427](https://github.com/osquery/osquery/pull/7427)
- Fix some warnings about unrecognized special characters in the Windows event log test [#7478](https://github.com/osquery/osquery/pull/7478)
- Change where the macOS Info.plist is generated [#7566](https://github.com/osquery/osquery/pull/7566)
- Add OSQUERY_ENABLE_THREAD_SANITIZER to optionally enable TSan [#6997](https://github.com/osquery/osquery/pull/6997)
- Add an option to specify a path to the openssl archive [#7559](https://github.com/osquery/osquery/pull/7559)
- packs: Update reverse shell query pack to check for a valid remote_port [#7567](https://github.com/osquery/osquery/pull/7567)
- Remove the test_daemon_sighup test [#7584](https://github.com/osquery/osquery/pull/7584)
### Documentation
- docs: remove FreeBSD [#7508](https://github.com/osquery/osquery/pull/7508)
- Pin Jinja2 ReadTheDocs dependency to 3.0.3 [#7533](https://github.com/osquery/osquery/pull/7533)
- CHANGELOG 5.2.3 [#7571](https://github.com/osquery/osquery/pull/7571)
- CHANGELOG 5.2.2 [#7447](https://github.com/osquery/osquery/pull/7447)
- Bump mkdocs from 1.1.2 to 1.2.3 in /docs [#7457](https://github.com/osquery/osquery/pull/7457)
- Replace OS X with macOS in table specs [#7587](https://github.com/osquery/osquery/pull/7587)
- Update `osquery.example.conf` to omit the CLI only flags [#7595](https://github.com/osquery/osquery/pull/7595)2022-05-24T20:33:25+00:00osquery 5.4.0osquery 5.4.02022-07-06T21:20:21+00:002022-07-06T21:20:21+00:00osquery 5.5.0osquery 5.5.02022-08-12T17:47:19+00:00draft2022-08-12T17:47:19+00:00osquery 5.5.1osquery 5.5.12022-08-18T13:24:43+00:00Draft! (think 5.5.0 plus sqlite)2022-08-18T13:24:43+00:00osquery 5.6.0osquery 5.6.02022-10-10T16:57:28+00:00Draft!2022-10-10T16:57:28+00:00osquery 5.7.0osquery 5.7.02022-12-06T19:00:16+00:00Draft2022-12-06T19:00:16+00:00osquery 5.8.0osquery 5.8.02023-02-24T19:25:29+00:002023-02-24T19:25:29+00:00osquery 5.8.1osquery 5.8.12023-03-01T20:45:27+00:002023-03-01T20:45:27+00:00osquery 5.8.2osquery 5.8.22023-03-22T11:59:16+00:002023-03-22T11:59:16+00:00osquery 5.9.0osquery 5.9.02023-06-08T21:07:50+00:00_Draft_2023-06-08T21:07:50+00:00osquery 5.9.1osquery 5.9.12023-06-16T15:16:33+00:00Draft2023-06-16T15:16:33+00:00osquery 5.10.1osquery 5.10.12023-10-07T12:02:38+00:00[Git Commits](https://github.com/osquery/osquery/compare/5.9.1...5.10.1)
This release has several updates and bugfixes. Several improvements to various tables, and their handling.
One potential breaking change, is in how [the watchdog calculates CPU utilization](https://github.com/osquery/osquery/pull/8104).
Previously, this calculation was based on physical CPUs, now it is based on virtual cores. We believe this makes more sense with modern CPUs.
Representing commits from 18 contributors! Thank you all.
### New Features
- Add `--enable_watchdog_logging` flag and improve error messages ([#8070](https://github.com/osquery/osquery/pull/8070))
- Add `--aws_enforce_fips` to enforce AWS FIPS endpoints ([#8075](https://github.com/osquery/osquery/pull/8075))
- Add new AWS valid regions ([#8110](https://github.com/osquery/osquery/pull/8110))
- Implement `decorations_top_level` flag for status logs ([#8102](https://github.com/osquery/osquery/pull/8102))
### Table Changes
- Add new macOS SIP config flags ([#8101](https://github.com/osquery/osquery/pull/8101))
- Added `cloud`_id to `ycloud_instance_metadata` - the vm metadata table for Yandex Cloud ([#8086](https://github.com/osquery/osquery/pull/8086))
- Allow querying of kernel and filesystem drivers ([#8119](https://github.com/osquery/osquery/pull/8119))
- Update `es_process_file_events` adding support for open events, and for only triggering on `file_paths` ([#8114](https://github.com/osquery/osquery/pull/8114))
- Update `firefox_addons` to use rapidjson to parse and don't block on read ([#8089](https://github.com/osquery/osquery/pull/8089))
- Update macOS `es_process_events` table: quote spaces in command line and environment variables ([#8054](https://github.com/osquery/osquery/pull/8054))
- Update linux `disk_encryption` to recursively query parent crypt status ([#8052](https://github.com/osquery/osquery/pull/8052))
- Add, and revert, indexing on `block_devices` ([#8037](https://github.com/osquery/osquery/pull/8037), [#8151](https://github.com/osquery/osquery/pull/8151))
### Under the Hood improvements
- Add warnings when an enrollment secret cannot be found ([#8082](https://github.com/osquery/osquery/pull/8082))
- Avoid blocking when reading plist files ([#8099](https://github.com/osquery/osquery/pull/8099))
- Fix named virtual table create statement ([#8139](https://github.com/osquery/osquery/pull/8139))
- Remove forensicReadFile ([#8085](https://github.com/osquery/osquery/pull/8085))
- Substitute the TEXT macro with SQL_TEXT in table code ([#8091](https://github.com/osquery/osquery/pull/8091))
- Use JSON member iterator instead of rescanning ([#8122](https://github.com/osquery/osquery/pull/8122))
- core: Avoid checking if a file exists before opening ([#8087](https://github.com/osquery/osquery/pull/8087))
- improvement: Avoid unnecessary string conversions ([#8093](https://github.com/osquery/osquery/pull/8093))
- watchdog: Use virtual cores to calculate CPU utilization limit ([#8104](https://github.com/osquery/osquery/pull/8104))
### Bug Fixes
- Always lock event_index_mutex when accessing event_index map ([#8077](https://github.com/osquery/osquery/pull/8077))
- Check audit return values with <= ([#8125](https://github.com/osquery/osquery/pull/8125))
- Fix `wifi_survey` table not to crash if the ssid cannot be retrieved ([#8153](https://github.com/osquery/osquery/pull/8153))
### Documentation
- Add a list of Osquery fleet managers ([#7781](https://github.com/osquery/osquery/pull/7781))
- Add basic file carving documentation ([#8118](https://github.com/osquery/osquery/pull/8118))
- Changelog for 5.9.1 ([#8088](https://github.com/osquery/osquery/pull/8088))
- Fixed small doc error ([#8147](https://github.com/osquery/osquery/pull/8147))
- Update Automatic Table Construction example ([#8094](https://github.com/osquery/osquery/pull/8094))
- Update XCode version mentions to the proper one ([#8128](https://github.com/osquery/osquery/pull/8128))
- Update the description of `serial_number` in `connected_displays` ([#8113](https://github.com/osquery/osquery/pull/8113))
### Build
- Fix openssl build arch for Windows ARM64 ([#8134](https://github.com/osquery/osquery/pull/8134))
- Ignore CVE-2023-30571 ([#8065](https://github.com/osquery/osquery/pull/8065))
- Missing pragma/header guard for boottime.h ([#8117](https://github.com/osquery/osquery/pull/8117))
- Permit cross compiling for x86_64 on Apple Silicon ([#8136](https://github.com/osquery/osquery/pull/8136))
- build: update macos hosted github runner to macos-12 monterey ([#8100](https://github.com/osquery/osquery/pull/8100))
- ci: Fix DistributedTests.test_run_queries_with_denylisted_query test ([#8154](https://github.com/osquery/osquery/pull/8154))
- ci: Increase aarch64 available space by splitting the build ([#8131](https://github.com/osquery/osquery/pull/8131))
- ci: Increase disk space on the Linux x86_64 runner ([#8133](https://github.com/osquery/osquery/pull/8133))
- ci: Remove flakyness when removing unused packages on Linux ([#8144](https://github.com/osquery/osquery/pull/8144))
- cve: Ignore dbus CVE-2023-34969 ([#8126](https://github.com/osquery/osquery/pull/8126))
- cve: Ignore libcap CVE-2023-2603 ([#8127](https://github.com/osquery/osquery/pull/8127))
- cve: Update libmagic to 5.45 ([#8142](https://github.com/osquery/osquery/pull/8142))
- cve: Update lzma to 5.4.4 ([#8135](https://github.com/osquery/osquery/pull/8135))
- cve: Update openssl to 3.1.3 ([#8141](https://github.com/osquery/osquery/pull/8141))
- libs: Fix openssl build on aarch64 ([#8084](https://github.com/osquery/osquery/pull/8084))
- libs: Update openssl to 3.1.1 ([#8081](https://github.com/osquery/osquery/pull/8081))
- libs: Update openssl to 3.1.2 ([#8124](https://github.com/osquery/osquery/pull/8124))
- test: Fix leaks in inotify and rocksdb tests ([#8080](https://github.com/osquery/osquery/pull/8080))
2023-10-07T12:02:38+00:00osquery 5.10.2osquery 5.10.22023-10-22T19:38:25+00:00## [5.10.2](https://github.com/osquery/osquery/releases/tag/5.10.2)
[Git Commits](https://github.com/osquery/osquery/compare/5.9.1...5.10.2)
This release has several updates and bugfixes. Several improvements to various tables, and their handling.
One potential breaking change, is in how [the watchdog calculates CPU utilization](https://github.com/osquery/osquery/pull/8104).
Previously, this calculation was based on physical CPUs, now it is based on virtual cores. We believe this makes more sense with modern CPUs.
A second potential breaking change, is in PR [#8102](https://github.com/osquery/osquery/pull/8102). In addition to allowing decorations to the top level of the status logs, this PR normalizes the decorations format to the results log. In practice, this means that the `unixTime`, `severity` and `line` JSON fields are now numbers instead of strings.
Representing commits from 18 contributors! Thank you all.
### New Features
- Add `--enable_watchdog_debug` flag and improve watchdog error messages ([#8070](https://github.com/osquery/osquery/pull/8070))
- Add `--aws_enforce_fips` to enforce AWS FIPS endpoints ([#8075](https://github.com/osquery/osquery/pull/8075))
- Add new AWS valid regions ([#8110](https://github.com/osquery/osquery/pull/8110))
- Implement `decorations_top_level` flag for status logs ([#8102](https://github.com/osquery/osquery/pull/8102))
### Table Changes
- Add new macOS SIP config flags ([#8101](https://github.com/osquery/osquery/pull/8101))
- Added `cloud`_id to `ycloud_instance_metadata` - the vm metadata table for Yandex Cloud ([#8086](https://github.com/osquery/osquery/pull/8086))
- Allow querying of kernel and filesystem drivers ([#8119](https://github.com/osquery/osquery/pull/8119))
- Update `es_process_file_events` adding support for open events, and for only triggering on `file_paths` ([#8114](https://github.com/osquery/osquery/pull/8114))
- Update `firefox_addons` to use rapidjson to parse and don't block on read ([#8089](https://github.com/osquery/osquery/pull/8089))
- Update macOS `es_process_events` table: quote spaces in command line and environment variables ([#8054](https://github.com/osquery/osquery/pull/8054))
- Update linux `disk_encryption` to recursively query parent crypt status ([#8052](https://github.com/osquery/osquery/pull/8052))
- Add, and revert, indexing on `block_devices` ([#8037](https://github.com/osquery/osquery/pull/8037), [#8151](https://github.com/osquery/osquery/pull/8151))
### Under the Hood improvements
- Add warnings when an enrollment secret cannot be found ([#8082](https://github.com/osquery/osquery/pull/8082))
- Avoid blocking when reading plist files ([#8099](https://github.com/osquery/osquery/pull/8099))
- Fix named virtual table create statement ([#8139](https://github.com/osquery/osquery/pull/8139))
- Remove forensicReadFile ([#8085](https://github.com/osquery/osquery/pull/8085))
- Substitute the TEXT macro with SQL_TEXT in table code ([#8091](https://github.com/osquery/osquery/pull/8091))
- Use JSON member iterator instead of rescanning ([#8122](https://github.com/osquery/osquery/pull/8122))
- core: Avoid checking if a file exists before opening ([#8087](https://github.com/osquery/osquery/pull/8087))
- improvement: Avoid unnecessary string conversions ([#8093](https://github.com/osquery/osquery/pull/8093))
- watchdog: Use virtual cores to calculate CPU utilization limit ([#8104](https://github.com/osquery/osquery/pull/8104))
### Bug Fixes
- Always lock event_index_mutex when accessing event_index map ([#8077](https://github.com/osquery/osquery/pull/8077))
- Check audit return values with <= ([#8125](https://github.com/osquery/osquery/pull/8125))
- Fix `wifi_survey` table not to crash if the ssid cannot be retrieved ([#8153](https://github.com/osquery/osquery/pull/8153))
- Fix macOS EndpointSecurity FIM mute inversion for file paths ([#8166](https://github.com/osquery/osquery/pull/8166))
### Documentation
- Add a list of Osquery fleet managers ([#7781](https://github.com/osquery/osquery/pull/7781))
- Add basic file carving documentation ([#8118](https://github.com/osquery/osquery/pull/8118))
- Changelog for 5.9.1 ([#8088](https://github.com/osquery/osquery/pull/8088))
- Changelog 5.10.1 ([#8155](https://github.com/osquery/osquery/pull/8155))
- Fixed small doc error ([#8147](https://github.com/osquery/osquery/pull/8147))
- Update Automatic Table Construction example ([#8094](https://github.com/osquery/osquery/pull/8094))
- Update XCode version mentions to the proper one ([#8128](https://github.com/osquery/osquery/pull/8128))
- Update the description of `serial_number` in `connected_displays` ([#8113](https://github.com/osquery/osquery/pull/8113))
### Build
- Fix openssl build arch for Windows ARM64 ([#8134](https://github.com/osquery/osquery/pull/8134))
- Fix python test http server use `SSLContext.wrap_socket()` instead of deprecated `ssl.wrap_socket()` ([#8169](https://github.com/osquery/osquery/pull/8169))
- GitHub Action to cleanup at stale ec2 runners ([#8156](https://github.com/osquery/osquery/pull/8156))
- Ignore CVE-2023-30571 ([#8065](https://github.com/osquery/osquery/pull/8065))
- Missing pragma/header guard for boottime.h ([#8117](https://github.com/osquery/osquery/pull/8117))
- Permit cross compiling for x86_64 on Apple Silicon ([#8136](https://github.com/osquery/osquery/pull/8136))
- build: update macos hosted github runner to macos-12 monterey ([#8100](https://github.com/osquery/osquery/pull/8100))
- ci: Fix DistributedTests.test_run_queries_with_denylisted_query test ([#8154](https://github.com/osquery/osquery/pull/8154))
- ci: Increase aarch64 available space by splitting the build ([#8131](https://github.com/osquery/osquery/pull/8131))
- ci: Increase disk space on the Linux x86_64 runner ([#8133](https://github.com/osquery/osquery/pull/8133))
- ci: Remove flakyness when removing unused packages on Linux ([#8144](https://github.com/osquery/osquery/pull/8144))
- cve: Fix the expat product name in the libraries manifest ([#8158](https://github.com/osquery/osquery/pull/8158))
- cve: Ignore dbus CVE-2023-34969 ([#8126](https://github.com/osquery/osquery/pull/8126))
- cve: Ignore libcap CVE-2023-2603 ([#8127](https://github.com/osquery/osquery/pull/8127))
- cve: Update expat to version 2.5.0 ([#8159](https://github.com/osquery/osquery/pull/8159))
- cve: Update libmagic to 5.45 ([#8142](https://github.com/osquery/osquery/pull/8142))
- cve: Update lzma to 5.4.4 ([#8135](https://github.com/osquery/osquery/pull/8135))
- cve: Update openssl to 3.1.3 ([#8141](https://github.com/osquery/osquery/pull/8141))
- libs: Fix openssl build on aarch64 ([#8084](https://github.com/osquery/osquery/pull/8084))
- libs: Update openssl to 3.1.1 ([#8081](https://github.com/osquery/osquery/pull/8081))
- libs: Update openssl to 3.1.2 ([#8124](https://github.com/osquery/osquery/pull/8124))
- test: Fix leaks in inotify and rocksdb tests ([#8080](https://github.com/osquery/osquery/pull/8080))
2023-10-22T19:38:25+00:00osquery 5.11.0osquery 5.11.02023-12-27T22:55:41+00:00Draft2023-12-27T22:55:41+00:00