http://open-source-security-software.net/project/zstd/releases.atomRecent releases for zstd2025-04-29T08:45:01.373256+00:00python-feedgenzstd zstd-0.4.2zstd zstd-0.4.22015-12-02T14:33:40+00:00Generic minor improvements for small blocks
Fixed : big-endian compatibility, by @peterh (#85)
2015-12-02T14:33:40+00:00zstd v0.4.3zstd v0.4.32015-12-07T10:13:04+00:00- External dictionary mode (API only)
- zstd-frugal : small-size binary
2015-12-07T10:13:04+00:00zstd v0.4.4zstd v0.4.42015-12-14T12:49:10+00:00Fixed : high compression modes for Windows 32 bits
new : external dictionary API : direct and buffered mode, accessible through command line (`-D`)
new : Visual DLL project, thanks to @KrzysFR
2015-12-14T12:49:10+00:00zstd v0.4.5zstd v0.4.52015-12-18T03:00:18+00:00Added : Command line : `-m` : compress / decompress multiple files. wildcard `*` support.
2015-12-18T03:00:18+00:00zstd v0.4.6zstd v0.4.62016-01-12T23:48:50+00:00fix : fast compression mode on Windows
New : cmake configuration file, thanks to @mailagentrus
Improved : high compression mode on repetitive data
New : block-level API
New : Duplicate context for faster dictionary compression
Changed : ZSTD_decompress() uses heap memory by default (can be changed back to stack with #define)
2016-01-12T23:48:50+00:00zstd v0.4.7zstd v0.4.72016-01-22T12:15:48+00:00Improved : small compression speed improvement in HC mode
Changed : `zstd_decompress.c` starts with ZSTD_LEGACY_SUPPORT set to 0 by default
2016-01-22T12:15:48+00:00zstd v0.5.0zstd v0.5.02016-02-05T15:35:04+00:00New : Dictionary builder tool
Changed : Advanced API for streaming and dictionary compression
Improved : better compression of small data
2016-02-05T15:35:04+00:00zstd v0.5.1zstd v0.5.12016-02-18T11:08:04+00:00- New : Optimal parsing => Very high compression modes, thanks to @inikep
- Changed : Dictionary builder integrated into libzstd and zstd cli
- Changed (!) : zstd cli now uses "multiple input files" as default mode. See `zstd -h`.
- Fix : high compression modes for big-endian platforms (#123)
- New : zstd cli : `-t` | `--test` command
2016-02-18T11:08:04+00:00zstd v0.6.0zstd v0.6.02016-04-12T23:31:58+00:00Stronger high compression modes, thanks to @inikep
Changed : highest compression modes require `--ultra` command to remove memory restrictions
API : `ZSTD_getFrameParams()` provides size of decompressed content
Fixed : zstd cli return error code > 0 and removes dst file artifact when decompression fails, thanks to Chip Turner
Various fixes and small performance improvements
2016-04-12T23:31:58+00:00zstd v0.6.1zstd v0.6.12016-05-13T12:04:56+00:00New : zlib wrapper API, thanks to @inikep
New : Ability to compile compressor / decompressor separately
Changed : new lib directory structure
Fixed : Legacy codec v0.5 compatible with dictionary decompression
Fixed : Decoder corruption error (#173)
Fixed : null-string roundtrip (#176)
New : benchmark mode can select directory as input
Experimental : midipix support, VMS support
2016-05-13T12:04:56+00:00zstd v0.7.1zstd v0.7.12016-06-23T08:16:44+00:00v0.7.1
fixed : `ZBUFF_compressEnd()` called multiple times with too small `dst` buffer, reported by @KrzysFR
fixed : dictBuilder fails if first sample is too small, reported by @velavokr
fixed : corruption issue, reported by cj
modified : frame checksum enabled by default in command line mode (can be disabled with `--no-check`)
fixed : cli breaks during destination file overwrite confirmation
v0.7.0
**Candidate compression format**
New : Support for directory compression, using `-r`, thanks to @inikep
New : Command `--rm`, to remove source file after successful de/compression
New : Visual build scripts, by @KrzysFR
New : Support for Sparse File-systems (do not use space for zero-filled sectors)
New : Frame checksum support
New : Support pass-through mode (when using `-df`)
API : more efficient Dictionary API : `ZSTD_compress_usingCDict()`, `ZSTD_decompress_usingDDict()`
API : create dictionary files from custom content, by @ot
API : support for custom malloc/free functions
New : controllable Dictionary ID
New : Support for skippable frames
Changed : removed `zstd_static.h`, now replaced by a `#define ZSTD_STATIC_LINKING_ONLY` before `#include zstd.h`. Same logic for all others `*_static.h`.
2016-06-23T08:16:44+00:00zstd v0.7.2zstd v0.7.22016-07-03T19:10:49+00:00fixed : ZSTD_decompressBlock() using multiple consecutive blocks. Reported by @GregSlazinski
fixed : potential segfault on very large files (many gigabytes). Reported by @chipturner
fixed : CLI displays system error message when destination file cannot be created (#231). Reported by @chipturner
fixed : leak in some fail scenario in dictionary builder, reported by @nemequ
2016-07-03T19:10:49+00:00zstd v0.7.3zstd v0.7.32016-07-08T19:33:59+00:00New : compression format specification `zstd_compression_format.md`
New : `--` separator, stating that all following arguments are file names. Suggested by @chipturner
New : `ZSTD_getDecompressedSize()`
New : OpenBSD target, by @juanfra684
New : `examples` directory
fixed : dictBuilder using HC levels, reported by Bartosz Taudul
fixed : legacy support from `ZSTD_decompress_usingDDict()`, reported by Felix Handte
fixed : multi-blocks decoding with intermediate uncompressed blocks, reported by @GregSlazinski
modified : removed "mem.h" and "error_public.h" dependencies from "zstd.h" (experimental section)
modified : legacy functions no longer need magic number
2016-07-08T19:33:59+00:00zstd v0.7.4zstd v0.7.42016-07-16T18:19:10+00:00Modified : default compression level is now **3** for CLI
Added : homebrew for Mac, by @cadedaniel
Fixed : segfault when using small dictionaries, reported by Felix Handte
Added : more examples
Updated : specification, to v0.1.1
2016-07-16T18:19:10+00:00zstd v0.7.5zstd v0.7.52016-08-01T12:28:38+00:00Same as v0.7.4
with added ability to decode v0.8x streams (forward compatibility)
2016-08-01T12:28:38+00:00zstd v0.6.2zstd v0.6.22016-08-02T12:04:14+00:00Same as v0.6.1
with added ability to decode v0.7x and v0.8x streams (forward compatibility)
2016-08-02T12:04:14+00:00zstd v0.8.0zstd v0.8.02016-08-02T13:57:17+00:00**Final compression format**
Improved : better speed on clang and gcc -O2, thanks to @ebiggers
New : Build on FreeBSD and DragonFly, thanks to @jrmarino
Changed : modified API : ZSTD_compressEnd()
Fixed : legacy mode with ZSTD_HEAPMODE=0, by @gymdis
Fixed : premature end of frame when zero-sized raw block, reported by @ebiggers
Fixed : large dictionaries (> 384 KB), reported by Ilona Papava
Fixed : checksum correctly checked in single-pass mode
Fixed : combined --test amd --rm, reported by @amnilsson
Modified : minor compression level adaptations
Updated : compression format specification to v0.2.0
changed : zstd.h moved to /lib directory
2016-08-02T13:57:17+00:00zstd v0.8.1zstd v0.8.12016-08-18T15:08:01+00:00New streaming API
Changed : --ultra now enables levels beyond 19
Changed : -i# now selects benchmark time in second
Fixed : ZSTD_compress\* can now compress > 4 GB in a single pass, reported by Nick Terrell
Fixed : speed regression on specific patterns (#272)
Fixed : support for Z_SYNC_FLUSH, by @dak-evanti-ru (#291)
Fixed : ICC compilation, by @inikep
2016-08-18T15:08:01+00:00zstd v1.0.0zstd v1.0.02016-08-31T16:10:23+00:00Change Licensing, all project is now BSD, copyright Facebook
Added Patent Grant
Small decompression speed improvement
API : Streaming API supports legacy format
API : New : ZDICT_getDictID(), ZSTD_sizeof_{CCtx, DCtx, CStream, DStream}(), ZSTD_setDStreamParamter()
CLI supports legacy formats v0.4+
Fixed : compression fails on certain huge files, reported by Jesse McGrew
Enhanced documentation, by @inikep
2016-08-31T16:10:23+00:00zstd v1.1.0zstd v1.1.02016-09-28T03:18:33+00:00New : **pzstd** , parallel version of zstd, by @terrelln
added : NetBSD install target (#338)
Improved : speed for batches of small files
Improved : speed of zlib wrapper, by @inikep
Changed : libzstd on Windows supports legacy formats, by @KrzysFR
Fixed : CLI -d output to stdout by default when input is stdin (#322)
Fixed : CLI correctly detects console on Mac OS-X
Fixed : CLI supports recursive mode -r on Mac OS-X
Fixed : Legacy decoders use unified error codes, reported by benrg (#341), fixed by @inikep
Fixed : compatibility with OpenBSD, reported by@juanfra684 (#319)
Fixed : compatibility with Hurd, by @inikep (#365)
Fixed : zstd-pgo, reported by @octoploid (#329)
2016-09-28T03:18:33+00:00zstd v1.1.1zstd v1.1.12016-11-02T04:06:40+00:00New : cli commands `-M#`, `--memory=`, `--memlimit=`, `--memlimit-decompress=` to limit allowed memory consumption during decompression
New : doc/zstd_manual.html, by @inikep
Improved : slightly better compression ratio at `--ultra` levels (>= 20)
Improved : better memory usage when using streaming compression API, thanks to @Rogier-5 report
Added : API : `ZSTD_initCStream_usingCDict()`, `ZSTD_initDStream_usingDDict()` (experimental section)
Added : `examples/multiple_streaming_compression.c`
Changed : `zstd_errors.h` is now installed within `/include` (and replaces `errors_public.h`)
Updated man page
Fixed : several sanitizer warnings, by @terrelln
Fixed : `zstd-small`, `zstd-compress` and `zstd-decompress` compilation targets
2016-11-02T04:06:40+00:00zstd v1.1.2zstd v1.1.22016-12-15T08:00:35+00:00**new** : programs/**gzstd** , combined `*.gz` and `*.zst` decoder, by @inikep
**new** : zstdless, less on compressed `*.zst` files
**new** : zstdgrep, grep on compressed `*.zst` files
fixed : zstdcat
cli : new : preserve file attributes
cli : fixed : status displays total amount decoded, even for file consisting of multiple frames (like pzstd)
lib : improved : faster decompression speed at ultra compression settings and 32-bits mode
lib : changed : only public ZSTD_ symbols are now exposed in dynamic library
lib : changed : reduced usage of stack memory
lib : fixed : several corner case bugs, by @terrelln
API : streaming : decompression : changed : automatic implicit reset when chain-decoding new frames without init
API : experimental : added : dictID retrieval functions, and ZSTD_initCStream_srcSize()
API : zbuff : changed : prototypes now generate deprecation warnings
zlib_wrapper : added support for gz\* functions, by @inikep
install : better compatibility with FreeBSD, by @DimitryAndric
source tree : changed : zbuff source files moved to lib/deprecated
2016-12-15T08:00:35+00:00zstd v1.1.3zstd v1.1.32017-02-06T17:19:09+00:00cli : zstd can decompress .gz files (can be disabled with `make zstd-nogz` or `make HAVE_ZLIB=0`)
cli : new : experimental target `make zstdmt`, with multi-threading support
cli : new : improved dictionary builder "cover" (experimental), by @terrelln, based on previous work by @ot
cli : new : advanced commands for detailed parameters, by @inikep
cli : fix zstdless on Mac OS-X, by @apjanke
cli : fix #232 "compress non-files"
API : new : `lib/compress/ZSTDMT_compress.h` multithreading API (experimental)
API : new : `ZSTD_create?Dict_byReference()`, requested by Bartosz Taudul
API : new : `ZDICT_finalizeDictionary()`
API : fix : `ZSTD_initCStream_usingCDict()` properly writes dictID into frame header, by @indygreg (#511)
API : fix : all symbols properly exposed in libzstd, by @terrelln
build : support for Solaris target, by @inikep
doc : clarified specification, by @iburinoc
Sample set for reference dictionary compression benchmark
=============================================
```
# Download and expand sample set
wget https://github.com/facebook/zstd/releases/download/v1.1.3/github_users_sample_set.tar.zst
zstd -d github_users_sample_set.tar.zst
tar xf github_users_sample_set.tar
```
```
# benchmark sample set with and without dictionary compression
zstd -b1 -r github
zstd --train -r github
zstd -b1 -r github -D dictionary
```
```
# rebuild sample set archive
tar cf github_users_sample_set.tar github
zstd -f --ultra -22 github_users_sample_set.tar
```
2017-02-06T17:19:09+00:00zstd v1.1.4zstd v1.1.42017-03-17T21:33:25+00:00cli : new : can compress in `*.gz` format, using `--format=gzip` command, by @inikep
cli : new : advanced benchmark command `--priority=rt`
cli : fix : write on sparse-enabled file systems in 32-bits mode, by @ds77
cli : fix : `--rm` remains silent when input is stdin
cli : experimental `xzstd` target, with support for xz/lzma decoding, by @inikep
speed : improved decompression speed in streaming mode for single pass scenarios (+5%)
memory : DDict (decompression dictionary) memory usage down from 150 KB to 20 KB
arch : 32-bits variant able to generate and decode very long matches (>32 MB), by @iburinoc
API : new : `ZSTD_findFrameCompressedSize()`, `ZSTD_getFrameContentSize()`, `ZSTD_findDecompressedSize()`
API : changed : dropped support of legacy versions <= v0.3 (can be selected by modifying `ZSTD_LEGACY_SUPPORT` value)
build: new: meson build system in contrib/meson, by @dimkr
build: improved cmake script, by @Majlen
build: added `-Wformat-security` flag, as recommended by @pixelb
doc : new : `doc/educational_decoder`, by @iburinoc
__Warning__ : the experimental target `zstdmt` contained in this release has an issue when using multiple threads on large enough files, which makes it generate buggy header. While fixing the header after the fact is possible, it's much better to avoid the issue. This can be done by using `zstdmt` in pipe mode :
`cat file | zstdmt -T2 -o file.zst`
This issue is fixed in current `dev` branch, so alternatively, create `zstdmt` from `dev` branch.
_Note_ : pre-compiled Windows binaries attached below contain the fix for `zstdmt`2017-03-17T21:33:25+00:00zstd v1.2.0zstd v1.2.02017-05-04T18:23:23+00:00Major features :
- Multithreading is enabled by default in the cli. Use `-T#` to select nb of thread. To disable multithreading, build target `zstd-nomt` or compile with `HAVE_THREAD=0`.
- New dictionary builder named "cover" with improved quality (produces better compression ratio), by @terrelln. Legacy dictionary builder remains available, using `--train-legacy` command.
Other changes :
cli : new : command `-T0` means "detect and use nb of cores", by @iburinoc
cli : new : `zstdmt` symlink hardwired to `zstd -T0`
cli : new : command `--threads=#` (#671)
cli : new : commands `--train-cover` and `--train-legacy`, to select dictionary algorithm and parameters
cli : experimental targets `zstd4` and `xzstd4`, supporting lz4 format, by @iburinoc
cli : fix : does not output compressed data on console
cli : fix : ignore symbolic links unless `--force` specified,
API : breaking change : `ZSTD_createCDict_advanced()` uses `compressionParameters` as argument
API : added : prototypes `ZSTD_*_usingCDict_advanced()`, for direct control over `frameParameters`.
API : improved: `ZSTDMT_compressCCtx()` reduced memory usage
API : fix : `ZSTDMT_compressCCtx()` now provides `srcSize` in header (#634)
API : fix : src size stored in frame header is controlled at end of frame
API : fix : enforced consistent rules for `pledgedSrcSize==0` (#641)
API : fix : error code `GENERIC` replaced by `dstSizeTooSmall` when appropriate
build: improved cmake script, by @Majlen
build: enabled Multi-threading support for *BSD, by @bapt
tools: updated `paramgrill`. Command `-O#` provides best parameters for sample and speed target.
new : `contrib/linux-kernel` version, by @terrelln 2017-05-04T18:23:23+00:00zstd v1.3.0zstd v1.3.02017-07-05T18:05:54+00:00cli : new : `--list` command, by @paulcruz74
cli : changed : xz/lzma support enabled by default
cli : changed : `-t *` continue processing list after a decompression error
API : added : `ZSTD_versionString()`
API : promoted to stable status : `ZSTD_getFrameContentSize()`, by @iburinoc
API exp : **new advanced API** : `ZSTD_compress_generic()`, `ZSTD_CCtx_setParameter()`
API exp : new : API for static or external allocation : `ZSTD_initStatic?Ctx()`
API exp : added : `ZSTD_decompressBegin_usingDDict()`, requested by @Crazee (#700)
API exp : clarified memory estimation / measurement functions.
API exp : changed : strongest strategy renamed `ZSTD_btultra`, fastest strategy `ZSTD_fast` set to 1
Improved : reduced stack memory usage, by @terrelln and @stellamplau
tools : decodecorpus can generate random dictionary-compressed samples, by @paulcruz74
new : contrib/seekable_format, demo and API, by @iburinoc
changed : contrib/linux-kernel, updated version and license, by @terrelln 2017-07-05T18:05:54+00:00zstd v1.3.1zstd v1.3.12017-08-20T19:37:00+00:00- **New license** : BSD + GPLv2
- perf: substantially decreased memory usage in Multi-threading mode, thanks to reports by Tino Reichardt (@mcmilk)
- perf: Multi-threading supports up to 256 threads. Cap at 256 when more are requested (#760)
- cli : improved and fixed `--list` command, by @ib (#772)
- cli : command `-vV` lists supported formats, by @ib (#771)
- build : fixed binary variants, reported by @svenha (#788)
- build : fix Visual compilation for non x86/x64 targets, reported by @GregSlazinski (#718)
- API exp : breaking change : `ZSTD_getframeHeader()` provides more information
- API exp : breaking change : pinned down values of error codes
- doc : fixed huffman example, by Ulrich Kunitz (@ulikunitz)
- new : `contrib/adaptive-compression`, I/O driven compression level, by Paul Cruz (@paulcruz74)
- new : `contrib/long_distance_matching`, statistics tool by Stella Lau (@stellamplau)
- updated : `contrib/linux-kernel`, by Nick Terrell (@terrelln)2017-08-20T19:37:00+00:00zstd fuzz-corporazstd fuzz-corpora2017-09-22T23:16:48+00:00Zstandard Fuzz Corpora2017-09-22T23:16:48+00:00zstd v1.3.2zstd v1.3.22017-10-09T23:31:00+00:00# Zstandard Long Range Match Finder
Zstandard has a new long range match finder written by our intern Stella Lau (@stellamplau), which specializes on finding long matches in the distant past. It integrates seamlessly with the regular compressor, and the output can be decompressed just like any other Zstandard compressed data.
The long range match finder adds minimal overhead to the compressor, works with any compression level, and maintains Zstandard's blazingly fast decompression speed. However, since the window size is larger, it requires more memory for compression and decompression.
To go along with the long range match finder, we've increased the maximum window size to 2 GB. The decompressor only accepts window sizes up to 128 MB by default, but `zstd -d --memory=2GB` will decompress window sizes up to 2 GB.
## Example usage
```
# 128 MB window size
zstd -1 --long file
zstd -d file.zst
# 2 GB window size (window log = 31)
zstd -6 --long=31 file
zstd -d --long=31 file.zst
# OR
zstd -d --memory=2GB file.zst
```
```c
ZSTD_CCtx *cctx = ZSTD_createCCtx();
ZSTD_CCtx_setParameter(cctx, ZSTD_p_compressionLevel, 19);
ZSTD_CCtx_setParameter(cctx, ZSTD_p_enableLongDistanceMatching, 1); // Sets windowLog=27
ZSTD_CCtx_setParameter(cctx, ZSTD_p_windowLog, 30); // Optionally increase the window log
ZSTD_compress_generic(cctx, &out, &in, ZSTD_e_end);
ZSTD_DCtx *dctx = ZSTD_createDCtx();
ZSTD_DCtx_setMaxWindowSize(dctx, 1 << 30);
ZSTD_decompress_generic(dctx, &out, &in);
```
## Benchmarks
We compared the zstd long range matcher to zstd and [lrzip](https://github.com/ckolivas/lrzip). The benchmarks were run on an AMD Ryzen 1800X (8 cores with 16 threads at 3.6 GHz).
### Compressors
* zstd — The regular Zstandard compressor.
* zstd 128 MB — The Zstandard compressor with a 128 MB window size.
* zstd 2 GB — The Zstandard compressor with a 2 GB window size.
* lrzip xz — The lrzip compressor with default options, which uses the xz backend at level 7 with 16 threads.
* lrzip xz single — The lrzip compressor with a single-threaded xz backend at level 7.
* lrzip zstd — The lrzip compressor without a backend, then its output is compressed by zstd (not multithreaded).
### Files
* Linux 4.7 - 4.12 — This file consists of the uncompressed tarballs of the six Linux kernel release from 4.7 to 4.12 concatenated together in order. This file is extremely compressible if the compressor can match against the previous versions well.
* Linux git — This file is a tarball of the linux repo, created by `git clone https://github.com/torvalds/linux && tar -cf linux-git.tar linux/`. This file gets a small benefit from long range matching. This file shows how the long range matcher performs when there isn't too many matches to find.
### Results
Both zstd and zstd 128 MB don't have large enough of a window size to compress Linux 4.7 - 4.12 well. zstd 2 GB compresses the fastest, and slightly better than lrzip-zstd. lrzip-xz compresses the best, and at a reasonable speed with multithreading enabled. The place where zstd shines is decompression ease and speed. Since it is just regular Zstandard compressed data, it is decompressed by the highly optimized decompressor.
The Linux git file shows that the long range matcher maintains good compression and decompression speed, even when there are far less long range matches. The decompression speed takes a small hit because it has to look further back to reconstruct the matches.
Compression Ratio vs Speed | Decompression Speed
---------------------------|--------------------
 | 
 | 
## Implementation details
The long distance match finder was inspired by great work from Con Kolivas' [lrzip](http://ck.kolivas.org/apps/lrzip/README.md), which in turn was inspired by Andrew Tridgell's [rzip](https://rzip.samba.org/). Also, let's mention Bulat Ziganshin's [srep](https://encode.ru/threads/43-FreeArc?highlight=srep), which we have not been able to test unfortunately (site down), but the discussions on [encode.ru](https://encode.ru/forums/2-Data-Compression) proved great sources of inspiration.
Therefore, many similar mechanisms are adopted, such as using a [rolling hash](https://en.wikipedia.org/wiki/Rolling_hash), and filling a [hash table](https://en.wikipedia.org/wiki/Hash_table) divided into buckets of entries.
That being said, we also made different choices, with the goal to favor speed, as can be observed in benchmark. The rolling hash formula is selected for computing efficiency. There is a restrictive insertion policy, which only inserts candidates that respect a mask condition. The insertion policy allows us to skip the hash table in the common case that a match isn't present. Confirmation bits are saved, to only check for matches when there is a strong presumption of success. These and a few more details add up to make zstd's long range matcher a speed-oriented implementation.
The biggest difference though is that the long range matcher is blended into the regular compressor, producing a single valid zstd frame, undistinguishable from normal operation (except obviously for the larger window size). This makes decompression a single pass process, preserving its speed property.
More details are available directly in source code, at [lib/compress/zstd_ldm.c](https://github.com/facebook/zstd/blob/master/lib/compress/zstd_ldm.c).
## Future work
This is a first implementation, and it still has a few limitations, that we plan to lift in the future.
The long range matcher doesn't interact well with multithreading. Due to the way zstd multithreading is currently implemented, memory usage will scale with the window size times the number of threads, which is a problem for large window sizes. We plan on supporting multithreaded long range matching with reasonable memory usage in a future version.
Secondly, Zstandard is currently limited to a 2 GB window size because of indexer's design. While this is a significant update compared to previous 128 MB limit, we believe this limitation can be lifted altogether, with some structural changes in the indexer. However, it also means that window size would become really big, with knock-off consequences on memory usage. So, to reduce this load, we will have to consider memory map as a complementary way to reference past content in the uncompressed file.
# Detailed list of changes
- new : __long range mode__, using `--long` command, by Stella Lau (@stellamplau)
- new : ability to generate and decode magicless frames (#591)
- changed : maximum nb of threads reduced to 200, to avoid address space exhaustion in 32-bits mode
- fix : multi-threading compression works with custom allocators, by @terrelln
- fix : a rare compression bug when compression generates very large distances and bunch of other conditions (only possible at `--ultra -22`)
- fix : 32-bits build can now decode large offsets (levels 21+)
- cli : added LZ4 frame support by default, by Felix Handte (@felixhandte)
- cli : improved `--list` output
- cli : new : can split input file for dictionary training, using command `-B#`
- cli : new : clean operation artefact on Ctrl-C interruption (#854)
- cli : fix : do not change /dev/null permissions when using command `-t` with root access, reported by @mike155 (#851)
- cli : fix : write file size in header in multiple-files mode
- api : added macro `ZSTD_COMPRESSBOUND()` for static allocation
- api : experimental : new advanced decompression API
- api : fix : `sizeof_CCtx()` used to over-estimate
- build: fix : compilation works with `-mbmi` (#868)
- build: fix : no-multithread variant compiles without `pool.c` dependency, reported by Mitchell Blank Jr (@mitchblank) (#819)
- build: better compatibility with reproducible builds, by Bernhard M. Wiedemann (@bmwiedemann) (#818)
- example : added `streaming_memory_usage`
- license : changed /examples license to BSD + GPLv2
- license : fix a few header files to reflect new license (#825)
## Warning
bug #944 : `v1.3.2` is known to produce corrupted data in the following scenario, requiring all these conditions simultaneously :
- compression using multi-threading
- with a dictionary
- on "large enough" files (several MB, exact threshold depends on compression level)
Note that dictionary is meant to help compression of small files (a few KB), while multi-threading is only useful for large files, so it's pretty rare to need both at the same time. Nonetheless, if your application happens to trigger this situation, it's recommended to skip `v1.3.2` for a newer version. At the time of this warning, the `dev` branch is known to work properly for the same scenario.2017-10-09T23:31:00+00:00zstd v1.3.3zstd v1.3.32017-12-21T09:25:55+00:00This is bugfix release, mostly focused on cleaning several detrimental corner cases scenarios.
It is nonetheless a recommended upgrade.
### Changes Summary
- perf: improved `zstd_opt` strategy (levels 16-19)
- fix : bug #944 : multithreading with shared ditionary and large data, reported by @gsliepen
- cli : change : `-o` can be combined with multiple inputs, by @terrelln
- cli : fix : content size written in header by default
- cli : fix : improved LZ4 format support, by @felixhandte
- cli : new : hidden command `-b -S`, to benchmark multiple files and generate one result per file
- api : change : when setting `pledgedSrcSize`, use `ZSTD_CONTENTSIZE_UNKNOWN` macro value to mean "unknown"
- api : fix : support large skippable frames, by @terrelln
- api : fix : re-using context could result in suboptimal block size in some corner case scenarios
- api : fix : streaming interface was adding a useless 3-bytes null block to small frames
- build: fix : compilation under rhel6 and centos6, reported by @pixelb
- build: added `check` target
- build: improved meson support, by @shawnl 2017-12-21T09:25:55+00:00zstd v1.3.4zstd v1.3.42018-03-26T22:24:27+00:00The v1.3.4 release of Zstandard is focused on performance, and will offers nice speed boost in most scenarios.
### Asynchronous compression by default for `zstd` CLI
`zstd` cli will now performs compression in parallel with I/O operations by default. This requires multi-threading capability (which is also enabled by default).
It doesn't sound like much, but effectively improves throughput by 20-30%, depending on compression level and underlying I/O performance.
For example, on a Mac OS-X laptop with an Intel Core i7-5557U CPU @ 3.10GHz, running `time zstd ` [`enwik9`](http://mattmahoney.net/dc/textdata.html) at default compression level (2) on a SSD gives the following :
| Version | real time |
| --- | --- |
| 1.3.3 | 9.2s |
| 1.3.4 --single-thread | 8.8s |
| 1.3.4 (asynchronous) | 7.5s |
This is a nice boost to all scripts using `zstd` cli, typically in network or storage tasks. The effect is even more pronounced at faster compression setting, since the CLI overlaps a proportionally higher share of compression with I/O.
Previous default behavior (blocking single thread) is still available, accessible through `--single-thread` long command. It's also the only mode available when no multi-threading capability is detected.
### General speed improvements
Some core routines have been refined to provide more speed on newer cpus, making better use of their out-of-order execution units. This is more sensible on the decompression side, and even more so with `gcc` compiler.
Example on the same platform, running in-memory benchmark `zstd -b1 silesia.tar` :
| Version | C.Speed | D.Speed |
| --- | ---- | --- |
| 1.3.3 llvm9 | 290 MB/s | 660 MB/s |
| 1.3.4 llvm9 | 304 MB/s | 700 MB/s (+6%) |
| 1.3.3 gcc7 | 280 MB/s | 710 MB/s
| 1.3.4 gcc7 | 300 MB/s | 890 MB/s (+25%)|
### Faster compression levels
So far, compression level 1 has been the fastest one available. Starting with v1.3.4, there will be additional choices. Faster compression levels can be invoked using negative values.
On the command line, the equivalent one can be triggered using `--fast[=#]` command.
Negative compression levels sample data more sparsely, and disable Huffman compression of literals, translating into faster decoding speed.
It's possible to create one's own custom fast compression level
by using strategy `ZSTD_fast`, increasing `ZSTD_p_targetLength` to desired value,
and turning on or off literals compression, using `ZSTD_p_compressLiterals`.
Performance is generally on par or better than other high speed algorithms. On below benchmark (compressing `silesia.tar` on an Intel Core i7-6700K CPU @ 4.00GHz) , it ends up being faster and stronger on all metrics compared with `quicklz` and `snappy` at `--fast=2`. It also compares favorably to `lzo` with `--fast=3`. `lz4` still offers a better speed / compression combo, with `zstd --fast=4` approaching close.
name | ratio | compression | decompression
-- | -- | -- | --
zstd 1.3.4 --fast=5 | 1.996 | 770 MB/s | 2060 MB/s
lz4 1.8.1 | 2.101 | 750 MB/s | 3700 MB/s
zstd 1.3.4 --fast=4 | 2.068 | 720 MB/s | 2000 MB/s
zstd 1.3.4 --fast=3 | 2.153 | 675 MB/s | 1930 MB/s
lzo1x 2.09 -1 | 2.108 | 640 MB/s | 810 MB/s
zstd 1.3.4 --fast=2 | 2.265 | 610 MB/s | 1830 MB/s
quicklz 1.5.0 -1 | 2.238 | 540 MB/s | 720 MB/s
snappy 1.1.4 | 2.091 | 530 MB/s | 1820 MB/s
zstd 1.3.4 --fast=1 | 2.431 | 530 MB/s | 1770 MB/s
zstd 1.3.4 -1 | 2.877 | 470 MB/s | 1380 MB/s
brotli 1.0.2 -0 | 2.701 | 410 MB/s | 430 MB/s
lzf 3.6 -1 | 2.077 | 400 MB/s | 860 MB/s
zlib 1.2.11 -1 | 2.743 | 110 MB/s | 400 MB/s
Applications which were considering Zstandard but were worried of being CPU-bounded are now able to shift the load from CPU to bandwidth on a larger scale, and may even vary temporarily their choice depending on local conditions (to deal with some sudden workload surge for example).
### Long Range Mode with Multi-threading
zstd-1.3.2 introduced the [long range mode](https://github.com/facebook/zstd/releases/tag/v1.3.2), capable to deduplicate long distance redundancies in a large data stream, a situation typical in backup scenarios for example. But its usage in association with multi-threading was discouraged, due to inefficient use of memory.
zstd-1.3.4 solves this issue, by making long range match finder run in serial mode, like a pre-processor, before passing its result to backend compressors (regular zstd). Memory usage is now bounded to the maximum of the long range window size, and the memory that zstdmt would require without long range matching. As the long range mode runs at about 200 MB/s, depending on the number of cores available, it's possible to tune compression level to match the LRM speed, which becomes the upper limit.
```sh
zstd -T0 -5 --long file # autodetect threads, level 5, 128 MB window
zstd -T16 -10 --long=31 file # 16 threads, level 10, 2 GB window
```
As illustration, benchmarks of the two files "Linux 4.7 - 4.12" and "Linux git" from the [1.3.2 release](https://github.com/facebook/zstd/releases/tag/v1.3.2) are shown below. All compressors are run with 16 threads, except "zstd single 2 GB". `zstd` compressors are run with either a 128 MB or 2 GB window size, and `lrzip` compressor is run with `lzo`, `gzip`, and `xz` backends. The benchmarks were run on a 16 core Sandy Bridge @ 2.2 GHz.


The association of Long Range Mode with multi-threading offers now some very compelling results for large stream scenarios.
### Miscellaneous
This release also brings its usual list of small improvements and bug fixes, as detailed below :
- perf: faster speed (especially decoding speed) on recent cpus (haswell+)
- perf: much better performance associating `--long` with multi-threading, by @terrelln
- perf: better compression at levels 13-15
- cli : asynchronous compression by default, for faster experience (use `--single-thread` for former behavior)
- cli : smoother status report in multi-threading mode
- cli : added command `--fast=#`, for faster compression modes
- cli : fix crash when not overwriting existing files, by Pádraig Brady (@pixelb)
- api : `nbThreads` becomes `nbWorkers` : 1 triggers asynchronous mode
- api : compression levels can be negative, for even more speed
- api : `ZSTD_getFrameProgression()` : get precise progress status of ZSTDMT anytime
- api : ZSTDMT can accept new compression parameters during compression
- api : implemented all advanced dictionary decompression prototypes
- build: improved meson recipe, by Shawn Landden (@shawnl)
- build: VS2017 scripts, by @HaydnTrigg
- misc: all `/contrib` projects fixed
- misc: added `/contrib/docker` script by @gyscos
2018-03-26T22:24:27+00:00zstd v1.3.5zstd v1.3.52018-06-28T16:57:59+00:00Zstandard v1.3.5 is a maintenance release focused on dictionary compression performance.
Compression is generally associated with the act of willingly requesting the compression of some large source. However, within datacenters, compression brings its best benefits when completed transparently. In such scenario, it's actually very common to compress a large number of very small blobs (individual messages in a stream or log, or records in a cache or datastore, etc.). Dictionary compression is a great tool for these use cases.
This release makes dictionary compression significantly faster for these situations, when compressing small to very small data (inputs up to ~16 KB).

The above image plots the compression speeds at different input sizes for `zstd` v1.3.4 (red) and v1.3.5 (green), at levels 1, 3, 9, and 18.
The benchmark data was gathered on an `Intel Xeon CPU E5-2680 v4 @ 2.40GHz`. The benchmark was compiled with `clang-7.0`, with the flags `-O3 -march=native -mtune=native -DNDEBUG`. The file used in the results shown here is the `osdb` file from the Silesia corpus, cut into small blocks. It was selected because it performed roughly in the middle of the pack among the Silesia files.
The new version saves substantial initialization time, which is increasingly important as the average size to compress becomes smaller. The impact is even more perceptible at higher levels, where initialization costs are higher. For larger inputs, performance remain similar.
Users can expect to measure substantial speed improvements for inputs smaller than 8 KB, and up to 32 KB depending on the context. The expected speed-up ranges from none (large, incompressible blobs) to many times faster (small, highly compressible inputs). Real world examples up to 15x have been observed.
#### Other noticeable improvements
The compression levels have been slightly adjusted, taking into consideration the higher top speed of level 1 since v1.3.4, and making level 19 a substantially stronger compression level while preserving the `8 MB` window size limit, hence keeping an acceptable memory budget for decompression.
It's also possible to select the content of `libzstd` by [modifying macro values](https://github.com/facebook/zstd/tree/v1.3.5/lib#modular-build) at compilation time. By default, `libzstd` contains everything, but its size can be made substantially smaller by removing support for the dictionary builder, or legacy formats, or deprecated functions. It's even possible to build a compression-only or a decompression-only library.
### Detailed changes list
- perf: much faster dictionary compression, by @felixhandte
- perf: small quality improvement for dictionary generation, by @terrelln
- perf: improved high compression levels (notably level 19)
- mem : automatic memory release for long duration contexts
- cli : fix : `overlapLog` can be manually set
- cli : fix : decoding invalid lz4 frames
- api : fix : performance degradation for dictionary compression when using advanced API, by @terrelln
- api : change : clarify `ZSTD_CCtx_reset()` vs` ZSTD_CCtx_resetParameters()`, by @terrelln
- build: select custom `libzstd` scope through control macros, by @GeorgeLu97
- build: OpenBSD support, by @bket
- build: `make` and `make all` are compatible with `-j`
- doc : clarify `zstd_compression_format.md`, updated for IETF RFC process
- misc: `pzstd` compatible with reproducible compilation, by @lamby2018-06-28T16:57:59+00:00zstd v1.3.6zstd v1.3.62018-10-05T16:48:23+00:00Zstandard v1.3.6 release is focused on intensive dictionary compression for database scenarios.
This is a new environment we are experimenting. The success of dictionary compression on small data, of which databases tend to store plentiful, led to increased adoption, and we now see scenarios where literally thousands of dictionaries are being used simultaneously, with permanent generation or update of new dictionaries.
To face these new conditions, v1.3.6 brings a few improvements to the table :
- A brand new, faster dictionary builder, by @jenniferliu, under guidance from @terrelln. The new builder, named _fastcover_, is about 10x faster than our previous default generator, cover, while suffering only negligible accuracy losses (<1%). It's effectively an approximative version of cover, which throws away accuracy for the benefit of speed and memory. The new dictionary builder is so effective that it has become our new default dictionary builder (`--train`). Slower but higher quality generator remains accessible using `--train-cover` command.
Here is an example, using the "github user records" public dataset (about 10K records of about 1K each) :
| builder algorithm | generation time | compression ratio |
| --- | --- | --- |
| fast cover (v1.3.6 `--train`) | 0.9 s | x10.29 |
| cover (v1.3.5 `--train`) | 10.1 s | x10.31
| High accuracy fast cover (`--train-fastcover`) | 6.6 s | x10.65
| High accuracy cover (`--train-cover`) | 50.5 s | x10.66
- Faster dictionary decompression under memory pressure, when using thousands of dictionaries simultaneously. The new decoder is able to detect cold vs hot dictionary scenarios, and adds clever prefetching decisions to minimize memory latency. It typically improves decoding speed by ~+30% (vs v1.3.5).
- Faster dictionary compression under memory pressure, when using a lot of contexts simultaneously. The new design, by @felixhandte, reduces considerably memory usage when compressing small data with dictionaries, which is the main scenario found in databases. The sharp memory usage reduction makes it easier for CPU caches to manages multiple contexts in parallel. Speed gains scale with number of active contexts, as shown in the graph below :

Note that, in real-life environment, benefits are present even faster, since cpu caches tend to be used by multiple other process / threads at the same time, instead of being monopolized by a single synthetic benchmark.
#### Other noticeable improvements
A new command `--adapt`, makes it possible to pipe gigantic amount of data between servers (typically for backup scenarios), and let the compressor automatically adjust compression level based on perceived network conditions. When the network becomes slower, `zstd` will use available time to compress more, and accelerate again when bandwidth permit. It reduces the need to "pre-calibrate" speed and compression level, and is a good simplification for system administrators. It also results in gains for both dimensions (better compression ratio _and_ better speed) compared to the more traditional "fixed" compression level strategy.
This is still early days for this feature, and we are eager to get feedback on its usages. We know it works better in fast bandwidth environments for example, as adaptation itself becomes slow when bandwidth is slow. This is something that will need to be improved. Nonetheless, in its current incarnation, `--adapt` already proves useful for several datacenter scenarios, which is why we are releasing it.
Finally, advanced users will be please by the expansion of an existing tool, `tests/paramgrill`, which has been refined by @georgelu. This tool explores the space of [advanced compression parameters](https://github.com/facebook/zstd/blob/v1.3.6/programs/zstd.1.md#advanced-compression-options), to find the best possible set of compression parameters for a given scenario. It takes as input a set of samples, and a set of constraints, and works its way towards better and better compression parameters respecting the constraints.
Example :
```
./paramgrill --optimize=cSpeed=50M dirToSamples/* # requires minimum compression speed of 50 MB/s
optimizing for dirToSamples/* - limit compression speed 50 MB/s
(...)
/* Level 5 */ { 20, 18, 18, 2, 5, 2,ZSTD_greedy , 0 }, /* R:3.147 at 75.7 MB/s - 567.5 MB/s */ # best level satisfying constraint
--zstd=windowLog=20,chainLog=18,hashLog=18,searchLog=2,searchLength=5,targetLength=2,strategy=3,forceAttachDict=0
(...)
/* Custom Level */ { 21, 16, 18, 2, 6, 0,ZSTD_lazy2 , 0 }, /* R:3.240 at 53.1 MB/s - 661.1 MB/s */ # best custom parameters found
--zstd=windowLog=21,chainLog=16,hashLog=18,searchLog=2,searchLength=6,targetLength=0,strategy=5,forceAttachDict=0 # associated command arguments, can be copy/pasted for `zstd`
```
Finally, documentation has been updated, to reflect wording adopted by [IETF RFC 8478 (_Zstandard Compression and the application/zstd Media Type_)](https://tools.ietf.org/html/rfc8478).
### Detailed changes list
- perf: much faster dictionary builder, by @jenniferliu
- perf: faster dictionary compression on small data when using multiple contexts, by @felixhandte
- perf: faster dictionary decompression when using a very large number of dictionaries simultaneously
- cli : fix : does no longer overwrite destination when source does not exist (#1082)
- cli : new command `--adapt`, for automatic compression level adaptation
- api : fix : block api can be streamed with > 4 GB, reported by @catid
- api : reduced `ZSTD_DDict` size by 2 KB
- api : minimum negative compression level is defined, and can be queried using `ZSTD_minCLevel()` (#1312).
- build: support Haiku target, by @korli
- build: Read Legacy support is now limited to v0.5+ by default. Can be changed at compile time with macro `ZSTD_LEGACY_SUPPORT`.
- doc : `zstd_compression_format.md` updated to match wording in [IETF RFC 8478](https://tools.ietf.org/html/rfc8478)
- misc: tests/paramgrill, a parameter optimizer, by @GeorgeLu97 2018-10-05T16:48:23+00:00zstd v1.3.7zstd v1.3.72018-10-19T21:34:33+00:00This is minor fix release building upon v1.3.6.
The main reason we publish this new version is that @indygreg detected an important compression ratio regression for a specific scenario (compressing with dictionary at level 9 or 10 for small data, or 11 - 12 for large data) . We don't anticipate this scenario to be common : dictionary compression is still rare, then most users prefer fast modes (levels <=3), a few rare ones use strong modes (level 15-19), so "middle compression" is an extreme rarity.
But just in case some user do, we publish this release.
A few other minor things were ongoing and are therefore bundled.
Decompression speed might be slightly better with `clang`, depending on exact target and version. We could observe as mush as 7% speed gains in some cases, though in other cases, it's rather in the ~2% range.
The integrated backtrace functionality in the cli is updated : its presence can be more easily controlled, invoking `BACKTRACE` build macro. The automatic detector is more restrictive, and release mode builds without it by default. We want to be sure the default `make` compiles without any issue on most platforms.
Finally, the list of man pages has been completed with documentation for `zstdless` and `zstdgrep`, by @samrussell .
#### Detailed list of changes
- perf: slightly better decompression speed on clang (depending on hardware target)
- fix : ratio for dictionary compression at levels 9 and 10, reported by @indygreg
- build: no longer build backtrace by default in release mode; restrict further automatic mode
- build: control backtrace support through build macro BACKTRACE
- misc: added man pages for zstdless and zstdgrep, by @samrussell2018-10-19T21:34:33+00:00zstd regression-datazstd regression-data2018-11-29T18:53:21+00:00Zstandard regression testing data2018-11-29T18:53:21+00:00zstd v1.3.8zstd v1.3.82018-12-27T18:39:10+00:00#### Advanced API
`v1.3.8` main focus is the stabilization of the [advanced API](https://github.com/facebook/zstd/blob/v1.3.8/lib/zstd.h#L419).
This API has been in the making for more than a year, and makes it possible to trigger advanced features, such as multithreading, `--long` mode, or detailed frame parameters, in a straightforward and extensible manner. Some examples are provided [in this blog entry](https://code.fb.com/core-data/zstandard/).
To make this vision possible, the advanced API relies on sticky parameters, which can be stacked on top of each other in any order. This makes it possible to introduce new features in the future without breaking API nor ABI.
This API has provided a good experience in our infrastructure, and we hope it will prove easy to use and efficient in your applications. Nonetheless, before being branded "stable", this proposal must spend a last round in "staging area", in order to generate comments and feedback from new users. It's planned to be labelled "stable" by `v1.4.0`, which is expected to be next release, depending on received feedback.
The experimental section still contains a lot of prototypes which are largely redundant with the new advanced API. Expect them to become deprecated, and then later dropped in some future. Transition towards the newer advanced API is therefore highly recommended.
#### Performance
Decoding speed has been improved again, primarily for some specific scenarios : frames using large window sizes (`--ultra` or `--long`), and cold dictionary. Cold dictionary is expected to become more important in the near future, as solutions relying on thousands of dictionaries simultaneously will be deployed.
The higher compression levels get a slight compression ratio boost, mostly visible for small (<256 KB) and large (>32 MB) data streams. This change benefits asymmetric scenarios (compress ones, decompress many times), typically targeting level 19.
#### New features
A noticeable addition, @terrelln introduces the [`--rsyncable` mode](https://github.com/facebook/zstd/blob/v1.3.8/programs/zstd.1.md#operation-modifiers) to `zstd`. Similar to `gzip --rsyncable`, it generates a compressed frame which is friendly to `rsync` in case of limited changes : a difference in the input data will only impact a small localized amount of compressed data, instead of everything from the position onward due to cascading impacts. This is useful for very large archives regularly updated and synchronized over long distance connections (as an example, compressed mailboxes come to mind).
The method used by `zstd` preserves the compression ratio very well, introducing only very tiny losses due to synchronization points, meaning it's no longer a sacrifice to use `--rsyncable`. Here is an example on `silesia.tar`, using default compression level :
| compressor | normal | `--rsyncable` | Ratio diff. | time |
| --- | --- | --- | --- | --- |
| gzip | 68235456 | 68778265 | -0.795% | 7.92s |
| zstd | 66829650 | 66846769 | -0.026% | 1.17s |
Speaking of compression of level : it's now possible to use [environment variable `ZSTD_CLEVEL`](https://github.com/facebook/zstd/blob/v1.3.8/programs/README.md#restricted-usage-of-environment-variables) to influence default compression level. This can prove useful in situations where it's not possible to provide command line parameters, typically when `zstd` is invoked "under the hood" by some calling process.
Lastly, anyone interested in embedding a small `zstd` decoder into a space-constrained application will be interested in a [new set of build macros](https://github.com/facebook/zstd/tree/v1.3.8/lib#modular-build) introduced by @felixhandte, which makes it possible to selectively turn off decoder features to reduce binary size even further. Final binary size will of course vary depending on target assembler and compiler, but in preliminary testings on x64, it helped reducing the decoder size by a factor 3 (from ~64KB towards ~20KB).
#### Detailed list of changes
- perf: better decompression speed on large files (+7%) and cold dictionaries (+15%)
- perf: slightly better compression ratio at high compression modes
- api : finalized advanced API, last stage before "stable" status
- api : new `--rsyncable` mode, by @terrelln
- api : support decompression of empty frames into `NULL` (used to be an error) (#1385)
- build: new set of build macros to generate a minimal size decoder, by @felixhandte
- build: fix compilation on MIPS32, reported by @clbr (#1441)
- build: fix compilation with multiple -arch flags, by @ryandesign
- build: highly upgraded meson build, by @lzutao
- build: improved buck support, by @obelisk
- build: fix `cmake` script : can create debug build, by @pitrou
- build: `Makefile` : grep works on both colored consoles and systems without color support
- build: fixed `zstd-pgo` target, by @bmwiedemann
- cli : support `ZSTD_CLEVEL` environment variable, by @yijinfb (#1423)
- cli : `--no-progress` flag, preserving final summary (#1371), by @terrelln
- cli : ensure destination file is not source file (#1422)
- cli : clearer error messages, notably when input file not present
- doc : clarified `zstd_compression_format.md`, by @ulikunitz
- misc: fixed `zstdgrep`, returns 1 on failure, by @lzutao
- misc: `NEWS` renamed as `CHANGELOG`, in accordance with fb.oss policy
2018-12-27T18:39:10+00:00zstd v1.4.0zstd v1.4.02019-04-16T22:53:28+00:00### Advanced API
The main focus of the v1.4.0 release is the stabilization of the advanced API.
The advanced API provides a way to set specific parameters during compression and decompression in an API and ABI compatible way. For example, it allows you to compress with [multiple threads](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L349), enable [--long](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L311) mode, set [frame parameters](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L338), and [load dictionaries](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L873). It is compatible with `ZSTD_compressStream*()` and `ZSTD_compress2()`. There is also an advanced decompression API that allows you to set parameters like [maximum memory usage](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L490), and [load dictionaries](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L925). It is compatible with the existing decompression functions `ZSTD_decompressStream()` and `ZSTD_decompressDCtx()`.
The old streaming functions are all compatible with the new API, and the documentation provides the equivalent function calls in the new API. For example, see [`ZSTD_initCStream()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L677). The stable functions will remain supported, but the functions in the experimental sections, like [`ZSTD_initCStream_usingDict()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L1597), will eventually be marked as deprecated and removed in favor of the new advanced API.
The [examples](https://github.com/facebook/zstd/tree/a880ca239b447968493dd2fed3850e766d6305cc/examples) have all been updated to use the new advanced API. If you have questions about how to use the new API, please refer to the examples, and if they are unanswered, please open an issue.
### Performance
Zstd's fastest compression level just got faster! Thanks to ideas from Intel's [igzip](https://github.com/01org/isa-l/tree/master/igzip) and @gbtucker, we've made level 1, zstd's fastest strategy, 6-8% faster in most scenarios. For example on the [Silesia Corpus](http://sun.aei.polsl.pl/~sdeor/index.php?page=silesia) with level 1, we see 0.2% better compression compared to zstd-1.3.8, and these performance figures on an Intel i9-9900K:
Version | C. Speed | D. Speed
-- | -- | --
1.3.8 gcc-8 | 489 MB/s | 1343 MB/s
1.4.0 gcc-8 | 532 MB/s (+8%) | 1346 MB/s
1.3.8 clang-8 | 488 MB/s | 1188 MB/s
1.4.0 clang-8 | 528 MB/s (+8%) | 1216 MB/s
### New Features
A new experimental function [`ZSTD_decompressBound()`](https://github.com/facebook/zstd/blob/a880ca239b447968493dd2fed3850e766d6305cc/lib/zstd.h#L1178) has been added by @shakeelrao. It is useful when decompressing zstd data in a single shot that may, or may not have the decompressed size written into the frame. It is exact when the decompressed size is written into the frame, and a tight upper bound within 128 KB, as long as `ZSTD_e_flush` and `ZSTD_flushStream()` aren't used. When `ZSTD_e_flush` is used, in the worst case the bound can be very large, but this isn't a common scenario.
The parameter `ZSTD_c_literalCompressionMode` and the CLI flag `--[no-]compress-literals` allow users to explicitly enable and disable literal compression. By default literals are compressed with positive compression levels, and left uncompressed for negative compression levels. Disabling literal compression boosts compression and decompression speed, at the cost of compression ratio.
### Detailed list of changes
* perf: Improve level 1 compression speed in most scenarios by 6% by @gbtucker and @terrelln
* api: Move the advanced API, including all functions in the staging section, to the stable section
* api: Make ZSTD_e_flush and ZSTD_e_end block for maximum forward progress
* api: Rename `ZSTD_CCtxParam_getParameter` to `ZSTD_CCtxParams_getParameter`
* api: Rename `ZSTD_CCtxParam_setParameter` to `ZSTD_CCtxParams_setParameter`
* api: Don't export ZSTDMT functions from the shared library by default
* api: Require `ZSTD_MULTITHREAD` to be defined to use ZSTDMT
* api: Add `ZSTD_decompressBound()` to provide an upper bound on decompressed size by @shakeelrao
* api: Fix `ZSTD_decompressDCtx()` corner cases with a dictionary
* api: Move `ZSTD_getDictID_*()` functions to the stable section
* api: Add `ZSTD_c_literalCompressionMode` flag to enable or disable literal compression by @terrelln
* api: Allow compression parameters to be set when a dictionary is used
* api: Allow setting parameters before or after `ZSTD_CCtx_loadDictionary()` is called
* api: Fix `ZSTD_estimateCStreamSize_usingCCtxParams()`
* api: Setting `ZSTD_d_maxWindowLog` to `0` means use the default
* cli: Ensure that a dictionary is not used to compress itself by @shakeelrao
* cli: Add `--[no-]compress-literals` flag to enable or disable literal compression
* doc: Update the examples to use the advanced API
* doc: Explain how to transition from old streaming functions to the advanced API in the header
* build: Improve the Windows release packages
* build: Improve CMake build by @hjmjohnson
* build: Build fixes for FreeBSD by @lwhsu
* build: Remove redundant warnings by @thatsafunnyname
* build: Fix tests on OpenBSD by @bket
* build: Extend fuzzer build system to work with the new clang engine
* build: CMake now creates the `libzstd.so.1` symlink
* build: Improve Menson build by @lzutao
* misc: Fix symbolic link detection on FreeBSD
* misc: Use physical core count for `-T0` on FreeBSD by @cemeyer
* misc: Fix `zstd --list` on truncated files by @kostmo
* misc: Improve logging in debug mode by @felixhandte
* misc: Add CirrusCI tests by @lwhsu
* misc: Optimize dictionary memory usage in corner cases
* misc: Improve the dictionary builder on small or homogeneous data
* misc: Fix spelling across the repo by @jsoref2019-04-16T22:53:28+00:00zstd v1.4.1zstd v1.4.12019-07-19T19:03:30+00:00### Maintenance
This release is primarily a maintenance release.
It includes a few bug fixes, including a fix for a rare data corruption bug, which could only be triggered in a niche use case, when doing all of the following: using multithreading mode, with an overlap size >= 512 MB, using a strategy >= `ZSTD_btlazy`, and compressing more than 4 GB. None of the default compression levels meet these requirements (not even `--ultra` ones).
### Performance
This release also includes some performance improvements, among which the primary improvement is that Zstd decompression is ~7% faster, thanks to @mgrice.
See this comparison of decompression speeds at different compression levels, measured on the Silesia Corpus, on an Intel i9-9900K with GCC 9.1.0.
| Level | v1.4.0 | v1.4.1 | Delta |
| ---: | :---: | :---: | ---: |
| 1 | 1390 MB/s | 1453 MB/s | +4.5% |
| 3 | 1208 MB/s | 1301 MB/s | +7.6% |
| 5 | 1129 MB/s | 1233 MB/s | +9.2% |
| 7 | 1224 MB/s | 1347 MB/s | +10.0% |
| 16 | 1278 MB/s | 1430 MB/s | +11.8% |
### Detailed list of changes
* bug: Fix data corruption in niche use cases by @terrelln (#1659)
* bug: Fuzz legacy modes, fix uncovered bugs by @terrelln (#1593, #1594, #1595)
* bug: Fix out of bounds read by @terrelln (#1590)
* perf: Improved decoding speed by ~7% @mgrice (#1668)
* perf: Large compression ratio improvement for small `windowLog` by @cyan4973 (#1624)
* perf: Slightly improved compression ratio of level 3 and 4 (`ZSTD_dfast`) by @cyan4973 (#1681)
* perf: Slightly faster compression speed when re-using a context by @cyan4973 (#1658)
* perf: Faster compression speed in high compression mode for repetitive data by @terrelln (#1635)
* api: Add parameter to generate smaller dictionaries by @tyler-tran (#1656)
* cli: Recognize symlinks when built in C99 mode by @felixhandte (#1640)
* cli: Expose cpu load indicator for each file on -vv mode by @ephiepark (#1631)
* cli: Restrict read permissions on destination files by @chungy (#1644)
* cli: zstdgrep: handle -f flag by @felixhandte (#1618)
* cli: zstdcat: follow symlinks by @vejnar (#1604)
* doc: Remove extra size limit on compressed blocks by @felixhandte (#1689)
* doc: Fix typo by @yk-tanigawa (#1633)
* doc: Improve documentation on streaming buffer sizes by @cyan4973 (#1629)
* build: CMake: support building with LZ4 @leeyoung624 (#1626)
* build: CMake: install zstdless and zstdgrep by @leeyoung624 (#1647)
* build: CMake: respect existing uninstall target by @j301scott (#1619)
* build: Make: skip multithread tests when built without support by @michaelforney (#1620)
* build: Make: Fix examples/ test target by @sjnam (#1603)
* build: Meson: rename options out of deprecated namespace by @lzutao (#1665)
* build: Meson: fix build by @lzutao (#1602)
* build: Visual Studio: don't export symbols in static lib by @scharan (#1650)
* build: Visual Studio: fix linking by @absotively (#1639)
* build: Fix MinGW-W64 build by @myzhang1029 (#1600)
* misc: Expand decodecorpus coverage by @ephiepark (#1664)
2019-07-19T19:03:30+00:00zstd v1.4.2zstd v1.4.22019-07-25T17:48:57+00:00### Legacy Decompression Fix
This release is a small one, that corrects an issue discovered in the previous release. Zstandard v1.4.1 included a bug in decompressing v0.5 legacy frames, which is fixed in v1.4.2.
### Detailed Changes
* bug: Fix bug in zstd-0.5 decoder by @terrelln (#1696)
* bug: Fix seekable decompression in-memory API by @iburinoc (#1695)
* bug: Close minor memory leak in CLI by @LeeYoung624 (#1701)
* misc: Validate blocks are smaller than size limit by @vivekmig (#1685)
* misc: Restructure source files by @ephiepark (#1679)
2019-07-25T17:48:57+00:00zstd v1.4.3zstd v1.4.32019-08-19T20:55:18+00:00### Dictionary Compression Regression
We discovered an issue in the v1.4.2 release, which can degrade the effectiveness of dictionary compression. This release fixes that issue.
### Detailed Changes
* bug: Fix Dictionary Compression Ratio Regression by @cyan4973 (#1709)
* bug: Fix Buffer Overflow in v0.3 Decompression by @felixhandte (#1722)
* build: Add support for IAR C/C++ Compiler for Arm by @joseph0918 (#1705)
* misc: Add NULL pointer check in util.c by @leeyoung624 (#1706)2019-08-19T20:55:18+00:00zstd v1.4.4zstd v1.4.42019-11-05T18:36:09+00:00This release includes some major performance improvements and new CLI features, which make it a recommended upgrade.
## Faster Decompression Speed
Decompression speed has been substantially improved, thanks to @terrelln. Exact mileage obviously varies depending on files and scenarios, but the general expectation is a bump of about +10%. The benefit is considered applicable to all scenarios, and will be perceptible for most usages.
Some benchmark figures for illustration:
| | v1.4.3 | v1.4.4 |
| --- | --- | --- |
| silesia.tar | 1440 MB/s | 1600 MB/s |
| enwik8 | 1225 MB/s | 1390 MB/s |
| calgary.tar | 1360 MB/s | 1530 MB/s |
## Faster Compression Speed when Re-Using Contexts
In server workloads (characterized by very high compression volume of relatively small inputs), the allocation and initialization of `zstd`'s internal datastructures can become a significant part of the cost of compression. For this reason, `zstd` has long had an optimization (which we recommended for large-scale users, perhaps with something like [this](https://github.com/facebook/folly/blob/master/folly/compression/CompressionContextPool.h)): when you provide an already-used `ZSTD_CCtx` to a compression operation, `zstd` tries to re-use the existing data structures, if possible, rather than re-allocate and re-initialize them.
Historically, this optimization could avoid re-allocation most of the time, but required an exact match of internal parameters to avoid re-initialization. In this release, @felixhandte removed the dependency on matching parameters, allowing the full context re-use optimization to be applied to effectively all compressions. Practical workloads on small data should expect a ~3% speed-up.
In addition to improving average performance, this change also has some nice side-effects on the extremes of performance.
* On the fast end, it is now easier to get optimal performance from `zstd`. In particular, it is no longer necessary to do careful tracking and matching of contexts to compressions based on detailed parameters (as discussed for example in #1796). Instead, straightforwardly reusing contexts is now optimal.
* Second, this change ameliorates some rare, degenerate scenarios (e.g., high volume streaming compression of small inputs with varying, high compression levels), in which it was possible for the allocation and initialization work to vastly overshadow the actual compression work. These cases are up to 40x faster, and now perform in-line with similar happy cases.
## Dictionaries and Large Inputs
In theory, using a dictionary should always be beneficial. However, due to some long-standing implementation limitations, it can actually be detrimental. Case in point: by default, dictionaries are prepared to compress small data (where they are most useful). When this prepared dictionary is used to compress large data, there is a mismatch between the prepared parameters (targeting small data) and the ideal parameters (that would target large data). This can cause dictionaries to counter-intuitively result in a *lower* compression ratio when compressing large inputs.
Starting with v1.4.4, using a dictionary with a very large input will no longer be detrimental. Thanks to a patch from @senhuang42, whenever the library notices that input is sufficiently large (relative to dictionary size), the dictionary is re-processed, using the optimal parameters for large data, resulting in improved compression ratio.
The capability is also exposed, and can be manually triggered using `ZSTD_dictForceLoad`.
## New commands
`zstd` CLI extends its capabilities, providing new advanced commands, thanks to great contributions :
* `zstd` generated files (compressed or decompressed) can now be automatically stored into a *different* directory than the source one, using `--output-dir-flat=DIR` command, provided by @senhuang42 .
* It’s possible to inform `zstd` about the size of data coming from `stdin` . @nmagerko proposed 2 new commands, allowing users to provide the exact stream size (`--stream-size=#` ) or an approximative one (`--size-hint=#`). Both only make sense when compressing a data stream from a pipe (such as `stdin`), since for a real file, `zstd` obtains the exact source size from the file system. Providing a source size allows `zstd` to better adapt internal compression parameters to the input, resulting in better performance and compression ratio. Additionally, providing the precise size makes it possible to embed this information in the compressed frame header, which also allows decoder optimizations.
* In situations where the same directory content get regularly compressed, with the intention to only compress new files not yet compressed, it’s necessary to filter the file list, to exclude already compressed files. This process is simplified with command `--exclude-compressed`, provided by [@shashank0791](https://github.com/shashank0791) . As the name implies, it simply excludes all compressed files from the list to process.
## Single-File Decoder with Web Assembly
Let’s complete the picture with an impressive contribution from @cwoffenden. `libzstd` has long offered the capability to build only the decoder, in order to generate smaller binaries that can be more easily embedded into memory-constrained devices and applications.
@cwoffenden built on this capability and offers a script creating a single-file decoder, as an amalgamated variant of reference Zstandard’s decoder. The package is completed with a nice build script, which compiles the one-file decoder into `WASM` code, for embedding into web application, and even tests it.
As a capability example, check out the awesome WebGL demo provided by @cwoffenden in `/contrib/single_file_decoder/examples` directory!
## Full List
- perf: Improved decompression speed, by > 10%, by @terrelln
- perf: Better compression speed when re-using a context, by @felixhandte
- perf: Fix compression ratio when compressing large files with small dictionary, by @senhuang42
- perf: `zstd` reference encoder can generate `RLE` blocks, by @bimbashrestha
- perf: minor generic speed optimization, by @davidbolvansky
- api: new ability to extract sequences from the parser for analysis, by @bimbashrestha
- api: fixed decoding of magic-less frames, by @terrelln
- api: fixed `ZSTD_initCStream_advanced()` performance with fast modes, reported by @QrczakMK
- cli: Named pipes support, by @bimbashrestha
- cli: short tar's extension support, by @stokito
- cli: command `--output-dir-flat=DIE` , generates target files into requested directory, by @senhuang42
- cli: commands `--stream-size=#` and `--size-hint=#`, by @nmagerko
- cli: command `--exclude-compressed`, by @shashank0791
- cli: faster `-t` test mode
- cli: improved some error messages, by @vangyzen
- cli: fix rare deadlock condition within dictionary builder, by @terrelln
- build: single-file decoder with emscripten compilation script, by @cwoffenden
- build: fixed `zlibWrapper` compilation on Visual Studio, reported by @bluenlive
- build: fixed deprecation warning for certain gcc version, reported by @jasonma163
- build: fix compilation on old gcc versions, by @cemeyer
- build: improved installation directories for cmake script, by Dmitri Shubin
- pack: modified `pkgconfig`, for better integration into openwrt, requested by @neheb
- misc: Improved documentation : `ZSTD_CLEVEL`, `DYNAMIC_BMI2`, `ZSTD_CDict`, function deprecation, zstd format
- misc: fixed educational decoder : accept larger literals section, and removed `UNALIGNED()` macro2019-11-05T18:36:09+00:00zstd v1.4.5zstd v1.4.52020-05-22T07:08:41+00:00# Zstd v1.4.5 Release Notes
This is a fairly important release which includes performance improvements and new major CLI features. It also fixes a few corner cases, making it a recommended upgrade.
## Faster Decompression Speed
Decompression speed has been improved again, thanks to great contributions from [@terrelln](https://github.com/terrelln).
As usual, exact mileage varies depending on files and compilers.
For `x64` cpus, expect a speed bump of at least +5%, and up to +10% in favorable cases.
`ARM` cpus receive more benefit, with speed improvements ranging from +15% vicinity, and up to +50% for certain SoCs and scenarios (`ARM`‘s situation is more complex due to larger differences in SoC designs).
For illustration, some benchmarks run on a modern `x64` platform using `zstd -b` compiled with `gcc` v9.3.0 :
| |v1.4.4 |v1.4.5 |
|--- |--- |--- |
|silesia.tar |1568 MB/s |1653 MB/s |
|--- |--- |--- |
|enwik8 |1374 MB/s |1469 MB/s |
|calgary.tar |1511 MB/s |1610 MB/s |
Same platform, using `clang` v10.0.0 compiler :
| |v1.4.4 |v1.4.5 |
|--- |--- |--- |
|silesia.tar |1439 MB/s |1496 MB/s |
|--- |--- |--- |
|enwik8 |1232 MB/s |1335 MB/s |
|calgary.tar |1361 MB/s |1457 MB/s |
## Simplified integration
Presuming a project needs to integrate `libzstd`'s *source code* (as opposed to linking a pre-compiled library), the `/lib` source directory can be copy/pasted into target project. Then the local build system must setup a few include directories. Some setups are automatically provided in prepared build scripts, such as `Makefile`, but any other 3rd party build system must do it on its own.
This integration is now simplified, thanks to @felixhandte, by making all dependencies within `/lib` relative, meaning it’s only necessary to setup include directories for the `*.h` header files that are directly included into target project (typically `zstd.h`). Even that task can be circumvented by copy/pasting the `*.h` into already established include directories.
Alternatively, if you are a fan of one-file integration strategy, @cwoffenden has extended his one-file decoder script into a full feature [one-file compression library](https://github.com/facebook/zstd/tree/dev/contrib/single_file_libs). The script [`create_single_file_library.sh`](https://github.com/facebook/zstd/blob/dev/contrib/single_file_libs/create_single_file_library.sh) will generate a file `zstd.c`, which contains all selected elements from the library (by default, compression and decompression). It’s then enough to import just `zstd.h` and the generated `zstd.c` into target project to access all included capabilities.
## `--patch-from`
Zstandard CLI is introducing a new command line option `--patch-from`, which leverages existing compressors, dictionaries and long range match finder to deliver a high speed engine for producing and applying patches to files.
`--patch-from` is based on dictionary compression. It will consider a previous version of a file as a dictionary, to better compress a new version of same file. This operation preserves fast `zstd` speeds at lower compression levels. To this ends, it also increases the previous maximum limit for dictionaries from 32 MB to 2 GB, and automatically uses the long range match finder when needed (though it can also be manually overruled).
`--patch-from` can also be combined with multi-threading mode at a very minimal compression ratio loss.
Example usage:
```
`# create the patch
zstd --patch-from=<oldfile> <newfile> -o <patchfile>
# apply the patch
zstd -d --patch-from=<oldfile> <patchfile> -o <newfile>`
```
Benchmarks:
We compared `zstd` to `bsdiff`, a popular industry grade diff engine. Our test corpus were tarballs of different versions of source code from popular GitHub repositories. Specifically:
```
`repos = {
# ~31mb (small file)
"zstd": {"url": "https://github.com/facebook/zstd", "dict-branch": "refs/tags/v1.4.2", "src-branch": "refs/tags/v1.4.3"},
# ~273mb (medium file)
"wordpress": {"url": "https://github.com/WordPress/WordPress", "dict-branch": "refs/tags/5.3.1", "src-branch": "refs/tags/5.3.2"},
# ~1.66gb (large file)
"llvm": {"url": "https://github.com/llvm/llvm-project", "dict-branch": "refs/tags/llvmorg-9.0.0", "src-branch": "refs/tags/llvmorg-9.0.1"}
}`
```
`--patch-from` on level 19 (with chainLog=30 and targetLength=4kb) is comparable with `bsdiff` when comparing patch sizes.
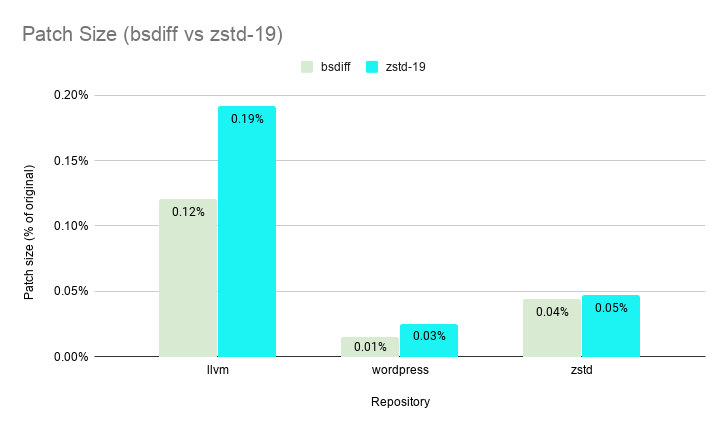
`--patch-from` greatly outperforms `bsdiff` in speed even on its slowest setting of level 19 boasting an average speedup of ~7X. `--patch-from` is >200X faster on level 1 and >100X faster (shown below) on level 3 vs `bsdiff` while still delivering patch sizes less than 0.5% of the original file size.
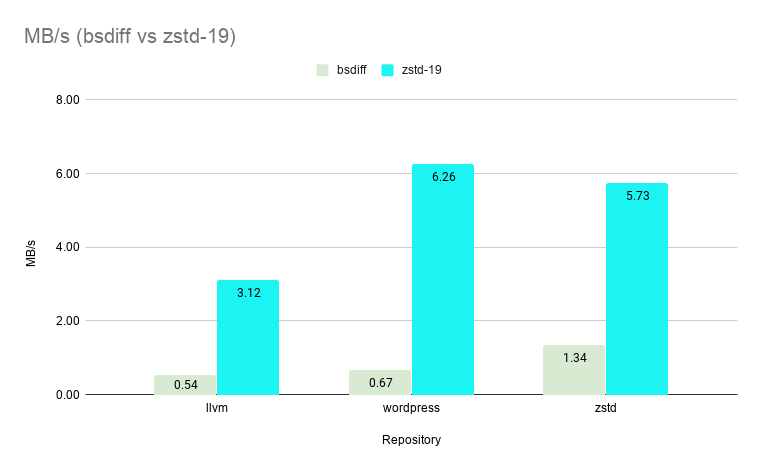
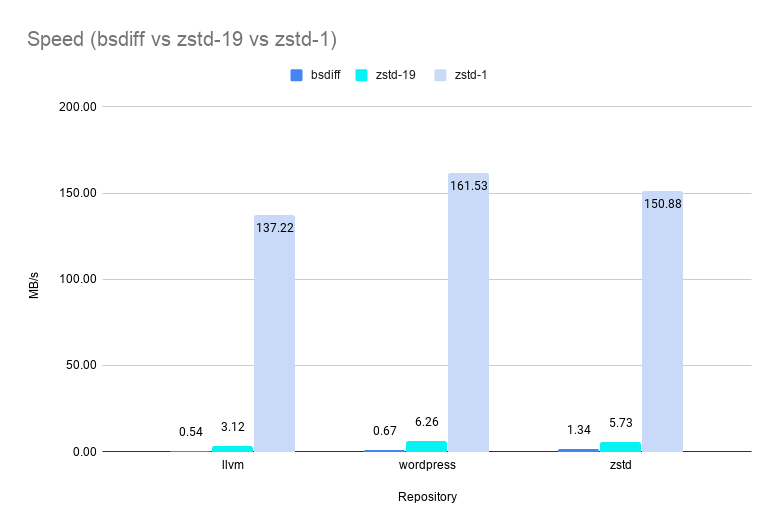
And of course, there is no change to the fast zstd decompression speed.
## `--filelist=`
Finally, `--filelist=` is a new CLI capability, which makes it possible to pass a list of files to operate upon from a file,
as opposed to listing all target files solely on the command line.
This makes it possible to prepare a list offline, save it into a file, and then provide the prepared list to `zstd`.
Another advantage is that this method circumvents command line size limitations, which can become a problem when operating on very large directories (such situation can typically happen with shell expansion).
In contrast, passing a very large list of filenames from within a file is free of such size limitation.
## Full List
- perf: Improved decompression speed (x64 >+5%, ARM >+15%), by @terrelln
- perf: Automatically downsizes `ZSTD_DCtx` when too large for too long (#2069, by @bimbashreshta)
- perf: Improved fast compression speed on `aarch64` (#2040, ~+3%, by @caoyzh)
- perf: Small level 1 compression speed gains (depending on compiler)
- fix: Compression ratio regression on huge files (> 3 GB) using high levels (`--ultra`) and multithreading, by @terrelln
- api: `ZDICT_finalizeDictionary()` is promoted to stable (#2111)
- api: new experimental parameter `ZSTD_d_stableOutBuffer` (#2094)
- build: Generate a single-file `libzstd` library (#2065, by [@cwoffenden](https://github.com/cwoffenden))
- build: Relative includes, no longer require `-I` flags for `zstd` lib subdirs (#2103, by @felixhandte)
- build: `zstd` now compiles cleanly under `-pedantic` (#2099)
- build: `zstd` now compiles with make-4.3
- build: Support `mingw` cross-compilation from Linux, by @Ericson2314
- build: Meson multi-thread build fix on windows
- build: Some misc `icc` fixes backed by new ci test on travis
- cli: New `--patch-from` command, create and apply patches from files, by @bimbashreshta
- cli: `--filelist=` : Provide a list of files to operate upon from a file
- cli: `-b` can now benchmark multiple files in decompression mode
- cli: New `--no-content-size` command
- cli: New `--show-default-cparams` command
- misc: new diagnosis tool, `checked_flipped_bits`, in `contrib/`, by @felixhandte
- misc: Extend largeNbDicts benchmark to compression
- misc: experimental edit-distance match finder in `contrib/`
- doc: Improved beginner `CONTRIBUTING.md` docs
- doc: New issue templates for zstd 2020-05-22T07:08:41+00:00zstd v1.4.7zstd v1.4.72020-12-17T03:32:24+00:00`v1.4.7` unleashes several months of improvements across many axis, from performance to various fixes, to new capabilities, of which a few are highlighted below. It’s a recommended upgrade.
(Note: if you ever wondered what happened to `v1.4.6`, it’s an internal release number reserved for synchronization with Linux Kernel)
## Improved `--long` mode
`--long` mode makes it possible to analyze vast quantities of data in reasonable time and memory budget. The `--long` mode algorithm runs on top of the regular match finder, and both contribute to the final compressed outcome.
However, the fact that these 2 stages were working independently resulted in minor discrepancies at highest compression levels, where the cost of each decision must be carefully monitored. For this reason, in situations where the input is not a good fit for `--long` mode (no large repetition at long distance), enabling it *could* reduce compression performance, even if by very little, compared to not enabling it (at high compression levels). This situation made it more difficult to "just always enable" the `--long` mode by default.
This is fixed in this version. For compression levels 16 and up, usage of `--long` will now never regress compared to compression without `--long`. This property made it possible to ramp up `--long` mode contribution to the compression mix, improving its effectiveness.
The compression ratio improvements are most notable when `--long` mode is actually useful. In particular, `--patch-from` (which implicitly relies on `--long`) shows excellent gains from the improvements. We present some brief results [here](https://github.com/facebook/zstd/wiki/Zstandard-as-a-patching-engine) (tested on Macbook Pro 16“, i9).

Since `--long` mode is now always beneficial at high compression levels, it’s now automatically enabled for any window size >= 128MB and up.
## Faster decompression of small blocks
This release includes optimizations that significantly speed up decompression of small blocks and small data. The decompression speed gains will vary based on the block size according to the table below:
Block Size | Decompression Speed Improvement
-----------|--------------------------------
1 KB | ~+30%
2 KB | ~+30%
4 KB | ~+25%
8 KB | ~+15%
16 KB | ~+10%
32 KB | ~+5%
These optimizations come from improving the process of reading the block header, and building the Huffman and FSE decoding tables. `zstd`’s default block size is 128 KB, and at this block size the time spent decompressing the data dominates the time spent reading the block header and building the decoding tables. But, as blocks become smaller, the cost of reading the block header and building decoding tables becomes more prominent.
## CLI improvements
The CLI received several noticeable upgrades with this version.
To begin with, `zstd` can accept a new parameter through environment variable, `ZSTD_NBTHREADS` . It’s useful when `zstd` is called behind an application (`tar`, or a python script for example). Also, users which prefer multithreaded compression by default can now set a desired nb of threads with their environment. This setting can still be overridden on demand via command line.
A new command `--output-dir-mirror` makes it possible to compress a directory containing subdirectories (typically with `-r` command) producing one compressed file per source file, and reproduce the arborescence into a selected destination directory.
There are other various improvements, such as more accurate warning and error messages, full equivalence between conventions `--long-command=FILE` and `--long-command FILE`, fixed confusion risks between `stdin` and user prompt, or between console output and status message, as well as a new short execution summary when processing multiple files, cumulatively contributing to a nicer command line experience.
## New experimental features
### Shared Thread Pool
By default, each compression context can be set to use a maximum nb of threads.
In complex scenarios, there might be multiple compression contexts, working in parallel, and each using some nb of threads. In such cases, it might be desirable to control the _total_ nb of threads used by _all_ these compression contexts altogether.
This is now possible, by making all these compression contexts share the same threadpool. This capability is expressed thanks to a new advanced compression parameter, ``ZSTD_CCtx_refThreadPool()``, contributed by @marxin. See its [documentation](https://github.com/facebook/zstd/blob/v1.4.7/lib/zstd.h#L1501) for more details.
### Faster Dictionary Compression
This release introduces a new experimental dictionary compression algorithm, applicable to mid-range compression levels, employing strategies such as `ZSTD_greedy`, `ZSTD_lazy`, and `ZSTD_lazy2`. This new algorithm can be triggered by selecting the compression parameter `ZSTD_c_enableDedicatedDictSearch` during `ZSTD_CDict` creation (experimental section).
Benchmarks show the new algorithm providing significant compression speed gains :
Level | Hot Dict | Cold Dict
----- | -------- | ---------
5 | ~+17% | ~+30%
6 | ~+12% | ~+45%
7 | ~+13% | ~+40%
8 | ~+16% | ~+50%
9 | ~+19% | ~+65%
10 | ~+24% | ~+70%
We hope it will help making mid-levels compression more attractive for dictionary scenarios. See [the documentation](https://github.com/facebook/zstd/blob/9f8b180/lib/zstd.h#L1663-L1717) for more details. Feedback is welcome!
### New Sequence Ingestion API
We introduce a new entry point, `ZSTD_compressSequences()`, which makes it possible for users to define their own sequences, by whatever mechanism they prefer, and present them to this new entry point, which will generate a single `zstd`-compressed frame, based on provided sequences.
So for example, users can now feed to the function an array of externally generated `ZSTD_Sequence`:
`[(offset: 5, matchLength: 4, litLength: 10), (offset: 7, matchLength: 6, litLength: 3), ...]` and the function will output a zstd compressed frame based on these sequences.
This experimental API has currently several limitations (and its relevant params exist in the “experimental” section). Notably, this API currently ignores any repeat offsets provided, instead always recalculating them on the fly. Additionally, there is no way to forcibly specify existence of certain zstd features, such as RLE or raw blocks.
If you are interested in this new entry point, please refer to `zstd.h` for more detailed usage instructions.
## Changelog
There are many other features and improvements in this release, and since we can’t highlight them all, they are listed below:
- perf: stronger `--long` mode at high compression levels, by @senhuang42
- perf: stronger `--patch-from` at high compression levels, thanks to `--long` improvements
- perf: faster decompression speed for small blocks, by @terrelln
- perf: faster dictionary compression at medium compression levels, by @felixhandte
- perf: small speed & memory usage improvements for `ZSTD_compress2()`, by @terrelln
- perf: minor generic decompression speed improvements, by @helloguo
- perf: improved fast compression speeds with Visual Studio, by @animalize
- cli : Set nb of threads with environment variable `ZSTD_NBTHREADS`, by @senhuang42
- cli : new `--output-dir-mirror DIR` command, by @xxie24 (#2219)
- cli : accept decompressing files with `*.zstd` suffix
- cli : `--patch-from` can compress `stdin` when used with `--stream-size`, by @bimbashrestha (#2206)
- cli : provide a condensed summary by default when processing multiple files
- cli : fix : `stdin` input can no longer be confused with user prompt
- cli : fix : console output no longer mixes `stdout` and status messages
- cli : improve accuracy of several error messages
- api : new sequence ingestion API, by @senhuang42
- api : shared thread pool: control total nb of threads used by multiple compression jobs, by @marxin
- api : new `ZSTD_getDictID_fromCDict()`, by @LuAPi
- api : zlibWrapper only uses public API, and is compatible with dynamic library, by @terrelln
- api : fix : multithreaded compression has predictable output even in special cases (see #2327) (issue not present on cli)
- api : fix : dictionary compression correctly respects dictionary compression level (see #2303) (issue not present on cli)
- api : fix : return `dstSize_tooSmall` error whenever appropriate
- api : fix : `ZSTD_initCStream_advanced()` with static allocation and no dictionary
- build: fix cmake script when employing path including spaces, by @terrelln
- build: new `ZSTD_NO_INTRINSICS` macro to avoid explicit intrinsics
- build: new `STATIC_BMI2` macro for compile time detection of BMI2 on MSVC, by @Niadb (#2258)
- build: improved compile-time detection of aarch64/neon platforms, by @bsdimp
- build: Fix building on AIX 5.1, by @likema
- build: compile paramgrill with cmake on Windows, requested by @mirh
- build: install pkg-config file with CMake and MinGW, by @tonytheodore (#2183)
- build: Install DLL with CMake on Windows, by @BioDataAnalysis (#2221)
- build: fix : cli compilation with uclibc
- misc: Improve single file library and include dictBuilder, by @cwoffenden
- misc: Fix single file library compilation with Emscripten, by @yoshihitoh (#2227)
- misc: Add freestanding translation script in `contrib/freestanding_lib`, by @terrelln
- doc : clarify repcode updates in format specification, by @felixhandte2020-12-17T03:32:24+00:00zstd v1.4.8zstd v1.4.82020-12-19T00:51:41+00:00This is a minor hotfix for `v1.4.7`,
where an internal buffer unalignment bug was detected by @bmwiedemann .
The issue is of no consequence for `x64` and `arm64` targets,
but could become a problem for cpus relying on strict alignment, such as `mips` or older `arm` designs.
Additionally, some targets, like 32-bit `x86` cpus, do not care much about alignment, but the code does, and will detect the misalignment and return an error code. Some other less common platforms, such as `s390x`, also seem to trigger the same issue.
While it's a minor fix, this update is nonetheless recommended.
2020-12-19T00:51:41+00:00zstd v1.4.9zstd v1.4.92021-03-03T20:38:04+00:00This is an incremental release which includes various improvements and bug-fixes.
## >2x Faster Long Distance Mode
Long Distance Mode (LDM) `--long` just got a whole lot faster thanks to optimizations by @mpu in #2483! These optimizations preserve the compression ratio but drastically speed up compression. It is especially noticeable in multithreaded mode, because the long distance match finder is not parallelized. Benchmarking with `zstd -T0 -1 --long=31` on an Intel I9-9900K at 3.2 GHz we see:
|File |v1.4.8 MB/s |v1.4.9 MB/s |Improvement |
|--- |--- |--- |--- |
|silesia.tar |308 |692 |125% |
|linux-versions* |312 |667 |114% |
|enwik9 |294 |747 |154% |
\* `linux-versions` is a concatenation of the linux 4.0, 5.0, and 5.10 git archives.
## New Experimental Decompression Feature: `ZSTD_d_refMultipleDDicts`
If the advanced parameter `ZSTD_d_refMultipleDDicts` is enabled, then multiple calls to `ZSTD_refDDict()` will be honored in the corresponding `DCtx`. Example usage:
```
ZSTD_DCtx* dctx = ZSTD_createDCtx();
ZSTD_DCtx_setParameter(dctx, ZSTD_d_refMultipleDDicts, ZSTD_rmd_refMultipleDDicts);
ZSTD_DCtx_refDDict(dctx, ddict1);
ZSTD_DCtx_refDDict(dctx, ddict2);
ZSTD_DCtx_refDDict(dctx, ddict3);
...
ZSTD_decompress...
```
Decompression of multiple frames, each with their own `dictID`, is now possible with a single `ZSTD_decompress` call. As long as the `dictID` from each frame header references one of the `dictID`s within the `DCtx`, then the corresponding dictionary will be used to decompress that particular frame. Note that this feature is disabled with a statically-allocated `DCtx`.
## Changelog
* bug: Use `umask()` to Constrain Created File Permissions (#2495, @felixhandte)
* bug: Make Simple Single-Pass Functions Ignore Advanced Parameters (#2498, @terrelln)
* api: Add (De)Compression Tracing Functionality (#2482, @terrelln)
* api: Support References to Multiple DDicts (#2446, @senhuang42)
* api: Add Function to Generate Skippable Frame (#2439, @senhuang42)
* perf: New Algorithms for the Long Distance Matcher (#2483, @mpu)
* perf: Performance Improvements for Long Distance Matcher (#2464, @mpu)
* perf: Don't Shrink Window Log when Streaming with a Dictionary (#2451, @terrelln)
* cli: Fix `--output-dir-mirror`'s Rejection of `..`-Containing Paths (#2512, @felixhandte)
* cli: Allow Input From Console When `-f`/`--force` is Passed (#2466, @felixhandte)
* cli: Improve Help Message (#2500, @senhuang42)
* tests: Avoid Using `stat -c` on NetBSD (#2513, @felixhandte)
* tests: Correctly Invoke md5 Utility on NetBSD (#2492, @niacat)
* tests: Remove Flaky Tests (#2455, #2486, #2445, @Cyan4973)
* build: Zstd CLI Can Now be Linked to Dynamic `libzstd` (#2457, #2454 @Cyan4973)
* build: Avoid Using Static-Only Symbols (#2504, @skitt)
* build: Fix Fuzzer Compiler Detection & Update UBSAN Flags (#2503, @terrelln)
* build: Explicitly Hide Static Symbols (#2501, @skitt)
* build: CMake: Enable Only C for lib/ and programs/ Projects (#2498, @concatime)
* build: CMake: Use `configure_file()` to Create the `.pc` File (#2462, @lazka)
* build: Add Guards for `_LARGEFILE_SOURCE` and `_LARGEFILE64_SOURCE` (#2444, @indygreg)
* build: Improve `zlibwrapper` Makefile (#2437, @Cyan4973)
* contrib: Add `recover_directory` Program (#2473, @terrelln)
* doc: Change License Year to 2021 (#2452 & #2465, @terrelln & @senhuang42)
* doc: Fix Typos (#2459, @ThomasWaldmann)
2021-03-03T20:38:04+00:00zstd v1.5.0zstd v1.5.02021-05-14T16:01:54+00:00`v1.5.0` is a major release featuring large performance improvements as well as API changes.
# Performance
## Improved Middle-Level Compression Speed
1.5.0 introduces a new default match finder for the compression strategies `greedy`, `lazy`, and `lazy2`, (which map to levels 5-12 for inputs larger than 256K). The optimization brings a massive improvement in compression speed with slight perturbations in compression ratio (< 0.5%) and equal or decreased memory usage.
Benchmarked with gcc, on an i9-9900K:
| level | `silesia.tar` speed delta | `enwik7` speed delta |
|--------|-----------|------------|
| 5 | +25% | +25% |
| 6 | +50% | +50% |
| 7 | +40% | +40% |
| 8 | +40% | +50% |
| 9 | +50% | +65% |
| 10 | +65% | +80% |
| 11 | +85% | +105% |
| 12 | +110% | +140% |
On heavily loaded machines with significant cache contention, we have internally measured _even larger gains_: 2-3x+ speed at levels 5-7. 🚀
The biggest gains are achieved on files typically larger than 128KB. On files smaller than 16KB, by default we revert back to the legacy match finder which becomes the faster one. This default policy can be overriden manually: the new match finder can be forcibly enabled with the advanced parameter `ZSTD_c_useRowMatchFinder`, or through the CLI option `--[no-]row-match-finder`.
Note: only CPUs that support `SSE2` realize the full extent of this improvement.
## Improved High-Level Compression Ratio
Improving compression ratio via block splitting is now enabled by default for high compression levels (16+). The amount of benefit varies depending on the workload. Compressing archives comprised of heavily differing files will see more improvement than compression of single files that don’t vary much entropically (like text files/enwik). At levels 16+, we observe no measurable regression to compression speed.
**level 22 compression**
| file | ratio 1.4.9 | ratio 1.5.0 | ratio % delta |
|-----|---------|--------|-------|
| silesia.tar | 4.021 | 4.041 | +0.49% |
| calgary.tar | 3.646 | 3.672 | +0.71% |
| enwik7 | 3.579 | 3.579 | +0.0% |
The block splitter can be forcibly enabled on lower compression levels as well with the advanced parameter `ZSTD_c_splitBlocks`. When forcibly enabled at lower levels, speed regressions can become more notable. Additionally, since more compressed blocks may be produced, decompression speed on these blobs may also see small regressions.
## Faster Decompression Speed
The decompression speed of data compressed with large window settings (such as `--long` or `--ultra`) has been significantly improved in this version. The gains vary depending on compiler brand and version, with `clang` generally benefiting the most.
The following benchmark was measured by compressing `enwik9` at level `--ultra -22` (with a 128 MB window size) on a core i7-9700K.
| Compiler version | D. Speed improvement |
| --- | --- |
| gcc-7 | +15% |
| gcc-8 | +10 % |
| gcc-9 | +5% |
| gcc-10 | +1% |
| clang-6 | +21% |
| clang-7 | +16% |
| clang-8 | +16% |
| clang-9 | +18% |
| clang-10 | +16% |
| clang-11 | +15% |
Average decompression speed for “normal” payload is slightly improved too, though the impact is less impressive. Once again, mileage varies depending on exact compiler version, payload, and even compression level. In general, a majority of scenarios see benefits ranging from +1 to +9%. There are also a few outliers here and there, from -4% to +13%. The average gain across all these scenarios stands at ~+4%.
# Library Updates
## Dynamic Library Supports Multithreading by Default
It was already possible to compile `libzstd` with multithreading support. But it was an active operation. By default, the `make` build script would build `libzstd` as a single-thread-only library.
This changes in `v1.5.0`.
Now the dynamic library (typically `libzstd.so.1` on Linux) supports multi-threaded compression by default.
Note that this property is not extended to the static library (typically `libzstd.a` on Linux) because doing so would have impacted the build script of existing client applications (requiring them to add `-pthread` to their recipe), thus potentially breaking their build. In order to avoid this disruption, the static library remains single-threaded by default.
Luckily, this build disruption does not extend to the dynamic library, which can be built with multi-threading support while existing applications linking to `libzstd.so` and expecting only single-thread capabilities will be none the wiser, and remain completely unaffected.
The idea is that starting from `v1.5.0`, applications can _expect_ the dynamic library to support multi-threading should they need it, which will progressively lead to increased adoption of this capability overtime.
That being said, since the locally deployed dynamic library may, or may not, support multi-threading compression, depending on local build configuration, it’s always better to check this capability at runtime. For this goal, it’s enough to check the return value when changing parameter `ZSTD_c_nbWorkers` , and if it results in an error, then multi-threading is not supported.
_Q: What if I prefer to keep the libraries in single-thread mode only ?_
The target `make lib-nomt` will ensure this outcome.
_Q: Actually, I want both static and dynamic library versions to support multi-threading !_
The target `make lib-mt` will generate this outcome.
## Promotions to Stable
Moving up to the higher digit `1.5` signals an opportunity to extend the _stable_ portion of `zstd` public API.
This update is relatively minor, featuring only a few non-controversial newcomers.
`ZSTD_defaultCLevel()` indicates which level is default (applied when selecting level `0`). It completes existing
`ZSTD_minCLevel()` and `ZSTD_maxCLevel()`.
Similarly, `ZSTD_getDictID_fromCDict()` is a straightforward equivalent to already promoted `ZSTD_getDictID_fromDDict()`.
## Deprecations
[Zstd-1.4.0](https://github.com/facebook/zstd/releases/tag/v1.4.0) stabilized a new [advanced API](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L238) which allows users to pass advanced parameters to zstd. We’re now deprecating all the old experimental APIs that are subsumed by the new advanced API. They will be considered for removal in the next Zstd major release zstd-1.6.0. Note that only experimental symbols are impacted. Stable functions, like `ZSTD_initCStream()`, remain fully supported.
The deprecated functions are listed below, together with the migration. All the suggested migrations are stable APIs, meaning that once you migrate, the API will be supported forever. See the documentation for the deprecated functions for more details on how to migrate.
- Functions that migrate to `ZSTD_compress2()` with parameter setters:
* `ZSTD_compress_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469).
* `ZSTD_compress_usingCDict_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469) and [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
- Functions that migrate to `ZSTD_compressStream()` or `ZSTD_compressStream2()` with parameter setters:
* `ZSTD_initCStream_srcSize()`: Use [`ZSTD_CCtx_setPledgedSrcSize()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L471-L486).
* `ZSTD_initCStream_usingDict()`: Use [`ZSTD_CCtx_loadDictionary()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L941-L958).
* `ZSTD_initCStream_usingCDict()`: Use [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
* `ZSTD_initCStream_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469).
* `ZSTD_initCStream_usingCDict_advanced()`: Use [`ZSTD_CCtx_setParameter()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L458-L469) and [`ZSTD_CCtx_refCDict()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L960-L972).
* `ZSTD_resetCStream()`: Use [`ZSTD_CCtx_reset()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L494-L508) and [`ZSTD_CCtx_setPledgedSrcSize()`](https://github.com/facebook/zstd/blob/705a62b612151cff06f453bc3452b9e99088a574/lib/zstd.h#L471-L486).
- Functions that are deprecated without replacement. We don’t expect any users of these functions. Please open an issue if you use these and have questions about how to migrate.
* `ZSTD_compressBegin_advanced()`
* `ZSTD_compressBegin_usingCDict_advanced()`
## Header File Locations
Zstd has slightly re-organized the library layout to move all public headers to the top level `lib/` directory. This is for consistency, so all public headers are in `lib/` and all private headers are in a sub-directory. If you build zstd from source, this may affect your build system.
- `lib/common/zstd_errors.h` has moved to `lib/zstd_errors.h`.
- `lib/dictBuilder/zdict.h` has moved to `lib/zdict.h`.
## Single-File Library
We have moved the scripts in `contrib/single_file_libs` to `build/single_file_libs`. These scripts, originally contributed by @cwoffenden, produce a single compilation-unit amalgamation of the zstd library, which can be convenient for integrating Zstandard into other source trees. This move reflects a commitment on our part to support this tool and this pattern of using zstd going forward.
## Windows Release Artifact Format
We are slightly changing the format of the Windows release `.zip` files, to match our other release artifacts. The `.zip` files now bundle everything in a single folder whose name matches the archive name. The contents of that folder exactly match what was previously included in the root of the archive.
## Signed Releases
We have created a [signing key](http://keys.gnupg.net/pks/lookup?op=get&search=0xEF8FE99528B52FFD) for the Zstandard project. This release and all future releases will be signed by this key. See #2520 for discussion.
# Changelog
- api: Various functions promoted from experimental to stable API: ([#2579](https://github.com/facebook/zstd/pull/2579)-[#2581](https://github.com/facebook/zstd/pull/2581), [@senhuang42](https://github.com/senhuang42))
* `ZSTD_defaultCLevel()`
* `ZSTD_getDictID_fromCDict()`
- api: Several experimental functions have been deprecated and will emit a compiler warning ([#2582](https://github.com/facebook/zstd/pull/2582), [@senhuang42](https://github.com/senhuang42))
* `ZSTD_compress_advanced()`
* `ZSTD_compress_usingCDict_advanced()`
* `ZSTD_compressBegin_advanced()`
* `ZSTD_compressBegin_usingCDict_advanced()`
* `ZSTD_initCStream_srcSize()`
* `ZSTD_initCStream_usingDict()`
* `ZSTD_initCStream_usingCDict()`
* `ZSTD_initCStream_advanced()`
* `ZSTD_initCStream_usingCDict_advanced()`
* `ZSTD_resetCStream()`
- api: `ZSTDMT_NBWORKERS_MAX` reduced to 64 for 32-bit environments ([#2643](https://github.com/facebook/zstd/pull/2643), [@Cyan4973](https://github.com/Cyan4973))
- perf: Significant speed improvements for middle compression levels ([#2494](https://github.com/facebook/zstd/pull/2494), [@senhuang42](https://github.com/senhuang42) & [@terrelln](https://github.com/terrelln))
- perf: Block splitter to improve compression ratio, enabled by default for high compression levels ([#2447](https://github.com/facebook/zstd/pull/2447), [@senhuang42](https://github.com/senhuang42))
- perf: Decompression loop refactor, speed improvements on `clang` and for `--long` modes ([#2614](https://github.com/facebook/zstd/pull/2614) [#2630](https://github.com/facebook/zstd/pull/2630), [@Cyan4973](https://github.com/Cyan4973))
- perf: Reduced stack usage during compression and decompression entropy stage ([#2522](https://github.com/facebook/zstd/pull/2522) [#2524](https://github.com/facebook/zstd/pull/2524), [@terrelln](https://github.com/terrelln))
- bug: Make the number of physical CPU cores detection more robust ([#2517](https://github.com/facebook/zstd/pull/2517), [@PaulBone](https://github.com/PaulBone))
- bug: Improve setting permissions of created files ([#2525](https://github.com/facebook/zstd/pull/2525), [@felixhandte](https://github.com/felixhandte))
- bug: Fix large dictionary non-determinism ([#2607](https://github.com/facebook/zstd/pull/2607), [@terrelln](https://github.com/terrelln))
- bug: Fix various dedicated dictionary search bugs ([#2540](https://github.com/facebook/zstd/pull/2540) [#2586](https://github.com/facebook/zstd/pull/2586), [@senhuang42](https://github.com/senhuang42) [@felixhandte](https://github.com/felixhandte))
- bug: Fix non-determinism test failures on Linux i686 ([#2606](https://github.com/facebook/zstd/pull/2606), [@terrelln](https://github.com/terrelln))
- bug: Fix UBSAN error in decompression ([#2625](https://github.com/facebook/zstd/pull/2625), [@terrelln](https://github.com/terrelln))
- bug: Fix superblock compression divide by zero bug ([#2592](https://github.com/facebook/zstd/pull/2592), [@senhuang42](https://github.com/senhuang42))
- bug: Ensure `ZSTD_estimateCCtxSize*()` monotonically increases with compression level ([#2538](https://github.com/facebook/zstd/pull/2538), [@senhuang42](https://github.com/senhuang42))
- doc: Improve `zdict.h` dictionary training API documentation ([#2622](https://github.com/facebook/zstd/pull/2622), [@terrelln](https://github.com/terrelln))
- doc: Note that public `ZSTD_free*()` functions accept NULL pointers ([#2521](https://github.com/facebook/zstd/pull/2521), [@animalize](https://github.com/animalize))
- doc: Add style guide docs for open source contributors ([#2626](https://github.com/facebook/zstd/pull/2626), [@Cyan4973](https://github.com/Cyan4973))
- tests: Better regression test coverage for different dictionary modes ([#2559](https://github.com/facebook/zstd/pull/2559), [@senhuang42](https://github.com/senhuang42))
- tests: Better test coverage of index reduction ([#2603](https://github.com/facebook/zstd/pull/2603), [@terrelln](https://github.com/terrelln))
- tests: OSS-Fuzz coverage for seekable format ([#2617](https://github.com/facebook/zstd/pull/2617), [@senhuang42](https://github.com/senhuang42))
- tests: Test coverage for ZSTD threadpool API ([#2604](https://github.com/facebook/zstd/pull/2604), [@senhuang42](https://github.com/senhuang42))
- build: Dynamic library built multithreaded by default ([#2584](https://github.com/facebook/zstd/pull/2584), [@senhuang42](https://github.com/senhuang42))
- build: Move `zstd_errors.h` and `zdict.h` to `lib/` root ([#2597](https://github.com/facebook/zstd/pull/2597), [@terrelln](https://github.com/terrelln))
- build: Single file library build script moved to `build/` directory ([#2618](https://github.com/facebook/zstd/pull/2618), [@felixhandte](https://github.com/felixhandte))
- build: Allow `ZSTDMT_JOBSIZE_MIN` to be configured at compile-time, reduce default to 512KB ([#2611](https://github.com/facebook/zstd/pull/2611), [@Cyan4973](https://github.com/Cyan4973))
- build: Fixed Meson build ([#2548](https://github.com/facebook/zstd/pull/2548), [@SupervisedThinking](https://github.com/SupervisedThinking) & [@kloczek](https://github.com/kloczek))
- build: `ZBUFF_*()` is no longer built by default ([#2583](https://github.com/facebook/zstd/pull/2583), [@senhuang42](https://github.com/senhuang42))
- build: Fix excessive compiler warnings with clang-cl and CMake ([#2600](https://github.com/facebook/zstd/pull/2600), [@nickhutchinson](https://github.com/nickhutchinson))
- build: Detect presence of `md5` on Darwin ([#2609](https://github.com/facebook/zstd/pull/2609), [@felixhandte](https://github.com/felixhandte))
- build: Avoid SIGBUS on armv6 ([#2633](https://github.com/facebook/zstd/pull/2633), @bmwiedmann)
- cli: `--progress` flag added to always display progress bar ([#2595](https://github.com/facebook/zstd/pull/2595), [@senhuang42](https://github.com/senhuang42))
- cli: Allow reading from block devices with `--force` ([#2613](https://github.com/facebook/zstd/pull/2613), [@felixhandte](https://github.com/felixhandte))
- cli: Fix CLI filesize display bug ([#2550](https://github.com/facebook/zstd/pull/2550), [@Cyan4973](https://github.com/Cyan4973))
- cli: Fix windows CLI `--filelist` end-of-line bug ([#2620](https://github.com/facebook/zstd/pull/2620), [@Cyan4973](https://github.com/Cyan4973))
- contrib: Various fixes for linux kernel patch ([#2539](https://github.com/facebook/zstd/pull/2539), [@terrelln](https://github.com/terrelln))
- contrib: Seekable format - Decompression hanging edge case fix ([#2516](https://github.com/facebook/zstd/pull/2516), [@senhuang42](https://github.com/senhuang42))
- contrib: Seekable format - New seek table-only API ([#2113](https://github.com/facebook/zstd/pull/2113) [#2518](https://github.com/facebook/zstd/pull/2518), [@mdittmer](https://github.com/mdittmer) [@Cyan4973](https://github.com/Cyan4973))
- contrib: Seekable format - Fix seek table descriptor check when loading ([#2534](https://github.com/facebook/zstd/pull/2534), [@foxeng](https://github.com/foxeng))
- contrib: Seekable format - Decompression fix for large offsets, ([#2594](https://github.com/facebook/zstd/pull/2594), [@azat](https://github.com/azat))
- misc: Automatically published release tarballs available on Github ([#2535](https://github.com/facebook/zstd/pull/2535), [@felixhandte](https://github.com/felixhandte))
2021-05-14T16:01:54+00:00zstd v1.5.1zstd v1.5.12021-12-21T00:42:34+00:00__Notice__ : it has been brought to our attention that the `v1.5.1` library might be built with an executable stack on non-`x64` architectures, which could end up being flagged as problematic by some systems with thorough security settings which disallow executable stack. We are currently reviewing the issue. Be aware of it if you build `libzstd` for non-`x64` architecture.
Zstandard v1.5.1 is a maintenance release, bringing a good number of small refinements to the project. It also offers a welcome crop of performance improvements, as detailed below.
## Performance Improvements
### Speed improvements for fast compression (levels 1–4)
PRs #2749, #2774, and #2921 refactor single-segment compression for `ZSTD_fast` and `ZSTD_dfast`, which back compression levels 1 through 4 (as well as the negative compression levels). Speedups in the ~3-5% range are observed. In addition, the compression ratio of `ZSTD_dfast` (levels 3 and 4) is slightly improved.
### Rebalanced middle compression levels
`v1.5.0` introduced major speed improvements for mid-level compression (from 5 to 12), while preserving roughly similar compression ratio. As a consequence, the speed scale became tilted towards faster speed. Unfortunately, the difference between successive levels was no longer regular, and there is a large performance gap just after the impacted range, between levels 12 and 13.
`v1.5.1` tries to rebalance parameters so that compression levels can be roughly associated to their former speed budget. Consequently, `v1.5.1` mid compression levels feature speeds closer to former `v1.4.9` (though still sensibly faster) and receive in exchange an improved compression ratio, as shown in below graph.


Note that, since middle levels only experience a rebalancing, save some special cases, no significant performance differences between versions `v1.5.0` and `v1.5.1` should be expected: levels merely occupy different positions on the same curve. The situation is a bit different for fast levels (1-4), for which `v1.5.1` delivers a small but consistent performance benefit on all platforms, as described in previous paragraph.
### Huffman Improvements
Our Huffman code was significantly revamped in this release. Both encoding and decoding speed were improved. Additionally, encoding speed for small inputs was improved even further. Speed is measured on the Silesia corpus by compressing with level 1 and extracting the literals left over after compression. Then compressing and decompressing the literals from each block. Measurements are done on an Intel i9-9900K @ 3.6 GHz.
| Compiler | Scenario | v1.5.0 Speed | v1.5.1 Speed | Delta |
|----------|-------------------------------------|--------------|--------------|--------|
| gcc-11 | Literal compression - 128KB block | 748 MB/s | 927 MB/s | +23.9% |
| clang-13 | Literal compression - 128KB block | 810 MB/s | 927 MB/s | +14.4% |
| gcc-11 | Literal compression - 4KB block | 223 MB/s | 321 MB/s | +44.0% |
| clang-13 | Literal compression - 4KB block | 224 MB/s | 310 MB/s | +38.2% |
| gcc-11 | Literal decompression - 128KB block | 1164 MB/s | 1500 MB/s | +28.8% |
| clang-13 | Literal decompression - 128KB block | 1006 MB/s | 1504 MB/s | +49.5% |
Overall impact on (de)compression speed depends on the compressibility of the data. Compression speed improves from 1-4%, and decompression speed improves from 5-15%.
PR #2722 implements the Huffman decoder in assembly for x86-64 with BMI2 enabled. We detect BMI2 support at runtime, so this speedup applies to all x86-64 builds running on CPUs that support BMI2. This improves Huffman decoding speed by about 40%, depending on the scenario. PR #2733 improves Huffman encoding speed by 10% for clang and 20% for gcc. PR #2732 drastically speeds up the `HUF_sort()` function, which speeds up Huffman tree building for compression. This is a significant speed boost for small inputs, measuring in at a 40% improvement for 4K inputs.
## Binary Size and Build Speed
`zstd` binary size grew significantly in `v1.5.0` due to the new code added for middle compression level speed optimizations. In this release we recover the binary size, and in the process also significantly speed up builds, especially with sanitizers enabled.
Measured on x86-64 compiled with `-O3` we measure `libzstd.a` size. We regained 161 KB of binary size on gcc, and 293 KB of binary size on clang. Note that these binary sizes are listed for the whole library, optimized for speed over size. The decoder only, with size saving options enabled, and compiled with `-Os` or `-Oz` can be much smaller.
| Version | gcc-11 size | clang-13 size |
|---------|-------------|---------------|
| v1.5.1 | 1177 KB | 1167 KB |
| v1.5.0 | 1338 KB | 1460 KB |
| v1.4.9 | 1137 KB | 1151 KB |
## Change log
### Featured user-visible changes
- perf: rebalanced compression levels, to better match intended speed/level curve, by @senhuang42 and @cyan4973
- perf: faster huffman decoder, using `x64` assembly, by @terrelln
- perf: slightly faster high speed modes (strategies fast & dfast), by @felixhandte
- perf: smaller binary size and faster compilation times, by @terrelln and @nolange
- perf: new row64 mode, used notably at highest `lazy2` levels 11-12, by @senhuang42
- perf: faster mid-level compression speed in presence of highly repetitive patterns, by @senhuang42
- perf: minor compression ratio improvements for small data at high levels, by @cyan4973
- perf: reduced stack usage (mostly useful for Linux Kernel), by @terrelln
- perf: faster compression speed on incompressible data, by @bindhvo
- perf: on-demand reduced `ZSTD_DCtx` state size, using build macro `ZSTD_DECODER_INTERNAL_BUFFER`, at a small cost of performance, by @bindhvo
- build: allows hiding static symbols in the dynamic library, using build macro, by @skitt
- build: support for `m68k` (Motorola 68000's), by @cyan4973
- build: improved `AIX` support, by @Helflym
- build: improved meson unofficial build, by @eli-schwartz
- cli : fix : forward `mtime` to output file, by @felixhandte
- cli : custom memory limit when training dictionary (#2925), by @embg
- cli : report advanced parameters information when compressing in very verbose mode (`-vv`), by @Svetlitski-FB
- cli : advanced commands in the form `--long-param=` can accept negative value arguments, by @binhdvo
### PR full list
* Add determinism fuzzers and fix rare determinism bugs by @terrelln in https://github.com/facebook/zstd/pull/2648
* `ZSTD_VecMask_next`: fix incorrect variable name in fallback code path by @dnelson-1901 in https://github.com/facebook/zstd/pull/2657
* improve tar compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/2660
* Enable SSE2 compression path to work on MSVC by @TrianglesPCT in https://github.com/facebook/zstd/pull/2653
* Fix CircleCI Config to Fully Remove `publish-github-release` Job by @felixhandte in https://github.com/facebook/zstd/pull/2649
* [CI] Fix zlib-wrapper test by @senhuang42 in https://github.com/facebook/zstd/pull/2668
* [CI] Add ARM tests back into CI by @senhuang42 in https://github.com/facebook/zstd/pull/2667
* [trace] Refine the ZSTD_HAVE_WEAK_SYMBOLS detection by @terrelln in https://github.com/facebook/zstd/pull/2674
* [CI][1/2] Re-do the github actions workflows, migrate various travis and appveyor tests. by @senhuang42 in https://github.com/facebook/zstd/pull/2675
* Make GH Actions CI tests run apt-get update before apt-get install by @senhuang42 in https://github.com/facebook/zstd/pull/2682
* Add arm64 fuzz test to travis by @senhuang42 in https://github.com/facebook/zstd/pull/2686
* Add ldm and block splitter auto-enable to old api by @senhuang42 in https://github.com/facebook/zstd/pull/2684
* Add documentation for --patch-from by @binhdvo in https://github.com/facebook/zstd/pull/2693
* Make regression test run on every PR by @senhuang42 in https://github.com/facebook/zstd/pull/2691
* Initialize "potentially uninitialized" pointers. by @wolfpld in https://github.com/facebook/zstd/pull/2654
* Flatten `ZSTD_row_getMatchMask` by @aqrit in https://github.com/facebook/zstd/pull/2681
* Update `README` for Travis CI Badge by @gauthamkrishna9991 in https://github.com/facebook/zstd/pull/2700
* Fuzzer test with no intrinsics on `S390x` (big endian) by @senhuang42 in https://github.com/facebook/zstd/pull/2678
* Fix `--progress` flag to properly control progress display and default … by @binhdvo in https://github.com/facebook/zstd/pull/2698
* [bug] Fix entropy repeat mode bug by @senhuang42 in https://github.com/facebook/zstd/pull/2697
* Format File Sizes Human-Readable in the cli by @felixhandte in https://github.com/facebook/zstd/pull/2702
* Add support for negative values in advanced flags by @binhdvo in https://github.com/facebook/zstd/pull/2705
* [fix] Add missing bounds checks during compression by @terrelln in https://github.com/facebook/zstd/pull/2709
* Add API for fetching skippable frame content by @binhdvo in https://github.com/facebook/zstd/pull/2708
* Add option to use logical cores for default threads by @binhdvo in https://github.com/facebook/zstd/pull/2710
* lib/Makefile: Fix small typo in `ZSTD_FORCE_DECOMPRESS_*` build macros by @luisdallos in https://github.com/facebook/zstd/pull/2714
* [RFC] Add internal API for converting `ZSTD_Sequence` into `seqStore` by @senhuang42 in https://github.com/facebook/zstd/pull/2715
* Optimize zstd decompression by another x% by @danlark1 in https://github.com/facebook/zstd/pull/2689
* Include what you use in `zstd_ldm_geartab` by @danlark1 in https://github.com/facebook/zstd/pull/2719
* [trace] remove zstd_trace.c reference from freestanding by @heitbaum in https://github.com/facebook/zstd/pull/2655
* Remove folder when done with test by @senhuang42 in https://github.com/facebook/zstd/pull/2720
* Proactively skip huffman compression based on sampling where non-comp… by @binhdvo in https://github.com/facebook/zstd/pull/2717
* Add support for MCST LCC compiler by @makise-homura in https://github.com/facebook/zstd/pull/2725
* [bug-fix] Fix a determinism bug with the DUBT by @terrelln in https://github.com/facebook/zstd/pull/2726
* Fix DDSS Load by @felixhandte in https://github.com/facebook/zstd/pull/2729
* `Z_PREFIX zError` function by @koalabearguo in https://github.com/facebook/zstd/pull/2707
* `pzstd`: fix linking for static builds by @jonringer in https://github.com/facebook/zstd/pull/2724
* [HUF] Improve Huffman encoding speed by @terrelln in https://github.com/facebook/zstd/pull/2733
* [HUF] Improve Huffman sorting algorithm by @senhuang42 in https://github.com/facebook/zstd/pull/2732
* Set `mtime` on Output Files by @felixhandte in https://github.com/facebook/zstd/pull/2742
* [RFC] Rebalance compression levels by @senhuang42 in https://github.com/facebook/zstd/pull/2692
* Improve branch misses on FSE symbol spreading by @senhuang42 in https://github.com/facebook/zstd/pull/2750
* make `ZSTD_HASHLOG3_MAX` private by @Cyan4973 in https://github.com/facebook/zstd/pull/2752
* meson fixups by @eli-schwartz in https://github.com/facebook/zstd/pull/2746
* [easy] Fix zstd bench error message by @senhuang42 in https://github.com/facebook/zstd/pull/2753
* Reduce test time on TravisCI by @Cyan4973 in https://github.com/facebook/zstd/pull/2757
* added `qemu` tests by @Cyan4973 in https://github.com/facebook/zstd/pull/2758
* Add 8 bytes to FSE_buildCTable wksp by @senhuang42 in https://github.com/facebook/zstd/pull/2761
* minor rebalancing of level 13 by @Cyan4973 in https://github.com/facebook/zstd/pull/2762
* Improve compile speed and binary size in `opt` by @senhuang42 in https://github.com/facebook/zstd/pull/2763
* [easy] Fix patch-from help msg typo by @senhuang42 in https://github.com/facebook/zstd/pull/2769
* Pipelined Implementation of `ZSTD_fast` (~+5% Speed) by @felixhandte in https://github.com/facebook/zstd/pull/2749
* meson: fix type error for integer option by @eli-schwartz in https://github.com/facebook/zstd/pull/2775
* Fix dictionary training huffman segfault and small speed improvement by @senhuang42 in https://github.com/facebook/zstd/pull/2773
* [rsyncable] Ensure `ZSTD_compressBound()` is respected by @terrelln in https://github.com/facebook/zstd/pull/2776
* Improve optimal parser performance on small data by @Cyan4973 in https://github.com/facebook/zstd/pull/2771
* [rsyncable] Fix test failures by @terrelln in https://github.com/facebook/zstd/pull/2777
* Revert opt outlining change by @senhuang42 in https://github.com/facebook/zstd/pull/2778
* [build] Add support for ASM files in `Make` + `CMake` by @terrelln in https://github.com/facebook/zstd/pull/2783
* add `msvc2019` to build.generic.cmd by @animalize in https://github.com/facebook/zstd/pull/2787
* [fuzzer] Add Huffman decompression fuzzer by @terrelln in https://github.com/facebook/zstd/pull/2784
* Assembly implementation of 4X1 & 4X2 Huffman by @terrelln in https://github.com/facebook/zstd/pull/2722
* [huf] Fix compilation when `DYNAMIC_BMI2=0 && BMI2` is supported by @terrelln in https://github.com/facebook/zstd/pull/2791
* Use new paramSwitch enum for row matchfinder and block splitter by @senhuang42 in https://github.com/facebook/zstd/pull/2788
* Fix `NCountWriteBound` by @senhuang42 in https://github.com/facebook/zstd/pull/2779
* [contrib][linux] Fix up SPDX license identifiers by @terrelln in https://github.com/facebook/zstd/pull/2794
* [contrib][linux] Reduce stack usage by 80 bytes by @terrelln in https://github.com/facebook/zstd/pull/2795
* Reduce stack usage of block splitter by @senhuang42 in https://github.com/facebook/zstd/pull/2780
* minor: constify `MatchState*` parameter when possible by @Cyan4973 in https://github.com/facebook/zstd/pull/2797
* [build] Fix oss-fuzz build with the dataflow sanitizer by @terrelln in https://github.com/facebook/zstd/pull/2799
* [lib] Make lib compatible with `-Wfall-through` excepting legacy by @terrelln in https://github.com/facebook/zstd/pull/2796
* [contrib][linux] Fix build after introducing ASM HUF implementation by @solbjorn in https://github.com/facebook/zstd/pull/2790
* Smaller code with disabled features by @nolange in https://github.com/facebook/zstd/pull/2805
* [huf] Fix OSS-Fuzz assert by @terrelln in https://github.com/facebook/zstd/pull/2808
* Skip most long matches in lazy hash table update by @senhuang42 in https://github.com/facebook/zstd/pull/2755
* add missing BUNDLE DESTINATION by @3nids in https://github.com/facebook/zstd/pull/2810
* [contrib][linux] Fix `-Wundef` inside Linux kernel tree by @solbjorn in https://github.com/facebook/zstd/pull/2802
* [contrib][linux-kernel] Add standard warnings and `-Werror` to CI by @terrelln in https://github.com/facebook/zstd/pull/2803
* Add AIX support in Makefile by @Helflym in https://github.com/facebook/zstd/pull/2747
* Limit train samples by @stanjo74 in https://github.com/facebook/zstd/pull/2809
* [multiple-ddicts] Fix `NULL` checks by @terrelln in https://github.com/facebook/zstd/pull/2817
* [ldm] Fix `ZSTD_c_ldmHashRateLog` bounds check by @terrelln in https://github.com/facebook/zstd/pull/2819
* [binary-tree] Fix underflow of `nbCompares` by @terrelln in https://github.com/facebook/zstd/pull/2820
* Enhance streaming_compression examples. by @marxin in https://github.com/facebook/zstd/pull/2813
* Pipelined Implementation of `ZSTD_dfast` by @felixhandte in https://github.com/facebook/zstd/pull/2774
* Fix a C89 error in msvc by @animalize in https://github.com/facebook/zstd/pull/2800
* [asm] Switch to C style comments by @terrelln in https://github.com/facebook/zstd/pull/2825
* Support thread pool section in HTML documentation. by @marxin in https://github.com/facebook/zstd/pull/2822
* Reduce size of `dctx` by reutilizing dst buffer by @binhdvo in https://github.com/facebook/zstd/pull/2751
* [lazy] Speed up compilation times by @terrelln in https://github.com/facebook/zstd/pull/2828
* separate compression level tables into their own file by @Cyan4973 in https://github.com/facebook/zstd/pull/2830
* minor : change build macro to `ZSTD_DECODER_INTERNAL_BUFFER` by @Cyan4973 in https://github.com/facebook/zstd/pull/2829
* Fix oss fuzz test error by @binhdvo in https://github.com/facebook/zstd/pull/2837
* Move mingw tests from appveyor to github actions by @binhdvo in https://github.com/facebook/zstd/pull/2838
* Improvements to verbose mode output by @Svetlitski-FB in https://github.com/facebook/zstd/pull/2839
* Use unused functions to appease Visual Studio by @senhuang42 in https://github.com/facebook/zstd/pull/2846
* Backport zstd patch from LKML by @terrelln in https://github.com/facebook/zstd/pull/2849
* Fix fullbench CI failure by @binhdvo in https://github.com/facebook/zstd/pull/2851
* Fix Determinism Bug: Avoid Reducing Indices to Reserved Values by @felixhandte in https://github.com/facebook/zstd/pull/2850
* `ZSTD_copy16()` uses ZSTD_memcpy() by @animalize in https://github.com/facebook/zstd/pull/2836
* Display command line parameters with concrete values in verbose mode by @Svetlitski-FB in https://github.com/facebook/zstd/pull/2847
* Reduce function size in fast & dfast by @terrelln in https://github.com/facebook/zstd/pull/2863
* [linux-kernel] Don't inline function in `zstd_opt.c` by @terrelln in https://github.com/facebook/zstd/pull/2864
* Remove executable flag from GNU_STACK segment by @ko-zu in https://github.com/facebook/zstd/pull/2857
* [linux-kernel] Don't add `-O3` to `CFLAGS` by @terrelln in https://github.com/facebook/zstd/pull/2866
* Support Swift Package Manager by @cntrump in https://github.com/facebook/zstd/pull/2858
* Determinism: Avoid Mapping Window into Reserved Indices during Reduction by @felixhandte in https://github.com/facebook/zstd/pull/2869
* Clarify documentation for `-c` by @binhdvo in https://github.com/facebook/zstd/pull/2883
* Fix build for cygwin/bsd by @binhdvo in https://github.com/facebook/zstd/pull/2882
* Move visual studio tests from per-release to per-PR by @senhuang42 in https://github.com/facebook/zstd/pull/2845
* Fix SPM warning: umbrella header for module 'libzstd' does not include header 'xxx.h' by @cntrump in https://github.com/facebook/zstd/pull/2872
* Add detection when compiling with Clang and Ninja under Windows by @jannkoeker in https://github.com/facebook/zstd/pull/2877
* [contrib][pzstd] Fix build issue with gcc-5 by @terrelln in https://github.com/facebook/zstd/pull/2889
* [bmi2] Add `lzcnt` and `bmi` target attributes by @terrelln in https://github.com/facebook/zstd/pull/2888
* [test] Test that the exec-stack bit isn't set on libzstd.so by @terrelln in https://github.com/facebook/zstd/pull/2886
* Solve the bug of extra output newline character by @15596858998 in https://github.com/facebook/zstd/pull/2876
* [zdict] Remove `ZDICT_CONTENTSIZE_MIN` restriction for `ZDICT_finalizeDictionary` by @terrelln in https://github.com/facebook/zstd/pull/2887
* Explicitly hide static symbols by @skitt in https://github.com/facebook/zstd/pull/2501
* Makefile: sort all wildcard file list expansions by @kanavin in https://github.com/facebook/zstd/pull/2895
* merge #2501 by @Cyan4973 in https://github.com/facebook/zstd/pull/2894
* Makefile: fix build for mingw by @sapiippo in https://github.com/facebook/zstd/pull/2687
* [CircleCI] Fix short-tests-0 by @terrelln in https://github.com/facebook/zstd/pull/2892
* Zstandard compiles and run on `m68k` cpus by @Cyan4973 in https://github.com/facebook/zstd/pull/2896
* Improve zstd_opt build speed and size by @terrelln in https://github.com/facebook/zstd/pull/2898
* [CI] Add `cmake` windows build by @terrelln in https://github.com/facebook/zstd/pull/2900
* Disable Multithreading in CMake Builds for Android by @felixhandte in https://github.com/facebook/zstd/pull/2899
* Avoid Using Deprecated Functions in Deprecated Code by @felixhandte in https://github.com/facebook/zstd/pull/2897
* [asm] Share portability macros and restrict ASM further by @terrelln in https://github.com/facebook/zstd/pull/2893
* fixbug CLI's -D fails when the argument is not a regular file by @15596858998 in https://github.com/facebook/zstd/pull/2890
* Apply `FORCE_MEMORY_ACCESS=1` to legacy by @Hello71 in https://github.com/facebook/zstd/pull/2907
* [lib] Fix libzstd.pc for lib-mt builds by @ericonr in https://github.com/facebook/zstd/pull/2659
* Imply `-q` when stderr is not a tty by @binhdvo in https://github.com/facebook/zstd/pull/2884
* Fix Up #2659; Build `libzstd.pc` Whenever Building the Lib on Unix by @felixhandte in https://github.com/facebook/zstd/pull/2912
* Remove possible `NULL` pointer addition by @terrelln in https://github.com/facebook/zstd/pull/2916
* updated `xxHash` to latest `v0.8.1` by @Cyan4973 in https://github.com/facebook/zstd/pull/2914
* Reject Irregular Dictionary Files by @felixhandte in https://github.com/facebook/zstd/pull/2910
* `x32` compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/2922
* typo: Small spelling mistake in example by @IAL32 in https://github.com/facebook/zstd/pull/2923
* add test case by @15596858998 in https://github.com/facebook/zstd/pull/2905
* Stagger Stepping in Negative Levels by @felixhandte in https://github.com/facebook/zstd/pull/2921
* Fix performance degradation with `-m32` by @binhdvo in https://github.com/facebook/zstd/pull/2926
* Reduce tables to 8bit by @nolange in https://github.com/facebook/zstd/pull/2930
* simplify SSE implementation of row_lazy match finder by @Cyan4973 in https://github.com/facebook/zstd/pull/2929
* Allow user to specify memory limit for dictionary training by @embg in https://github.com/facebook/zstd/pull/2925
* fixed incorrect rowlog initialization by @Cyan4973 in https://github.com/facebook/zstd/pull/2931
* rebalance lazy compression levels by @Cyan4973 in https://github.com/facebook/zstd/pull/2934
### New Contributors
* @dnelson-1901 made their first contribution in https://github.com/facebook/zstd/pull/2657
* @TrianglesPCT made their first contribution in https://github.com/facebook/zstd/pull/2653
* @binhdvo made their first contribution in https://github.com/facebook/zstd/pull/2693
* @wolfpld made their first contribution in https://github.com/facebook/zstd/pull/2654
* @aqrit made their first contribution in https://github.com/facebook/zstd/pull/2681
* @gauthamkrishna9991 made their first contribution in https://github.com/facebook/zstd/pull/2700
* @luisdallos made their first contribution in https://github.com/facebook/zstd/pull/2714
* @danlark1 made their first contribution in https://github.com/facebook/zstd/pull/2689
* @heitbaum made their first contribution in https://github.com/facebook/zstd/pull/2655
* @makise-homura made their first contribution in https://github.com/facebook/zstd/pull/2725
* @koalabearguo made their first contribution in https://github.com/facebook/zstd/pull/2707
* @jonringer made their first contribution in https://github.com/facebook/zstd/pull/2724
* @eli-schwartz made their first contribution in https://github.com/facebook/zstd/pull/2746
* @abxhr made their first contribution in https://github.com/facebook/zstd/pull/2798
* @solbjorn made their first contribution in https://github.com/facebook/zstd/pull/2790
* @nolange made their first contribution in https://github.com/facebook/zstd/pull/2805
* @3nids made their first contribution in https://github.com/facebook/zstd/pull/2810
* @Helflym made their first contribution in https://github.com/facebook/zstd/pull/2747
* @stanjo74 made their first contribution in https://github.com/facebook/zstd/pull/2809
* @Svetlitski-FB made their first contribution in https://github.com/facebook/zstd/pull/2839
* @cntrump made their first contribution in https://github.com/facebook/zstd/pull/2858
* @rex4539 made their first contribution in https://github.com/facebook/zstd/pull/2856
* @jannkoeker made their first contribution in https://github.com/facebook/zstd/pull/2877
* @yoniko made their first contribution in https://github.com/facebook/zstd/pull/2885
* @15596858998 made their first contribution in https://github.com/facebook/zstd/pull/2876
* @kanavin made their first contribution in https://github.com/facebook/zstd/pull/2895
* @sapiippo made their first contribution in https://github.com/facebook/zstd/pull/2687
* @supperPants made their first contribution in https://github.com/facebook/zstd/pull/2891
* @Hello71 made their first contribution in https://github.com/facebook/zstd/pull/2907
* @ericonr made their first contribution in https://github.com/facebook/zstd/pull/2659
* @IAL32 made their first contribution in https://github.com/facebook/zstd/pull/2923
* @embg made their first contribution in https://github.com/facebook/zstd/pull/2925
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.0...v1.5.12021-12-21T00:42:34+00:00zstd v1.5.2zstd v1.5.22022-01-20T21:54:37+00:00Zstandard v1.5.2 is a bug-fix release, addressing issues that were raised with the v1.5.1 release.
In particular, as a side-effect of the inclusion of assembly code in our source tree, binary artifacts were being marked as needing an executable stack on non-amd64 architectures. This release corrects that issue. More context is available in #2963.
This release also corrects a performance regression that was introduced in v1.5.0 that slows down compression of very small data when using the streaming API. Issue #2966 tracks that topic.
In addition there are a number of smaller improvements and fixes.
## Full Changelist
* Fix zstd-static output name with MINGW/Clang by @MehdiChinoune in https://github.com/facebook/zstd/pull/2947
* storeSeq & mlBase : clarity refactoring by @Cyan4973 in https://github.com/facebook/zstd/pull/2954
* Fix mini typo by @fwessels in https://github.com/facebook/zstd/pull/2960
* Refactor offset+repcode sumtype by @Cyan4973 in https://github.com/facebook/zstd/pull/2962
* meson: fix MSVC support by @eli-schwartz in https://github.com/facebook/zstd/pull/2951
* fix performance issue in scenario #2966 (part 1) by @Cyan4973 in https://github.com/facebook/zstd/pull/2969
* [meson] Explicitly disable assembly for non clang/gcc copmilers by @terrelln in https://github.com/facebook/zstd/pull/2972
* Mark Huffman Decoder Assembly `noexecstack` on All Architectures by @felixhandte in https://github.com/facebook/zstd/pull/2964
* Improve Module Map File by @felixhandte in https://github.com/facebook/zstd/pull/2953
* Remove Dependencies to Allow the Zstd Binary to Dynamically Link to the Library by @felixhandte in https://github.com/facebook/zstd/pull/2977
* [opt] Fix oss-fuzz bug in optimal parser by @terrelln in https://github.com/facebook/zstd/pull/2980
* [license] Fix license header of huf_decompress_amd64.S by @terrelln in https://github.com/facebook/zstd/pull/2981
* Fix `stderr` progress logging for decompression by @terrelln in https://github.com/facebook/zstd/pull/2982
* Fix tar test cases by @sunwire in https://github.com/facebook/zstd/pull/2956
* Fixup MSVC source file inclusion for cmake builds by @hmaarrfk in https://github.com/facebook/zstd/pull/2957
* x86-64: Hide internal assembly functions by @hjl-tools in https://github.com/facebook/zstd/pull/2993
* Prepare v1.5.2 by @felixhandte in https://github.com/facebook/zstd/pull/2987
* Documentation and minor refactor to clarify MT memory management by @embg in https://github.com/facebook/zstd/pull/3000
* Avoid updating timestamps when the destination is `stdout` by @floppym in https://github.com/facebook/zstd/pull/2998
* [build][asm] Pass ASFLAGS to the assembler instead of CFLAGS by @terrelln in https://github.com/facebook/zstd/pull/3009
* Update CI documentation by @embg in https://github.com/facebook/zstd/pull/2999
## New Contributors
* @MehdiChinoune made their first contribution in https://github.com/facebook/zstd/pull/2947
* @fwessels made their first contribution in https://github.com/facebook/zstd/pull/2960
* @sunwire made their first contribution in https://github.com/facebook/zstd/pull/2956
* @hmaarrfk made their first contribution in https://github.com/facebook/zstd/pull/2957
* @floppym made their first contribution in https://github.com/facebook/zstd/pull/2998
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.1...v1.5.22022-01-20T21:54:37+00:00zstd v1.5.4zstd v1.5.42023-02-10T00:55:48+00:00Zstandard `v1.5.4` is a pretty big release benefiting from one year of work, spread over > 650 commits. It offers significant performance improvements across multiple scenarios, as well as new features (detailed below). There is a crop of little bug fixes too, a few ones targeting the 32-bit mode are important enough to make this release a recommended upgrade.
### Various Speed improvements
This release has accumulated a number of scenario-specific improvements, that cumulatively benefit a good portion of installed base in one way or another.
Among the easier ones to describe, the repository has received several contributions for `arm` optimizations, notably from @JunHe77 and @danlark1. And @terrelln has improved decompression speed for non-x64 systems, including `arm`. The combination of this work is visible in the following example, using an M1-Pro (`aarch64` architecture) :
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| M1 Pro | decompress | `silesia.tar` | 1370 MB/s | 1480 MB/s | + 8% |
| Galaxy S22 | decompress | `silesia.tar` | 1150 MB/s | 1200 MB/s | + 4% |
Middle compression levels (5-12) receive some care too, with @terrelln improving the dispatch engine, and @danlark1 offering `NEON` optimizations. Exact speed up vary depending on platform, cpu, compiler, and compression level, though one can expect gains ranging from +1 to +10% depending on scenarios.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | ---:| ---:| --- |
| i7-9700k | compress -6 | `silesia.tar` | 110 MB/s | 121 MB/s | +10%
| Galaxy S22 | compress -6 | `silesia.tar` | 98 MB/s | 103 MB/s | +5%
| M1 Pro | compress -6 | `silesia.tar` | 122 MB/s | 130 MB/s | +6.5%
| i7-9700k | compress -9 | `silesia.tar` | 64 MB/s | 70 MB/s | +9.5%
| Galaxy S22 | compress -9 | `silesia.tar` | 51 MB/s | 52 MB/s | +1%
| M1 Pro | compress -9 | `silesia.tar` | 77 MB/s | 86 MB/s | +11.5%
| i7-9700k | compress -12 | `silesia.tar` | 31.6 MB/s | 31.8 MB/s | +0.5%
| Galaxy S22 | compress -12 | `silesia.tar` | 20.9 MB/s | 22.1 MB/s | +5%
| M1 Pro | compress -12 | `silesia.tar` | 36.1 MB/s | 39.7 MB/s | +10%
Speed of the streaming compression interface has been improved by @embg in scenarios involving large files (where size is a multiple of the `windowSize` parameter). The improvement is mostly perceptible at high speeds (i.e. ~level 1). In the following sample, the measurement is taken directly at `ZSTD_compressStream()` function call, using a dedicated benchmark tool `tests/fullbench`.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| i7-9700k | `ZSTD_compressStream()` -1 | `silesia.tar` | 392 MB/s | 429 MB/s | +9.5% |
| Galaxy S22 | `ZSTD_compressStream()` -1 | `silesia.tar` | 380 MB/s | 430 MB/s | +13% |
| M1 Pro | `ZSTD_compressStream()` -1 | `silesia.tar` | 476 MB/s | 539 MB/s | +13% |
Finally, dictionary compression speed has received a good boost by @embg. Exact outcome varies depending on system and corpus. The following result is achieved by cutting the `enwik8` compression corpus into 1KB blocks, generating a dictionary from these blocks, and then benchmarking the compression speed at level 1.
| cpu | function | corpus | `v1.5.2` | `v1.5.4` | Improvement |
| --- | --- | --- | --- | --- | --- |
| i7-9700k | dictionary compress | `enwik8` -B1K | 125 MB/s | 165 MB/s | +32% |
| Galaxy S22 | dictionary compress | `enwik8` -B1K | 138 MB/s | 166 MB/s | +20% |
| M1 Pro | dictionary compress | `enwik8` -B1K | 155 MB/s | 195 MB/s | +25 % |
There are a few more scenario-specifics improvements listed in the `changelog` section below.
### I/O Performance improvements
The 1.5.4 release improves IO performance of `zstd` CLI, by using system buffers (`macos`) and adding a new asynchronous I/O capability, enabled by default on large files (when threading is available). The user can also explicitly control this capability with the `--[no-]asyncio` flag . These new threads remove the need to block on IO operations. The impact is mostly noticeable when decompressing large files (>= a few MBs), though exact outcome depends on environment and run conditions.
Decompression speed gets significant gains due to its single-threaded serial nature and the high speeds involved. In some cases we observe up to double performance improvement (local Mac machines) and a wide +15-45% benefit on Intel Linux servers (see table for details).
On the compression side of things, we’ve measured up to 5% improvements. The impact is lower because compression is already partially asynchronous via the internal MT mode (see release [v1.3.4](https://github.com/facebook/zstd/releases/tag/v1.3.4)).
The following table shows the elapsed run time for decompressions of `silesia` and `enwik8` on several platforms - some Skylake-era Linux servers and an M1 MacbookPro. It compares the time it takes for version `v1.5.2` to version `v1.5.4` with asyncio on and off.
platform | corpus | `v1.5.2` | `v1.5.4-no-asyncio` | `v1.5.4` | Improvement
-- | -- | -- | -- | -- | --
Xeon D-2191A CentOS8 | `enwik8` | 280 MB/s | 280 MB/s | 324 MB/s | +16%
Xeon D-2191A CentOS8 | `silesia.tar` | 303 MB/s | 302 MB/s | 386 MB/s | +27%
i7-1165g7 win10 | `enwik8` | 270 MB/s | 280 MB/s | 350 MB/s | +27%
i7-1165g7 win10 | `silesia.tar` | 450 MB/s | 440 MB/s | 580 MB/s | +28%
i7-9700K Ubuntu20 | `enwik8` | 600 MB/s | 604 MB/s | 829 MB/s | +38%
i7-9700K Ubuntu20 | `silesia.tar` | 683 MB/s | 678 MB/s | 991 MB/s | +45%
Galaxy S22 | `enwik8` | 360 MB/s | 420 MB/s | 515 MB/s | +70%
Galaxy S22 | `silesia.tar` | 310 MB/s | 320 MB/s | 580 MB/s | +85%
MBP M1 | `enwik8` | 428 MB/s | 734 MB/s | 815 MB/s | +90%
MBP M1 | `silesia.tar` | 465 MB/s | 875 MB/s | 1001 MB/s | +115%
### Support of externally-defined sequence producers
`libzstd` can now support external sequence producers via a new advanced registration function `ZSTD_registerSequenceProducer()` (#3333).
This API allows users to provide their own custom sequence producer which libzstd invokes to process each block. The produced list of sequences (literals and matches) is then post-processed by libzstd to produce valid compressed blocks.
This block-level offload API is a more granular complement of the existing frame-level offload API `compressSequences()` (introduced in `v1.5.1`). It offers an easier migration story for applications already integrated with `libzstd`: the user application continues to invoke the same compression functions `ZSTD_compress2()` or `ZSTD_compressStream2()` as usual, and transparently benefits from the specific properties of the external sequence producer. For example, the sequence producer could be tuned to take advantage of known characteristics of the input, to offer better speed / ratio.
One scenario that becomes possible is to combine this capability with hardware-accelerated matchfinders, such as the Intel® QuickAssist accelerator (Intel® QAT) provided in server CPUs such as the 4th Gen Intel® Xeon® Scalable processors (previously codenamed Sapphire Rapids). More details to be provided in future communications.
## Change Log
perf: +20% faster huffman decompression for targets that can't compile x64 assembly (#3449, @terrelln)
perf: up to +10% faster streaming compression at levels 1-2 (#3114, @embg)
perf: +4-13% for levels 5-12 by optimizing function generation (#3295, @terrelln)
pref: +3-11% compression speed for `arm` target (#3199, #3164, #3145, #3141, #3138, @JunHe77 and #3139, #3160, @danlark1)
perf: +5-30% faster dictionary compression at levels 1-4 (#3086, #3114, #3152, @embg)
perf: +10-20% cold dict compression speed by prefetching CDict tables (#3177, @embg)
perf: +1% faster compression by removing a branch in ZSTD_fast_noDict (#3129, @felixhandte)
perf: Small compression ratio improvements in high compression mode (#2983, #3391, @Cyan4973 and #3285, #3302, @daniellerozenblit)
perf: small speed improvement by better detecting `STATIC_BMI2` for `clang` (#3080, @TocarIP)
perf: Improved streaming performance when `ZSTD_c_stableInBuffer` is set (#2974, @Cyan4973)
cli: Asynchronous I/O for improved cli speed (#2975, #2985, #3021, #3022, @yoniko)
cli: Change `zstdless` behavior to align with `zless` (#2909, @binhdvo)
cli: Keep original file if `-c` or `--stdout` is given (#3052, @dirkmueller)
cli: Keep original files when result is concatenated into a single output with `-o` (#3450, @Cyan4973)
cli: Preserve Permissions and Ownership of regular files (#3432, @felixhandte)
cli: Print zlib/lz4/lzma library versions with `-vv` (#3030, @terrelln)
cli: Print checksum value for single frame files with `-lv` (#3332, @Cyan4973)
cli: Print `dictID` when present with `-lv` (#3184, @htnhan)
cli: when `stderr` is *not* the console, disable status updates, but preserve final summary (#3458, @Cyan4973)
cli: support `--best` and `--no-name` in `gzip` compatibility mode (#3059, @dirkmueller)
cli: support for `posix` high resolution timer `clock_gettime()`, for improved benchmark accuracy (#3423, @Cyan4973)
cli: improved help/usage (`-h`, `-H`) formatting (#3094, @dirkmueller and #3385, @jonpalmisc)
cli: Fix better handling of bogus numeric values (#3268, @ctkhanhly)
cli: Fix input consists of multiple files _and_ `stdin` (#3222, @yoniko)
cli: Fix tiny files passthrough (#3215, @cgbur)
cli: Fix for `-r` on empty directory (#3027, @brailovich)
cli: Fix empty string as argument for `--output-dir-*` (#3220, @embg)
cli: Fix decompression memory usage reported by `-vv --long` (#3042, @u1f35c, and #3232, @zengyijing)
cli: Fix infinite loop when empty input is passed to trainer (#3081, @terrelln)
cli: Fix `--adapt` doesn't work when `--no-progress` is also set (#3354, @terrelln)
api: Support for External Sequence Producer (#3333, @embg)
api: Support for in-place decompression (#3432, @terrelln)
api: New `ZSTD_CCtx_setCParams()` function, set all parameters defined in a `ZSTD_compressionParameters` structure (#3403, @Cyan4973)
api: Streaming decompression detects incorrect header ID sooner (#3175, @Cyan4973)
api: Window size resizing optimization for edge case (#3345, @daniellerozenblit)
api: More accurate error codes for busy-loop scenarios (#3413, #3455, @Cyan4973)
api: Fix limit overflow in `compressBound` and `decompressBound` (#3362, #3373, Cyan4973) reported by @nigeltao
api: Deprecate several advanced experimental functions: streaming (#3408, @embg), copy (#3196, @mileshu)
bug: Fix corruption that rarely occurs in 32-bit mode with wlog=25 (#3361, @terrelln)
bug: Fix for block-splitter (#3033, @Cyan4973)
bug: Fixes for Sequence Compression API (#3023, #3040, @Cyan4973)
bug: Fix leaking thread handles on Windows (#3147, @animalize)
bug: Fix timing issues with cmake/meson builds (#3166, #3167, #3170, @Cyan4973)
build: Allow user to select legacy level for cmake (#3050, @shadchin)
build: Enable legacy support by default in cmake (#3079, @niamster)
build: Meson build script improvements (#3039, #3120, #3122, #3327, #3357, @eli-schwartz and #3276, @neheb)
build: Add aarch64 to supported architectures for zstd_trace (#3054, @ooosssososos)
build: support AIX architecture (#3219, @qiongsiwu)
build: Fix `ZSTD_LIB_MINIFY` build macro, which now reduces static library size by half (#3366, @terrelln)
build: Fix Windows issues with Multithreading translation layer (#3364, #3380, @yoniko) and ARM64 target (#3320, @cwoffenden)
build: Fix `cmake` script (#3382, #3392, @terrelln and #3252 @Tachi107 and #3167 @Cyan4973)
doc: Updated man page, providing more details for `--train` mode (#3112, @Cyan4973)
doc: Add decompressor errata document (#3092, @terrelln)
misc: Enable Intel CET (#2992, #2994, @hjl-tools)
misc: Fix `contrib/` seekable format (#3058, @yhoogstrate and #3346, @daniellerozenblit)
misc: Improve speed of the one-file library generator (#3241, @wahern and #3005, @cwoffenden)
## PR list (generated by Github)
* x86-64: Enable Intel CET by @hjl-tools in https://github.com/facebook/zstd/pull/2992
* Add GitHub Action Checking that Zstd Runs Successfully Under CET by @felixhandte in https://github.com/facebook/zstd/pull/3015
* [opt] minor compression ratio improvement by @Cyan4973 in https://github.com/facebook/zstd/pull/2983
* Simplify HUF_decompress4X2_usingDTable_internal_bmi2_asm_loop by @WojciechMula in https://github.com/facebook/zstd/pull/3013
* Async write for decompression by @yoniko in https://github.com/facebook/zstd/pull/2975
* ZSTD CLI: Use buffered output by @yoniko in https://github.com/facebook/zstd/pull/2985
* Use faster Python script to amalgamate by @cwoffenden in https://github.com/facebook/zstd/pull/3005
* Change zstdless behavior to align with zless by @binhdvo in https://github.com/facebook/zstd/pull/2909
* AsyncIO compression part 1 - refactor of existing asyncio code by @yoniko in https://github.com/facebook/zstd/pull/3021
* Converge sumtype (offset | repcode) numeric representation towards offBase by @Cyan4973 in https://github.com/facebook/zstd/pull/2965
* fix sequence compression API in Explicit Delimiter mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3023
* Lazy parameters adaptation (part 1 - ZSTD_c_stableInBuffer) by @Cyan4973 in https://github.com/facebook/zstd/pull/2974
* Print zlib/lz4/lzma library versions in verbose version output by @terrelln in https://github.com/facebook/zstd/pull/3030
* fix for -r on empty directory by @brailovich in https://github.com/facebook/zstd/pull/3027
* Add new CLI testing platform by @terrelln in https://github.com/facebook/zstd/pull/3020
* AsyncIO compression part 2 - added async read and asyncio to compression code by @yoniko in https://github.com/facebook/zstd/pull/3022
* Macos playtest envvars fix by @yoniko in https://github.com/facebook/zstd/pull/3035
* Fix required decompression memory usage reported by -vv + --long by @u1f35c in https://github.com/facebook/zstd/pull/3042
* Select legacy level for cmake by @shadchin in https://github.com/facebook/zstd/pull/3050
* [trace] Add aarch64 to supported architectures for zstd_trace by @ooosssososos in https://github.com/facebook/zstd/pull/3054
* New features for largeNbDicts benchmark by @embg in https://github.com/facebook/zstd/pull/3063
* Use helper function for bit manipulations. by @TocarIP in https://github.com/facebook/zstd/pull/3075
* [programs] Fix infinite loop when empty input is passed to trainer by @terrelln in https://github.com/facebook/zstd/pull/3081
* Enable STATIC_BMI2 for gcc/clang by @TocarIP in https://github.com/facebook/zstd/pull/3080
* build:cmake: enable ZSTD legacy support by default by @niamster in https://github.com/facebook/zstd/pull/3079
* Implement more gzip compatibility (#3037) by @dirkmueller in https://github.com/facebook/zstd/pull/3059
* [doc] Add decompressor errata document by @terrelln in https://github.com/facebook/zstd/pull/3092
* Handle newer less versions in zstdless testing by @dirkmueller in https://github.com/facebook/zstd/pull/3093
* [contrib][linux] Fix a warning in zstd_reset_cstream() by @cyberknight777 in https://github.com/facebook/zstd/pull/3088
* Software pipeline for ZSTD_compressBlock_fast_dictMatchState (+5-6% compression speed) by @embg in https://github.com/facebook/zstd/pull/3086
* Keep original file if -c or --stdout is given by @dirkmueller in https://github.com/facebook/zstd/pull/3052
* Split help in long and short version, cleanup formatting by @dirkmueller in https://github.com/facebook/zstd/pull/3094
* updated man page, providing more details for --train mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3112
* Meson fixups for Windows by @eli-schwartz in https://github.com/facebook/zstd/pull/3039
* meson: for internal linkage, link to both libzstd and a static copy of it by @eli-schwartz in https://github.com/facebook/zstd/pull/3122
* Software pipeline for ZSTD_compressBlock_fast_extDict (+4-9% compression speed) by @embg in https://github.com/facebook/zstd/pull/3114
* ZSTD_fast_noDict: Avoid Safety Check When Writing `ip1` into Table by @felixhandte in https://github.com/facebook/zstd/pull/3129
* Correct and clarify repcode offset history logic by @embg in https://github.com/facebook/zstd/pull/3127
* [lazy] Optimize ZSTD_row_getMatchMask for levels 8-10 for ARM by @danlark1 in https://github.com/facebook/zstd/pull/3139
* fix leaking thread handles on Windows by @animalize in https://github.com/facebook/zstd/pull/3147
* Remove expensive assert in --rsyncable hot loop by @terrelln in https://github.com/facebook/zstd/pull/3154
* Bugfix for huge dictionaries by @embg in https://github.com/facebook/zstd/pull/3157
* common: apply two stage copy to aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3145
* dec: adjust seqSymbol load on aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3141
* Fix big endian ARM NEON path by @danlark1 in https://github.com/facebook/zstd/pull/3160
* [contrib] largeNbDicts bugfix + improvements by @embg in https://github.com/facebook/zstd/pull/3161
* display a warning message when using C90 clock_t by @Cyan4973 in https://github.com/facebook/zstd/pull/3166
* remove explicit standard setting from cmake script by @Cyan4973 in https://github.com/facebook/zstd/pull/3167
* removed gnu99 statement from meson recipe by @Cyan4973 in https://github.com/facebook/zstd/pull/3170
* "Short cache" optimization for level 1-4 DMS (+5-30% compression speed) by @embg in https://github.com/facebook/zstd/pull/3152
* Streaming decompression can detect incorrect header ID sooner by @Cyan4973 in https://github.com/facebook/zstd/pull/3175
* Add prefetchCDictTables CCtxParam (+10-20% cold dict compression speed) by @embg in https://github.com/facebook/zstd/pull/3177
* Fix ZSTD_BUILD_TESTS=ON with MSVC by @nocnokneo in https://github.com/facebook/zstd/pull/3180
* zstd -lv <file> to show dictID by @htnhan in https://github.com/facebook/zstd/pull/3184
* Intial commit to address 3090. Added support to decompress empty block. by @udayanbapat in https://github.com/facebook/zstd/pull/3118
* [largeNbDicts] Second try at fixing decompression segfault to always create compressInstructions by @zhuhan0 in https://github.com/facebook/zstd/pull/3209
* Clarify benchmark chunking docstring by @embg in https://github.com/facebook/zstd/pull/3197
* decomp: add prefetch for matched seq on aarch64 by @JunHe77 in https://github.com/facebook/zstd/pull/3164
* lib: add hint to generate more pipeline friendly code by @JunHe77 in https://github.com/facebook/zstd/pull/3138
* [AIX] Fix Compiler Flags and Bugs on AIX to Pass All Tests by @qiongsiwu in https://github.com/facebook/zstd/pull/3219
* zlibWrapper: Update for zlib 1.2.12 by @orbea in https://github.com/facebook/zstd/pull/3217
* Fix small file passthrough by @cgbur in https://github.com/facebook/zstd/pull/3215
* Add warning when multi-thread decompression is requested by @tomcwang in https://github.com/facebook/zstd/pull/3208
* stdin + multiple file fixes by @yoniko in https://github.com/facebook/zstd/pull/3222
* [AIX] Fixing hash4Ptr for Big Endian Systems by @qiongsiwu in https://github.com/facebook/zstd/pull/3227
* Disallow empty string as argument for --output-dir-flat and --output-dir-mirror by @embg in https://github.com/facebook/zstd/pull/3220
* Deprecate ZSTD_getDecompressedSize() by @terrelln in https://github.com/facebook/zstd/pull/3225
* [T124890272] Mark 2 Obsolete Functions(ZSTD_copy*Ctx) Deprecated in Zstd by @mileshu in https://github.com/facebook/zstd/pull/3196
* fileio_types.h : avoid dependency on mem.h by @Cyan4973 in https://github.com/facebook/zstd/pull/3232
* fixed: verbose output prints wrong value for `wlog` when doing `--long` by @zengyijing in https://github.com/facebook/zstd/pull/3226
* Add explicit --pass-through flag and default to enabled for *cat by @terrelln in https://github.com/facebook/zstd/pull/3223
* Document pass-through behavior by @cgbur in https://github.com/facebook/zstd/pull/3242
* restore combine.sh bash performance while still sticking to POSIX by @wahern in https://github.com/facebook/zstd/pull/3241
* Benchmark program for sequence compression API by @embg in https://github.com/facebook/zstd/pull/3257
* streamline `make clean` list maintenance by adding a `CLEAN` variable by @Cyan4973 in https://github.com/facebook/zstd/pull/3256
* drop `-E` flag in `sed` by @haampie in https://github.com/facebook/zstd/pull/3245
* compress:check more bytes to reduce `ZSTD_count` call by @JunHe77 in https://github.com/facebook/zstd/pull/3199
* build(cmake): improve pkg-config generation by @Tachi107 in https://github.com/facebook/zstd/pull/3252
* Fix for `zstd` CLI accepts bogus values for numeric parameters by @ctkhanhly in https://github.com/facebook/zstd/pull/3268
* ci: test pkg-config file by @Tachi107 in https://github.com/facebook/zstd/pull/3267
* Move ZSTD_DEPRECATED before ZSTDLIB_API/ZSTDLIB_STATIC_API for `clang` by @MaskRay in https://github.com/facebook/zstd/pull/3273
* Enable OpenSSF Scorecard Action by @felixhandte in https://github.com/facebook/zstd/pull/3277
* fixed zstd-pgo target for GCC by @ilyakurdyukov in https://github.com/facebook/zstd/pull/3281
* Cleaner threadPool initialization by @Cyan4973 in https://github.com/facebook/zstd/pull/3288
* Make fuzzing work without ZSTD_MULTITHREAD by @danlark1 in https://github.com/facebook/zstd/pull/3291
* Optimal huf depth by @daniellerozenblit in https://github.com/facebook/zstd/pull/3285
* Make ZSTD_getDictID_fromDDict() Read DictID from DDict by @felixhandte in https://github.com/facebook/zstd/pull/3290
* [contrib][linux-kernel] Generate SPDX license identifiers by @ojeda in https://github.com/facebook/zstd/pull/3294
* [lazy] Use switch instead of indirect function calls, improving compression speed by @terrelln in https://github.com/facebook/zstd/pull/3295
* [linux] Add zstd_common module by @terrelln in https://github.com/facebook/zstd/pull/3292
* Complete migration of ZSTD_c_enableLongDistanceMatching to ZSTD_paramSwitch_e framework by @embg in https://github.com/facebook/zstd/pull/3321
* meson: get version up front by @eli-schwartz in https://github.com/facebook/zstd/pull/3327
* Fix for MSVC C4267 warning on ARM64 (which becomes error C2220 with /WX) by @cwoffenden in https://github.com/facebook/zstd/pull/3320
* Enable dependabot for automatic GitHub Actions updates by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3284
* Print checksum value for single frame files in cli with -v -l options by @Cyan4973 in https://github.com/facebook/zstd/pull/3332
* Fix window size resizing optimization for edge case by @daniellerozenblit in https://github.com/facebook/zstd/pull/3345
* [linux-kernel] Fix stack detection for newer gcc by @terrelln in https://github.com/facebook/zstd/pull/3348
* Reserve two fields in ZSTD_frameHeader by @embg in https://github.com/facebook/zstd/pull/3349
* Fix seekable format for empty string by @daniellerozenblit in https://github.com/facebook/zstd/pull/3346
* meson: make backtrace dependency on execinfo for musl libc compatibility by @neheb in https://github.com/facebook/zstd/pull/3276
* Refactor progress bar & summary line logic by @terrelln in https://github.com/facebook/zstd/pull/2984
* Use `__attribute__((aligned(1)))` for unaligned access by @Hello71 in https://github.com/facebook/zstd/pull/2881
* Separate parameter adaption from display update rate by @terrelln in https://github.com/facebook/zstd/pull/3354
* [decompress] Fix UB nullptr addition & improve fuzzer by @terrelln in https://github.com/facebook/zstd/pull/3356
* [legacy] Simplify legacy codebase by removing esoteric memory accesses and only use memcpy by @terrelln in https://github.com/facebook/zstd/pull/3355
* Fix corruption that rarely occurs in 32-bit mode with wlog=25 by @terrelln in https://github.com/facebook/zstd/pull/3361
* meson: partial fix for building pzstd on MSVC by @eli-schwartz in https://github.com/facebook/zstd/pull/3357
* [CI] Re-enable versions-test by @terrelln in https://github.com/facebook/zstd/pull/3371
* [api][visibility] Make the visibility macros more consistent by @terrelln in https://github.com/facebook/zstd/pull/3363
* [build] Fix ZSTD_LIB_MINIFY build option by @terrelln in https://github.com/facebook/zstd/pull/3366
* [zdict] Fix static linking only include guards by @terrelln in https://github.com/facebook/zstd/pull/3372
* check potential overflow of compressBound() by @Cyan4973 in https://github.com/facebook/zstd/pull/3362
* decompressBound tests and fix by @Cyan4973 in https://github.com/facebook/zstd/pull/3373
* Meson test fixups by @eli-schwartz in https://github.com/facebook/zstd/pull/3120
* [pzstd] Fixes for Windows build by @terrelln in https://github.com/facebook/zstd/pull/3380
* Windows MT layer bug fixes by @yoniko in https://github.com/facebook/zstd/pull/3364
* Update Copyright Comments by @felixhandte in https://github.com/facebook/zstd/pull/3173
* [docs] Clarify dictionary loading documentation by @terrelln in https://github.com/facebook/zstd/pull/3381
* [build][cmake] Fix cmake with custom assembler by @terrelln in https://github.com/facebook/zstd/pull/3382
* Pin actions/checkout Dependency to Specific Commit Hash by @felixhandte in https://github.com/facebook/zstd/pull/3384
* Improve help/usage (`-h`, `-H`) formatting by @jonpalmisc in https://github.com/facebook/zstd/pull/3385
* [cmake] Add noexecstack to compiler/linker flags by @terrelln in https://github.com/facebook/zstd/pull/3392
* Fix `-Wdocumentation` by @terrelln in https://github.com/facebook/zstd/pull/3393
* Support decompression of compressed blocks of size ZSTD_BLOCKSIZE_MAX by @Cyan4973 in https://github.com/facebook/zstd/pull/3399
* spec update : require minimum nb of literals for 4-streams mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3398
* External matchfinder API by @embg in https://github.com/facebook/zstd/pull/3333
* New `ZSTD_CCtx_setCParams()` entry point, to set all parameters defined in a `ZSTD_compressionParameters` structure by @Cyan4973 in https://github.com/facebook/zstd/pull/3403
* Move deprecated annotation before static to allow C++ compilation for clang by @danlark1 in https://github.com/facebook/zstd/pull/3400
* Optimal huff depth speed improvements by @daniellerozenblit in https://github.com/facebook/zstd/pull/3302
* improve compression ratio of small alphabets by @Cyan4973 in https://github.com/facebook/zstd/pull/3391
* Fix fuzzing with ZSTD_MULTITHREAD by @danlark1 in https://github.com/facebook/zstd/pull/3417
* minor refactoring for timefn by @Cyan4973 in https://github.com/facebook/zstd/pull/3413
* Add support for in-place decompression by @terrelln in https://github.com/facebook/zstd/pull/3421
* fix when nb of literals is very small by @Cyan4973 in https://github.com/facebook/zstd/pull/3419
* Deprecate advanced streaming functions by @embg in https://github.com/facebook/zstd/pull/3408
* Disable Custom ASAN/MSAN Poisoning on MinGW Builds by @felixhandte in https://github.com/facebook/zstd/pull/3424
* [tests] Fix version test determinism by @terrelln in https://github.com/facebook/zstd/pull/3422
* Refactor `timefn` unit, restore support for `clock_gettime()` by @Cyan4973 in https://github.com/facebook/zstd/pull/3423
* Fuzz on maxBlockSize by @daniellerozenblit in https://github.com/facebook/zstd/pull/3418
* Fuzz the External Matchfinder API by @embg in https://github.com/facebook/zstd/pull/3437
* Cap hashLog & chainLog to ensure that we only use 32 bits of hash by @terrelln in https://github.com/facebook/zstd/pull/3438
* [versions-test] Work around bug in dictionary builder for older versions by @terrelln in https://github.com/facebook/zstd/pull/3436
* added c89 build test to CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3435
* added cygwin tests to Github Actions by @Cyan4973 in https://github.com/facebook/zstd/pull/3431
* Huffman refactor by @terrelln in https://github.com/facebook/zstd/pull/3434
* Fix bufferless API with attached dictionary by @terrelln in https://github.com/facebook/zstd/pull/3441
* Test PGO Builds by @felixhandte in https://github.com/facebook/zstd/pull/3442
* Fix CLI Handling of Permissions and Ownership by @felixhandte in https://github.com/facebook/zstd/pull/3432
* Fix -Wstringop-overflow warning by @terrelln in https://github.com/facebook/zstd/pull/3440
* refactor : --rm ignored with stdout by @Cyan4973 in https://github.com/facebook/zstd/pull/3443
* Fix sequence validation and seqStore bounds check by @daniellerozenblit in https://github.com/facebook/zstd/pull/3439
* Fix ZSTD_estimate* and ZSTD_initCStream() docs by @embg in https://github.com/facebook/zstd/pull/3448
* Fix 32-bit build errors in zstd seekable format by @daniellerozenblit in https://github.com/facebook/zstd/pull/3452
* Fuzz large offsets through sequence compression api by @daniellerozenblit in https://github.com/facebook/zstd/pull/3447
* [huf] Add generic C versions of the fast decoding loops by @terrelln in https://github.com/facebook/zstd/pull/3449
* Provide more accurate error codes for busy-loop scenarios by @Cyan4973 in https://github.com/facebook/zstd/pull/3455
* disable --rm on -o command by @Cyan4973 in https://github.com/facebook/zstd/pull/3450
* [Bugfix] CLI row hash flags set the wrong values by @yoniko in https://github.com/facebook/zstd/pull/3457
* [huf] Fix bug in fast C decoders by @terrelln in https://github.com/facebook/zstd/pull/3459
* Disable status updates when `stderr` is not the console by @Cyan4973 in https://github.com/facebook/zstd/pull/3458
* fix long offset resolution by @daniellerozenblit in https://github.com/facebook/zstd/pull/3460
* Simplify 32-bit long offsets decoding logic by @terrelln in https://github.com/facebook/zstd/pull/3467
## New Contributors
* @WojciechMula made their first contribution in https://github.com/facebook/zstd/pull/3013
* @trixirt made their first contribution in https://github.com/facebook/zstd/pull/3026
* @brailovich made their first contribution in https://github.com/facebook/zstd/pull/3027
* @u1f35c made their first contribution in https://github.com/facebook/zstd/pull/3042
* @shadchin made their first contribution in https://github.com/facebook/zstd/pull/3050
* @ooosssososos made their first contribution in https://github.com/facebook/zstd/pull/3054
* @TocarIP made their first contribution in https://github.com/facebook/zstd/pull/3075
* @xry111 made their first contribution in https://github.com/facebook/zstd/pull/3084
* @niamster made their first contribution in https://github.com/facebook/zstd/pull/3079
* @dirkmueller made their first contribution in https://github.com/facebook/zstd/pull/3059
* @cyberknight777 made their first contribution in https://github.com/facebook/zstd/pull/3088
* @dpelle made their first contribution in https://github.com/facebook/zstd/pull/3095
* @paulmenzel made their first contribution in https://github.com/facebook/zstd/pull/3108
* @cuishuang made their first contribution in https://github.com/facebook/zstd/pull/3117
* @averred made their first contribution in https://github.com/facebook/zstd/pull/3135
* @JunHe77 made their first contribution in https://github.com/facebook/zstd/pull/3145
* @htnhan made their first contribution in https://github.com/facebook/zstd/pull/3184
* @udayanbapat made their first contribution in https://github.com/facebook/zstd/pull/3118
* @zhuhan0 made their first contribution in https://github.com/facebook/zstd/pull/3205
* @mgord9518 made their first contribution in https://github.com/facebook/zstd/pull/3218
* @qiongsiwu made their first contribution in https://github.com/facebook/zstd/pull/3219
* @orbea made their first contribution in https://github.com/facebook/zstd/pull/3217
* @cgbur made their first contribution in https://github.com/facebook/zstd/pull/3215
* @tomcwang made their first contribution in https://github.com/facebook/zstd/pull/3208
* @mileshu made their first contribution in https://github.com/facebook/zstd/pull/3196
* @zengyijing made their first contribution in https://github.com/facebook/zstd/pull/3226
* @grossws made their first contribution in https://github.com/facebook/zstd/pull/3230
* @wahern made their first contribution in https://github.com/facebook/zstd/pull/3241
* @daniellerozenblit made their first contribution in https://github.com/facebook/zstd/pull/3258
* @DimitriPapadopoulos made their first contribution in https://github.com/facebook/zstd/pull/3259
* @sashashura made their first contribution in https://github.com/facebook/zstd/pull/3264
* @haampie made their first contribution in https://github.com/facebook/zstd/pull/3247
* @Tachi107 made their first contribution in https://github.com/facebook/zstd/pull/3252
* @ctkhanhly made their first contribution in https://github.com/facebook/zstd/pull/3268
* @MaskRay made their first contribution in https://github.com/facebook/zstd/pull/3273
* @ilyakurdyukov made their first contribution in https://github.com/facebook/zstd/pull/3281
* @ojeda made their first contribution in https://github.com/facebook/zstd/pull/3294
* @GermanAizek made their first contribution in https://github.com/facebook/zstd/pull/3304
* @joycebrum made their first contribution in https://github.com/facebook/zstd/pull/3309
* @yiyuaner made their first contribution in https://github.com/facebook/zstd/pull/3300
* @nmoinvaz made their first contribution in https://github.com/facebook/zstd/pull/3289
* @jonpalmisc made their first contribution in https://github.com/facebook/zstd/pull/3385
**Full Automated Changelog**: https://github.com/facebook/zstd/compare/v1.5.2...v1.5.42023-02-10T00:55:48+00:00zstd v1.5.5zstd v1.5.52023-04-04T22:20:32+00:00# Zstandard v1.5.5 Release Note
This is a quick fix release. The primary focus is to correct a rare corruption bug in high compression mode, detected by @danlark1 . The probability to generate such a scenario by random chance is extremely low. It evaded months of continuous fuzzer tests, due to the number and complexity of simultaneous conditions required to trigger it. Nevertheless, @danlark1 from Google shepherds such a humongous amount of data that he managed to detect a reproduction case (corruptions are detected thanks to the checksum), making it possible for @terrelln to investigate and fix the bug. Thanks !
While the probability might be very small, corruption issues are nonetheless very serious, so an update to this version is highly recommended, especially if you employ high compression modes (levels 16+).
When the issue was detected, there were a number of other improvements and minor fixes already in the making, hence they are also present in this release. Let’s detail the main ones.
### Improved memory usage and speed for the `--patch-from` mode
`V1.5.5` introduces memory-mapped dictionaries, by @daniellerozenblit, for both posix [#3486](https://github.com/facebook/zstd/pull/3486) and windows [#3557](https://github.com/facebook/zstd/pull/3557).
This feature allows `zstd` to memory-map large dictionaries, rather than requiring to load them into memory. This can make a pretty big difference for memory-constrained environments operating patches for large data sets.
It's mostly visible under memory pressure, since `mmap` will be able to release less-used memory and continue working.
But even when memory is plentiful, there are still measurable memory benefits, as shown in the graph below, especially when the reference turns out to be not completely relevant for the patch.

This feature is automatically enabled for `--patch-from` compression/decompression when the dictionary is larger than the user-set memory limit. It can also be manually enabled/disabled using `--mmap-dict` or `--no-mmap-dict` respectively.
Additionally, @daniellerozenblit introduces significant speed improvements for `--patch-from`.
An `I/O` optimization in [#3486](https://github.com/facebook/zstd/pull/3486) greatly improves `--patch-from` decompression speed on Linux, typically by `+50%` on large files (~1GB).

Compression speed is also taken care of, with a dictionary-indexing speed optimization introduced in [#3545](https://github.com/facebook/zstd/pull/3545). It wildly accelerates `--patch-from` compression, typically doubling speed on large files (~1GB), sometimes even more depending on exact scenario.

This speed improvement comes at a slight regression in compression ratio, and is therefore enabled only on non-ultra compression strategies.
### Speed improvements of middle-level compression for specific scenarios
The row-hash match finder introduced in version 1.5.0 for levels 5-12 has been improved in version 1.5.5, enhancing its speed in specific corner-case scenarios.
The first optimization ([#3426](https://github.com/facebook/zstd/pull/3426)) accelerates streaming compression using `ZSTD_compressStream` on small inputs by removing an expensive table initialization step. This results in remarkable speed increases for very small inputs.
The following scenario measures compression speed of `ZSTD_compressStream` at level 9 for different sample sizes on a linux platform running an i7-9700k cpu.
| sample size | `v1.5.4` (MB/s) | `v1.5.5` (MB/s) | improvement |
| --- | ----:| ---:| --- |
| 100 | 1.4 | 44.8 | x32
| 200 | 2.8 | 44.9 | x16
| 500 | 6.5 | 60.0 | x9.2
| 1K | 12.4 | 70.0 | x5.6
| 2K | 25.0 | 111.3 | x4.4
| 4K | 44.4 | 139.4 | x3.2
| ... | ... | ... |
| 1M | 97.5 | 99.4 | +2%
The second optimization ([#3552](https://github.com/facebook/zstd/issues/3552)) speeds up compression of incompressible data by a large multiplier. This is achieved by increasing the step size and reducing the frequency of matching when no matches are found, with negligible impact on the compression ratio. It makes mid-level compression essentially inexpensive when processing incompressible data, typically, already compressed data (note: this was already the case for fast compression levels).
The following scenario measures compression speed of `ZSTD_compress` compiled with `gcc-9` for a ~10MB incompressible sample on a linux platform running an i7-9700k cpu.
| level | `v1.5.4` (MB/s) | `v1.5.5` (MB/s) | improvement |
| --- | ----:| ---:| --- |
| 3 | 3500 | 3500 | not a row-hash level (control)
| 5 | 400 | 2500 | x6.2
| 7 | 380 | 2200 | x5.8
| 9 | 176 | 1880 | x10
| 11 | 67 | 1130 | x16
| 13 | 89 | 89 | not a row-hash level (control)
### Miscellaneous
There are other welcome speed improvements in this package.
For example, @felixhandte managed to increase processing speed of small files by carefully reducing the nb of system calls (#3479). This can easily translate into +10% speed when processing a lot of small files in batch.
The Seekable format received a bit of care. It's now much faster when splitting data into very small blocks (#3544). In an extreme scenario reported by @P-E-Meunier, it improves processing speed by x90. Even for more "common" settings, such as using 4KB blocks on some "normally" compressible data like `enwik`, it still provides a healthy x2 processing speed benefit. Moreover, @dloidolt merged an optimization that reduces the nb of `I/O` `seek()` events during reads (decompression), which is also beneficial for speed.
The release is not limited to speed improvements, several loose ends and corner cases were also fixed in this release. For a more detailed list of changes, please take a look at the changelog.
## Change Log
- fix: fix rare corruption bug affecting the high compression mode, reported by @danlark1 (#3517, @terrelln)
- perf: improve mid-level compression speed (#3529, #3533, #3543, @yoniko and #3552, @terrelln)
- lib: deprecated bufferless block-level API (#3534) by @terrelln
- cli: `mmap` large dictionaries to save memory, by @daniellerozenblit
- cli: improve speed of `--patch-from` mode (~+50%) (#3545) by @daniellerozenblit
- cli: improve i/o speed (~+10%) when processing lots of small files (#3479) by @felixhandte
- cli: `zstd` no longer crashes when requested to write into write-protected directory (#3541) by @felixhandte
- cli: fix decompression into block device using `-o` (#3584, @Cyan4973) reported by @georgmu
- build: fix zstd CLI compiled with lzma support but not zlib support (#3494) by @Hello71
- build: fix `cmake` does no longer require 3.18 as minimum version (#3510) by @kou
- build: fix MSVC+ClangCL linking issue (#3569) by @tru
- build: fix zstd-dll, version of zstd CLI that links to the dynamic library (#3496) by @yoniko
- build: fix MSVC warnings (#3495) by @embg
- doc: updated zstd specification to clarify corner cases, by @Cyan4973
- doc: document how to create fat binaries for macos (#3568) by @rickmark
- misc: improve seekable format ingestion speed (~+100%) for very small chunk sizes (#3544) by @Cyan4973
- misc: `tests/fullbench` can benchmark multiple files (#3516) by @dloidolt
## Full change list (auto-generated)
* Fix all MSVC warnings by @embg in https://github.com/facebook/zstd/pull/3495
* Fix zstd-dll build missing dependencies by @yoniko in https://github.com/facebook/zstd/pull/3496
* Bump github/codeql-action from 2.2.1 to 2.2.4 by @dependabot in https://github.com/facebook/zstd/pull/3503
* Github Action to generate Win64 artifacts by @Cyan4973 in https://github.com/facebook/zstd/pull/3491
* Use correct types in LZMA comp/decomp by @Hello71 in https://github.com/facebook/zstd/pull/3497
* Make Github workflows permissions read-only by default by @yoniko in https://github.com/facebook/zstd/pull/3488
* CI Workflow for external compressors dependencies by @yoniko in https://github.com/facebook/zstd/pull/3505
* Fix cli-tests issues by @daniellerozenblit in https://github.com/facebook/zstd/pull/3509
* Fix Permissions on Publish Release Artifacts Job by @felixhandte in https://github.com/facebook/zstd/pull/3511
* Use `f`-variants of `chmod()` and `chown()` by @felixhandte in https://github.com/facebook/zstd/pull/3479
* Don't require CMake 3.18 or later by @kou in https://github.com/facebook/zstd/pull/3510
* meson: always build the zstd binary when tests are enabled by @eli-schwartz in https://github.com/facebook/zstd/pull/3490
* [bug-fix] Fix rare corruption bug affecting the block splitter by @terrelln in https://github.com/facebook/zstd/pull/3517
* Clarify zstd specification for Huffman blocks by @Cyan4973 in https://github.com/facebook/zstd/pull/3514
* Fix typos found by codespell by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3513
* Bump github/codeql-action from 2.2.4 to 2.2.5 by @dependabot in https://github.com/facebook/zstd/pull/3518
* fullbench with two files by @dloidolt in https://github.com/facebook/zstd/pull/3516
* Add initialization of clevel to static cdict (#3525) by @yoniko in https://github.com/facebook/zstd/pull/3527
* [linux-kernel] Fix assert definition by @terrelln in https://github.com/facebook/zstd/pull/3532
* Add ZSTD_set{C,F,}Params() helper functions by @terrelln in https://github.com/facebook/zstd/pull/3530
* Clarify dstCapacity requirements by @terrelln in https://github.com/facebook/zstd/pull/3531
* Mmap large dictionaries in patch-from mode by @daniellerozenblit in https://github.com/facebook/zstd/pull/3486
* added clarifications for sizes of compressed huffman blocks and streams. by @Cyan4973 in https://github.com/facebook/zstd/pull/3538
* Simplify benchmark unit invocation API from CLI by @Cyan4973 in https://github.com/facebook/zstd/pull/3526
* Avoid Segfault Caused by Calling `setvbuf()` on Null File Pointer by @felixhandte in https://github.com/facebook/zstd/pull/3541
* Pin Moar Action Dependencies by @felixhandte in https://github.com/facebook/zstd/pull/3542
* Improved seekable format ingestion speed for small frame size by @Cyan4973 in https://github.com/facebook/zstd/pull/3544
* Reduce RowHash's tag space size by x2 by @yoniko in https://github.com/facebook/zstd/pull/3543
* [Bugfix] row hash tries to match position 0 by @yoniko in https://github.com/facebook/zstd/pull/3548
* Bump github/codeql-action from 2.2.5 to 2.2.6 by @dependabot in https://github.com/facebook/zstd/pull/3549
* Add init once memory (#3528) by @yoniko in https://github.com/facebook/zstd/pull/3529
* Introduce salt into row hash (#3528 part 2) by @yoniko in https://github.com/facebook/zstd/pull/3533
* added documentation for the seekable format by @Cyan4973 in https://github.com/facebook/zstd/pull/3547
* patch-from speed optimization by @daniellerozenblit in https://github.com/facebook/zstd/pull/3545
* Deprecated bufferless and block level APIs by @terrelln in https://github.com/facebook/zstd/pull/3534
* added documentation for LDM + dictionary compatibility by @Cyan4973 in https://github.com/facebook/zstd/pull/3553
* Fix a bug in the CLI tests newline processing, then simplify it further by @ppentchev in https://github.com/facebook/zstd/pull/3559
* [lazy] Skip over incompressible data by @terrelln in https://github.com/facebook/zstd/pull/3552
* Fix patch-from speed optimization by @daniellerozenblit in https://github.com/facebook/zstd/pull/3556
* Bump actions/checkout from 3.3.0 to 3.5.0 by @dependabot in https://github.com/facebook/zstd/pull/3572
* [easy] minor doc update for --rsyncable by @Cyan4973 in https://github.com/facebook/zstd/pull/3570
* [contrib/pzstd] Select `-std=c++11` When Default is Older by @felixhandte in https://github.com/facebook/zstd/pull/3574
* Add instructions for building Universal2 on macOS via CMake by @rickmark in https://github.com/facebook/zstd/pull/3568
* Provide an interface for fuzzing sequence producer plugins by @embg in https://github.com/facebook/zstd/pull/3551
* mmap for windows by @daniellerozenblit in https://github.com/facebook/zstd/pull/3557
* Bump github/codeql-action from 2.2.6 to 2.2.8 by @dependabot in https://github.com/facebook/zstd/pull/3573
* Disable linker flag detection on MSVC/ClangCL. by @tru in https://github.com/facebook/zstd/pull/3569
* Couple tweaks to improve decompression speed with clang PGO compilation by @zhuhan0 in https://github.com/facebook/zstd/pull/3576
* Increase tests timeout by @dvoropaev in https://github.com/facebook/zstd/pull/3540
* added a Clang-CL Windows test to CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3579
* Seekable format read optimization by @Cyan4973 in https://github.com/facebook/zstd/pull/3581
* Check that `dest` is valid for decompression by @daniellerozenblit in https://github.com/facebook/zstd/pull/3555
* fix decompression with -o writing into a block device by @Cyan4973 in https://github.com/facebook/zstd/pull/3584
* updated version number to v1.5.5 by @Cyan4973 in https://github.com/facebook/zstd/pull/3577
## New Contributors
* @kou made their first contribution in https://github.com/facebook/zstd/pull/3510
* @dloidolt made their first contribution in https://github.com/facebook/zstd/pull/3516
* @ppentchev made their first contribution in https://github.com/facebook/zstd/pull/3559
* @rickmark made their first contribution in https://github.com/facebook/zstd/pull/3568
* @dvoropaev made their first contribution in https://github.com/facebook/zstd/pull/3540
**Full Changelog**: https://github.com/facebook/zstd/compare/v1.5.4...v1.5.52023-04-04T22:20:32+00:00